update saasr egs and m2met docs
| | |
|---|
| | | ## Baseline results |
|---|
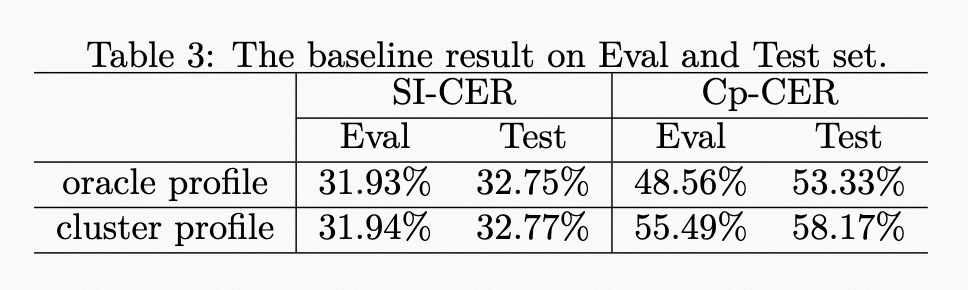
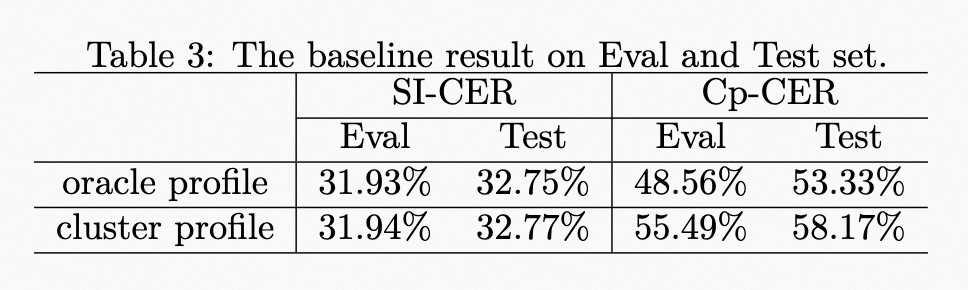
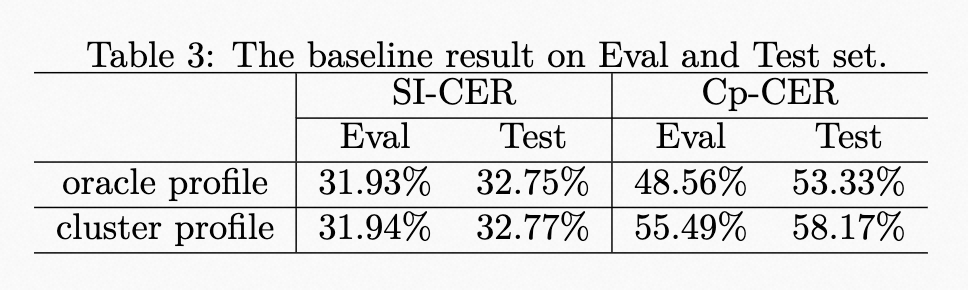
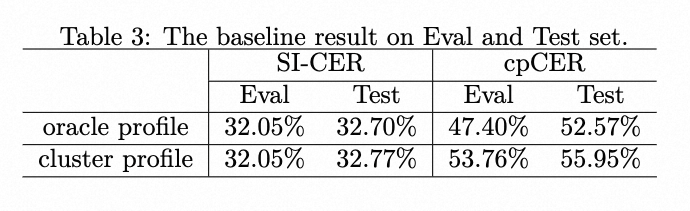
| | | The results of the baseline system are shown in Table 3. The speaker profile adopts the oracle speaker embedding during training. However, due to the lack of oracle speaker label during evaluation, the speaker profile provided by an additional spectral clustering is used. Meanwhile, the results of using the oracle speaker profile on Eval and Test Set are also provided to show the impact of speaker profile accuracy. |
|---|
| | | |
|---|
| | |  |
|---|
| | |  |
|---|
| | |
|---|
| | | |
|---|
| | | ## Timeline(AOE Time) |
|---|
| | | - $ April~29, 2023: $ Challenge and registration open. |
|---|
| | | - $ May~8, 2023: $ Baseline release. |
|---|
| | | - $ May~15, 2023: $ Registration deadline, the due date for participants to join the Challenge. |
|---|
| | | - $ June~9, 2023: $ Test data release and leaderboard open. |
|---|
| | | - $ June~13, 2023: $ Final submission deadline and leaderboar close. |
|---|
| | | - $ June~19, 2023: $ Evaluation result and ranking release. |
|---|
| | | - $ May~11, 2023: $ Baseline release. |
|---|
| | | - $ May~22, 2023: $ Registration deadline, the due date for participants to join the Challenge. |
|---|
| | | - $ June~16, 2023: $ Test data release and leaderboard open. |
|---|
| | | - $ June~20, 2023: $ Final submission deadline and leaderboar close. |
|---|
| | | - $ June~26, 2023: $ Evaluation result and ranking release. |
|---|
| | | - $ July~3, 2023: $ Deadline for paper submission. |
|---|
| | | - $ July~10, 2023: $ Deadline for final paper submission. |
|---|
| | | - $ December~12\ to\ 16, 2023: $ ASRU Workshop and challenge Session |
|---|
| | | - $ December~12\ to\ 16, 2023: $ ASRU Workshop and Challenge Session. |
|---|
| | | |
|---|
| | | ## Guidelines |
|---|
| | | |
|---|
| | |
|---|
| | | <section id="baseline-results"> |
|---|
| | | <h2>Baseline results<a class="headerlink" href="#baseline-results" title="Permalink to this heading">¶</a></h2> |
|---|
| | | <p>The results of the baseline system are shown in Table 3. The speaker profile adopts the oracle speaker embedding during training. However, due to the lack of oracle speaker label during evaluation, the speaker profile provided by an additional spectral clustering is used. Meanwhile, the results of using the oracle speaker profile on Eval and Test Set are also provided to show the impact of speaker profile accuracy.</p> |
|---|
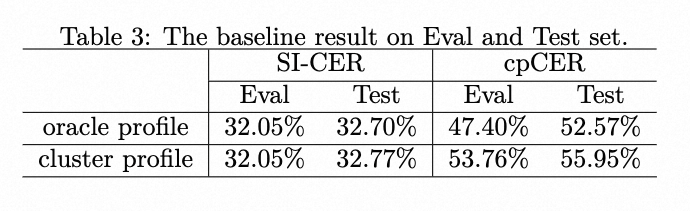
| | | <p><img alt="baseline result" src="_images/baseline_result.png" /></p> |
|---|
| | | <p><img alt="baseline_result" src="_images/baseline_result.png" /></p> |
|---|
| | | </section> |
|---|
| | | </section> |
|---|
| | | |
|---|
| | |
|---|
| | | <h2>Timeline(AOE Time)<a class="headerlink" href="#timeline-aoe-time" title="Permalink to this heading">¶</a></h2> |
|---|
| | | <ul class="simple"> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( April~29, 2023: \)</span> Challenge and registration open.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( May~8, 2023: \)</span> Baseline release.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( May~15, 2023: \)</span> Registration deadline, the due date for participants to join the Challenge.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~9, 2023: \)</span> Test data release and leaderboard open.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~13, 2023: \)</span> Final submission deadline and leaderboar close.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~19, 2023: \)</span> Evaluation result and ranking release.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( May~11, 2023: \)</span> Baseline release.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( May~22, 2023: \)</span> Registration deadline, the due date for participants to join the Challenge.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~16, 2023: \)</span> Test data release and leaderboard open.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~20, 2023: \)</span> Final submission deadline and leaderboar close.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~26, 2023: \)</span> Evaluation result and ranking release.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( July~3, 2023: \)</span> Deadline for paper submission.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( July~10, 2023: \)</span> Deadline for final paper submission.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( December~12\ to\ 16, 2023: \)</span> ASRU Workshop and challenge Session</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( December~12\ to\ 16, 2023: \)</span> ASRU Workshop and Challenge Session.</p></li> |
|---|
| | | </ul> |
|---|
| | | </section> |
|---|
| | | <section id="guidelines"> |
|---|
| | |
|---|
| | | ## Baseline results |
|---|
| | | The results of the baseline system are shown in Table 3. The speaker profile adopts the oracle speaker embedding during training. However, due to the lack of oracle speaker label during evaluation, the speaker profile provided by an additional spectral clustering is used. Meanwhile, the results of using the oracle speaker profile on Eval and Test Set are also provided to show the impact of speaker profile accuracy. |
|---|
| | | |
|---|
| | |  |
|---|
| | |  |
|---|
| | |
|---|
| | | |
|---|
| | | ## Timeline(AOE Time) |
|---|
| | | - $ April~29, 2023: $ Challenge and registration open. |
|---|
| | | - $ May~8, 2023: $ Baseline release. |
|---|
| | | - $ May~15, 2023: $ Registration deadline, the due date for participants to join the Challenge. |
|---|
| | | - $ June~9, 2023: $ Test data release and leaderboard open. |
|---|
| | | - $ June~13, 2023: $ Final submission deadline and leaderboar close. |
|---|
| | | - $ June~19, 2023: $ Evaluation result and ranking release. |
|---|
| | | - $ May~11, 2023: $ Baseline release. |
|---|
| | | - $ May~22, 2023: $ Registration deadline, the due date for participants to join the Challenge. |
|---|
| | | - $ June~16, 2023: $ Test data release and leaderboard open. |
|---|
| | | - $ June~20, 2023: $ Final submission deadline and leaderboar close. |
|---|
| | | - $ June~26, 2023: $ Evaluation result and ranking release. |
|---|
| | | - $ July~3, 2023: $ Deadline for paper submission. |
|---|
| | | - $ July~10, 2023: $ Deadline for final paper submission. |
|---|
| | | - $ December~12\ to\ 16, 2023: $ ASRU Workshop and challenge Session |
|---|
| | | - $ December~12\ to\ 16, 2023: $ ASRU Workshop and Challenge Session. |
|---|
| | | |
|---|
| | | ## Guidelines |
|---|
| | | |
|---|
| | |
|---|
| | | Search.setIndex({"docnames": ["Baseline", "Contact", "Dataset", "Introduction", "Organizers", "Rules", "Track_setting_and_evaluation", "index"], "filenames": ["Baseline.md", "Contact.md", "Dataset.md", "Introduction.md", "Organizers.md", "Rules.md", "Track_setting_and_evaluation.md", "index.rst"], "titles": ["Baseline", "Contact", "Datasets", "Introduction", "Organizers", "Rules", "Track & Evaluation", "ASRU 2023 MULTI-CHANNEL MULTI-PARTY MEETING TRANSCRIPTION CHALLENGE 2.0 (M2MeT2.0)"], "terms": {"we": [0, 2, 3, 7], "releas": [0, 2, 3, 6], "an": [0, 2, 3, 6], "e2": 0, "sa": 0, "asr": [0, 3, 7], "conduct": [0, 2], "funasr": 0, "time": [0, 6], "accord": [0, 3], "timelin": [0, 2], "The": [0, 2, 3, 5, 6], "model": [0, 2, 3, 5, 6], "architectur": 0, "i": [0, 2, 3, 5], "shown": [0, 2], "figur": [0, 6], "3": [0, 2, 3], "speakerencod": 0, "initi": 0, "pre": [0, 6], "train": [0, 3, 5, 7], "speaker": [0, 2, 3, 7], "verif": 0, "from": [0, 2, 3, 5, 6], "modelscop": [0, 6], "thi": [0, 3, 5, 6], "also": [0, 2, 3, 6], "us": [0, 2, 5, 6], "extract": 0, "embed": 0, "profil": 0, "To": [0, 2, 3, 7], "run": 0, "first": 0, "you": [0, 1], "need": 0, "instal": 0, "There": [0, 2], "ar": [0, 2, 3, 5, 6, 7], "two": [0, 3, 5, 7], "startup": 0, "script": [0, 2], "sh": 0, "evalu": [0, 2, 3, 7], "old": 0, "eval": [0, 2, 5, 6], "test": [0, 2, 3, 5, 6], "set": [0, 2, 3, 5, 6], "run_m2met_2023_inf": 0, "infer": 0, "new": [0, 2, 3, 6], "multi": [0, 3, 6], "channel": [0, 3], "parti": [0, 3, 6], "meet": [0, 2, 3, 6], "transcript": [0, 2, 3, 5, 6], "2": [0, 2, 6], "0": [0, 1, 2, 3], "m2met2": [0, 1, 3], "challeng": [0, 1, 3, 5, 6], "befor": 0, "must": [0, 3, 5, 6], "manual": [0, 6], "download": [0, 2], "unpack": 0, "alimeet": [0, 1, 6], "corpu": [0, 6], "place": [0, 2], "dataset": [0, 3, 5, 6, 7], "directori": 0, "eval_ali_far": 0, "eval_ali_near": 0, "test_ali_far": 0, "test_ali_near": 0, "train_ali_far": 0, "train_ali_near": 0, "test_2023_ali_far": 0, "after": 0, "which": [0, 2, 3, 6], "contain": [0, 2, 6], "onli": [0, 2, 5, 6], "raw": 0, "audio": [0, 2, 3, 6], "Then": 0, "put": 0, "given": 0, "wav": 0, "scp": 0, "wav_raw": 0, "segment": [0, 2, 6], "utt2spk": 0, "spk2utt": 0, "data": [0, 3, 5, 6], "For": [0, 2], "more": [0, 2], "detail": [0, 3, 6], "can": [0, 2, 3, 5, 6], "see": 0, "here": 0, "system": [0, 3, 5, 6, 7], "tabl": [0, 2], "adopt": 0, "oracl": [0, 6], "dure": [0, 2, 6], "howev": [0, 3, 6], "due": [0, 3], "lack": 0, "label": [0, 5, 6], "provid": [0, 2, 6, 7], "addit": [0, 6], "spectral": 0, "cluster": 0, "meanwhil": 0, "show": 0, "impact": 0, "accuraci": [0, 6], "If": [1, 5, 6], "have": [1, 3], "ani": [1, 5, 6], "question": 1, "about": [1, 3], "pleas": 1, "u": [1, 2], "email": [1, 3, 4], "m2met": [1, 3, 6, 7], "gmail": 1, "com": [1, 4], "wechat": [1, 3], "group": [1, 2, 3], "In": [2, 3, 5], "fix": [2, 3, 7], "condit": [2, 3, 7], "restrict": 2, "three": [2, 3, 6], "publicli": [2, 6], "avail": [2, 6], "corpora": 2, "name": 2, "aishel": [2, 4, 6], "4": [2, 6], "cn": [2, 4, 6], "celeb": [2, 6], "perform": [2, 3], "call": 2, "2023": [2, 3, 5, 6], "score": [2, 6], "rank": [2, 3, 6], "describ": 2, "118": 2, "75": 2, "hour": [2, 3, 6], "speech": [2, 3, 6, 7], "total": [2, 6], "divid": [2, 6], "104": 2, "10": [2, 3, 6], "specif": [2, 6], "212": 2, "8": [2, 3], "20": 2, "session": [2, 3, 6, 7], "respect": 2, "each": [2, 3, 6], "consist": [2, 6], "15": [2, 3], "30": 2, "minut": 2, "discuss": 2, "particip": [2, 5, 6], "number": [2, 3, 6], "456": 2, "25": 2, "60": 2, "balanc": 2, "gender": 2, "coverag": 2, "collect": 2, "13": [2, 3], "venu": 2, "categor": 2, "type": 2, "small": 2, "medium": 2, "larg": [2, 3], "room": [2, 3], "size": 2, "rang": 2, "m": 2, "55": 2, "differ": [2, 3, 6], "give": 2, "varieti": 2, "acoust": [2, 3, 6], "properti": 2, "layout": 2, "paramet": [2, 5], "togeth": 2, "wall": 2, "materi": 2, "cover": 2, "cement": 2, "glass": 2, "etc": 2, "other": 2, "furnish": 2, "includ": [2, 3, 5, 6], "sofa": 2, "tv": 2, "blackboard": 2, "fan": 2, "air": 2, "condition": 2, "plant": 2, "record": [2, 6], "sit": 2, "around": 2, "microphon": [2, 3], "arrai": [2, 3], "natur": 2, "convers": 2, "distanc": 2, "5": 2, "all": [2, 3, 5, 6], "nativ": 2, "chines": 2, "speak": [2, 3], "mandarin": [2, 3], "without": 2, "strong": 2, "accent": 2, "variou": [2, 3], "kind": 2, "indoor": 2, "nois": [2, 3, 5], "limit": [2, 3, 5], "click": 2, "keyboard": 2, "door": 2, "open": [2, 3, 7], "close": [2, 3], "bubbl": 2, "made": [2, 3], "both": [2, 6], "requir": [2, 3, 6], "remain": [2, 3], "same": [2, 5], "posit": 2, "overlap": [2, 3], "between": [2, 6], "exampl": 2, "fig": 2, "1": 2, "within": [2, 3], "one": [2, 5], "ensur": 2, "ratio": 2, "select": [2, 3, 5, 6], "topic": 2, "medic": 2, "treatment": 2, "educ": 2, "busi": 2, "organ": [2, 3, 5, 6, 7], "manag": 2, "industri": [2, 3], "product": 2, "daili": 2, "routin": 2, "averag": 2, "42": 2, "27": 2, "34": 2, "76": 2, "A": [2, 4], "distribut": 2, "were": 2, "ident": [2, 6], "compris": [2, 3, 7], "therebi": 2, "share": 2, "similar": 2, "configur": 2, "field": [2, 3, 6], "signal": [2, 3], "headset": 2, "": [2, 6], "own": 2, "transcrib": [2, 3, 6], "It": [2, 6], "worth": [2, 6], "note": [2, 6], "far": [2, 3], "synchron": 2, "common": 2, "prepar": 2, "textgrid": 2, "format": 2, "inform": [2, 3], "durat": 2, "id": 2, "timestamp": [2, 6], "mention": 2, "abov": 2, "openslr": 2, "via": 2, "follow": [2, 5], "link": 2, "particularli": 2, "baselin": [2, 3, 7], "conveni": 2, "automat": [3, 7], "recognit": [3, 7], "diariz": 3, "signific": 3, "stride": 3, "recent": 3, "year": 3, "result": 3, "surg": 3, "technologi": 3, "applic": 3, "across": 3, "domain": 3, "present": 3, "uniqu": [3, 6], "complex": [3, 5], "divers": 3, "style": 3, "variabl": 3, "confer": 3, "environment": 3, "reverber": [3, 5], "over": 3, "sever": 3, "been": 3, "advanc": [3, 7], "develop": [3, 6], "rich": 3, "comput": [3, 5], "hear": 3, "multisourc": 3, "environ": 3, "chime": 3, "latest": 3, "iter": 3, "ha": 3, "particular": 3, "focu": 3, "distant": 3, "gener": 3, "topologi": 3, "scenario": 3, "while": 3, "progress": 3, "english": 3, "languag": [3, 5], "barrier": 3, "achiev": 3, "compar": 3, "non": 3, "multimod": 3, "base": 3, "process": [3, 6], "misp": 3, "instrument": 3, "seek": 3, "address": 3, "problem": 3, "visual": 3, "everydai": 3, "home": 3, "focus": 3, "tackl": 3, "issu": 3, "offlin": 3, "icassp2022": 3, "main": 3, "task": [3, 6, 7], "former": 3, "involv": [3, 6], "identifi": 3, "who": 3, "spoke": 3, "when": 3, "latter": 3, "aim": 3, "multipl": [3, 6], "simultan": 3, "pose": [3, 6], "technic": 3, "difficulti": 3, "interfer": 3, "build": [3, 6, 7], "success": [3, 7], "previou": 3, "excit": 3, "propos": [3, 7], "asru": 3, "special": [3, 5, 7], "origin": [3, 5], "metric": [3, 7], "wa": [3, 6], "independ": 3, "meant": 3, "could": 3, "determin": 3, "correspond": [3, 5], "further": 3, "current": [3, 7], "talker": [3, 7], "toward": 3, "practic": 3, "attribut": [3, 7], "sub": [3, 5, 7], "track": [3, 5, 7], "what": 3, "facilit": [3, 7], "reproduc": [3, 7], "research": [3, 4, 7], "offer": 3, "comprehens": [3, 7], "overview": [3, 7], "rule": [3, 7], "furthermor": 3, "carefulli": 3, "curat": 3, "approxim": [3, 6], "design": 3, "enabl": 3, "valid": 3, "state": [3, 6, 7], "art": [3, 7], "area": 3, "april": 3, "29": 3, "registr": 3, "mai": 3, "deadlin": 3, "date": 3, "join": 3, "june": 3, "9": 3, "leaderboard": 3, "final": [3, 5, 6], "submiss": 3, "leaderboar": 3, "19": 3, "juli": 3, "paper": [3, 6], "decemb": 3, "12": 3, "16": 3, "workshop": 3, "interest": 3, "whether": 3, "academia": 3, "regist": 3, "complet": 3, "googl": 3, "form": 3, "below": 3, "22": 3, "welcom": 3, "keep": 3, "up": 3, "updat": 3, "work": 3, "dai": 3, "send": 3, "invit": 3, "elig": [3, 5], "team": 3, "qualifi": 3, "adher": [3, 5], "publish": 3, "page": 3, "prior": 3, "submit": 3, "descript": [3, 6], "document": 3, "approach": [3, 5], "method": 3, "top": 3, "asru2023": [3, 7], "proceed": 3, "lei": 4, "xie": 4, "professor": 4, "foundat": 4, "china": 4, "lxie": 4, "nwpu": 4, "edu": 4, "kong": 4, "aik": 4, "lee": 4, "senior": 4, "scientist": 4, "institut": 4, "infocomm": 4, "star": 4, "singapor": 4, "kongaik": 4, "ieee": 4, "org": 4, "zhiji": 4, "yan": 4, "princip": 4, "engin": 4, "alibaba": 4, "yzj": 4, "inc": 4, "shiliang": 4, "zhang": 4, "sly": 4, "zsl": 4, "yanmin": 4, "qian": 4, "shanghai": 4, "jiao": 4, "tong": 4, "univers": 4, "yanminqian": 4, "sjtu": 4, "zhuo": 4, "chen": 4, "appli": 4, "microsoft": 4, "usa": 4, "zhuc": 4, "jian": 4, "wu": 4, "wujian": 4, "hui": 4, "bu": 4, "ceo": 4, "buhui": 4, "aishelldata": 4, "should": 5, "augment": 5, "allow": [5, 6], "ad": 5, "speed": 5, "perturb": 5, "tone": 5, "chang": 5, "permit": 5, "purpos": 5, "instead": [5, 6], "util": [5, 6], "tune": 5, "violat": 5, "strictli": [5, 6], "prohibit": [5, 6], "fine": 5, "cpcer": [5, 6], "lower": 5, "judg": 5, "superior": 5, "forc": 5, "align": 5, "obtain": [5, 6], "frame": 5, "level": 5, "classif": 5, "basi": 5, "shallow": 5, "fusion": 5, "end": 5, "e": [5, 6], "g": 5, "la": 5, "rnnt": 5, "transform": [5, 6], "come": 5, "right": 5, "interpret": 5, "belong": 5, "case": 5, "circumst": 5, "coordin": 5, "assign": 6, "illustr": 6, "aishell4": 6, "constrain": 6, "sourc": 6, "addition": 6, "soon": 6, "simpl": 6, "voic": 6, "activ": 6, "detect": 6, "vad": 6, "concaten": 6, "minimum": 6, "permut": 6, "charact": 6, "error": 6, "rate": 6, "calcul": 6, "step": 6, "firstli": 6, "refer": 6, "hypothesi": 6, "chronolog": 6, "order": 6, "secondli": 6, "cer": 6, "repeat": 6, "possibl": 6, "lowest": 6, "tthe": 6, "insert": 6, "Ins": 6, "substitut": 6, "delet": 6, "del": 6, "output": 6, "text": 6, "frac": 6, "mathcal": 6, "n_": 6, "100": 6, "where": 6, "usag": 6, "third": 6, "hug": 6, "face": 6, "list": 6, "clearli": 6, "privat": 6, "simul": 6, "thei": 6, "mandatori": 6, "clear": 6, "scheme": 6, "delight": 7, "introduct": 7, "contact": 7}, "objects": {}, "objtypes": {}, "objnames": {}, "titleterms": {"baselin": 0, "overview": [0, 2], "quick": 0, "start": 0, "result": 0, "contact": 1, "dataset": 2, "train": [2, 6], "data": 2, "detail": 2, "alimeet": 2, "corpu": 2, "get": 2, "introduct": 3, "call": 3, "particip": 3, "timelin": 3, "aoe": 3, "time": 3, "guidelin": 3, "organ": 4, "rule": 5, "track": 6, "evalu": 6, "speaker": 6, "attribut": 6, "asr": 6, "metric": 6, "sub": 6, "arrang": 6, "i": 6, "fix": 6, "condit": 6, "ii": 6, "open": 6, "asru": 7, "2023": 7, "multi": 7, "channel": 7, "parti": 7, "meet": 7, "transcript": 7, "challeng": 7, "2": 7, "0": 7, "m2met2": 7, "content": 7}, "envversion": {"sphinx.domains.c": 2, "sphinx.domains.changeset": 1, "sphinx.domains.citation": 1, "sphinx.domains.cpp": 8, "sphinx.domains.index": 1, "sphinx.domains.javascript": 2, "sphinx.domains.math": 2, "sphinx.domains.python": 3, "sphinx.domains.rst": 2, "sphinx.domains.std": 2, "sphinx": 57}, "alltitles": {"Baseline": [[0, "baseline"]], "Overview": [[0, "overview"]], "Quick start": [[0, "quick-start"]], "Baseline results": [[0, "baseline-results"]], "Contact": [[1, "contact"]], "Datasets": [[2, "datasets"]], "Overview of training data": [[2, "overview-of-training-data"]], "Detail of AliMeeting corpus": [[2, "detail-of-alimeeting-corpus"]], "Get the data": [[2, "get-the-data"]], "Introduction": [[3, "introduction"]], "Call for participation": [[3, "call-for-participation"]], "Timeline(AOE Time)": [[3, "timeline-aoe-time"]], "Guidelines": [[3, "guidelines"]], "Organizers": [[4, "organizers"]], "Rules": [[5, "rules"]], "Track & Evaluation": [[6, "track-evaluation"]], "Speaker-Attributed ASR": [[6, "speaker-attributed-asr"]], "Evaluation metric": [[6, "evaluation-metric"]], "Sub-track arrangement": [[6, "sub-track-arrangement"]], "Sub-track I (Fixed Training Condition):": [[6, "sub-track-i-fixed-training-condition"]], "Sub-track II (Open Training Condition):": [[6, "sub-track-ii-open-training-condition"]], "ASRU 2023 MULTI-CHANNEL MULTI-PARTY MEETING TRANSCRIPTION CHALLENGE 2.0 (M2MeT2.0)": [[7, "asru-2023-multi-channel-multi-party-meeting-transcription-challenge-2-0-m2met2-0"]], "Contents:": [[7, null]]}, "indexentries": {}}) |
|---|
| | | Search.setIndex({"docnames": ["Baseline", "Contact", "Dataset", "Introduction", "Organizers", "Rules", "Track_setting_and_evaluation", "index"], "filenames": ["Baseline.md", "Contact.md", "Dataset.md", "Introduction.md", "Organizers.md", "Rules.md", "Track_setting_and_evaluation.md", "index.rst"], "titles": ["Baseline", "Contact", "Datasets", "Introduction", "Organizers", "Rules", "Track & Evaluation", "ASRU 2023 MULTI-CHANNEL MULTI-PARTY MEETING TRANSCRIPTION CHALLENGE 2.0 (M2MeT2.0)"], "terms": {"we": [0, 2, 3, 7], "releas": [0, 2, 3, 6], "an": [0, 2, 3, 6], "e2": 0, "sa": 0, "asr": [0, 3, 7], "conduct": [0, 2], "funasr": 0, "time": [0, 6], "accord": [0, 3], "timelin": [0, 2], "The": [0, 2, 3, 5, 6], "model": [0, 2, 3, 5, 6], "architectur": 0, "i": [0, 2, 3, 5], "shown": [0, 2], "figur": [0, 6], "3": [0, 2, 3], "speakerencod": 0, "initi": 0, "pre": [0, 6], "train": [0, 3, 5, 7], "speaker": [0, 2, 3, 7], "verif": 0, "from": [0, 2, 3, 5, 6], "modelscop": [0, 6], "thi": [0, 3, 5, 6], "also": [0, 2, 3, 6], "us": [0, 2, 5, 6], "extract": 0, "embed": 0, "profil": 0, "To": [0, 2, 3, 7], "run": 0, "first": 0, "you": [0, 1], "need": 0, "instal": 0, "There": [0, 2], "ar": [0, 2, 3, 5, 6, 7], "two": [0, 3, 5, 7], "startup": 0, "script": [0, 2], "sh": 0, "evalu": [0, 2, 3, 7], "old": 0, "eval": [0, 2, 5, 6], "test": [0, 2, 3, 5, 6], "set": [0, 2, 3, 5, 6], "run_m2met_2023_inf": 0, "infer": 0, "new": [0, 2, 3, 6], "multi": [0, 3, 6], "channel": [0, 3], "parti": [0, 3, 6], "meet": [0, 2, 3, 6], "transcript": [0, 2, 3, 5, 6], "2": [0, 2, 6], "0": [0, 1, 2, 3], "m2met2": [0, 1, 3], "challeng": [0, 1, 3, 5, 6], "befor": 0, "must": [0, 3, 5, 6], "manual": [0, 6], "download": [0, 2], "unpack": 0, "alimeet": [0, 1, 6], "corpu": [0, 6], "place": [0, 2], "dataset": [0, 3, 5, 6, 7], "directori": 0, "eval_ali_far": 0, "eval_ali_near": 0, "test_ali_far": 0, "test_ali_near": 0, "train_ali_far": 0, "train_ali_near": 0, "test_2023_ali_far": 0, "after": 0, "which": [0, 2, 3, 6], "contain": [0, 2, 6], "onli": [0, 2, 5, 6], "raw": 0, "audio": [0, 2, 3, 6], "Then": 0, "put": 0, "given": 0, "wav": 0, "scp": 0, "wav_raw": 0, "segment": [0, 2, 6], "utt2spk": 0, "spk2utt": 0, "data": [0, 3, 5, 6], "For": [0, 2], "more": [0, 2], "detail": [0, 3, 6], "can": [0, 2, 3, 5, 6], "see": 0, "here": 0, "system": [0, 3, 5, 6, 7], "tabl": [0, 2], "adopt": 0, "oracl": [0, 6], "dure": [0, 2, 6], "howev": [0, 3, 6], "due": [0, 3], "lack": 0, "label": [0, 5, 6], "provid": [0, 2, 6, 7], "addit": [0, 6], "spectral": 0, "cluster": 0, "meanwhil": 0, "show": 0, "impact": 0, "accuraci": [0, 6], "If": [1, 5, 6], "have": [1, 3], "ani": [1, 5, 6], "question": 1, "about": [1, 3], "pleas": 1, "u": [1, 2], "email": [1, 3, 4], "m2met": [1, 3, 6, 7], "gmail": 1, "com": [1, 4], "wechat": [1, 3], "group": [1, 2, 3], "In": [2, 3, 5], "fix": [2, 3, 7], "condit": [2, 3, 7], "restrict": 2, "three": [2, 3, 6], "publicli": [2, 6], "avail": [2, 6], "corpora": 2, "name": 2, "aishel": [2, 4, 6], "4": [2, 6], "cn": [2, 4, 6], "celeb": [2, 6], "perform": [2, 3], "call": 2, "2023": [2, 3, 5, 6], "score": [2, 6], "rank": [2, 3, 6], "describ": 2, "118": 2, "75": 2, "hour": [2, 3, 6], "speech": [2, 3, 6, 7], "total": [2, 6], "divid": [2, 6], "104": 2, "10": [2, 3, 6], "specif": [2, 6], "212": 2, "8": 2, "20": [2, 3], "session": [2, 3, 6, 7], "respect": 2, "each": [2, 3, 6], "consist": [2, 6], "15": 2, "30": 2, "minut": 2, "discuss": 2, "particip": [2, 5, 6], "number": [2, 3, 6], "456": 2, "25": 2, "60": 2, "balanc": 2, "gender": 2, "coverag": 2, "collect": 2, "13": 2, "venu": 2, "categor": 2, "type": 2, "small": 2, "medium": 2, "larg": [2, 3], "room": [2, 3], "size": 2, "rang": 2, "m": 2, "55": 2, "differ": [2, 3, 6], "give": 2, "varieti": 2, "acoust": [2, 3, 6], "properti": 2, "layout": 2, "paramet": [2, 5], "togeth": 2, "wall": 2, "materi": 2, "cover": 2, "cement": 2, "glass": 2, "etc": 2, "other": 2, "furnish": 2, "includ": [2, 3, 5, 6], "sofa": 2, "tv": 2, "blackboard": 2, "fan": 2, "air": 2, "condition": 2, "plant": 2, "record": [2, 6], "sit": 2, "around": 2, "microphon": [2, 3], "arrai": [2, 3], "natur": 2, "convers": 2, "distanc": 2, "5": 2, "all": [2, 3, 5, 6], "nativ": 2, "chines": 2, "speak": [2, 3], "mandarin": [2, 3], "without": 2, "strong": 2, "accent": 2, "variou": [2, 3], "kind": 2, "indoor": 2, "nois": [2, 3, 5], "limit": [2, 3, 5], "click": 2, "keyboard": 2, "door": 2, "open": [2, 3, 7], "close": [2, 3], "bubbl": 2, "made": [2, 3], "both": [2, 6], "requir": [2, 3, 6], "remain": [2, 3], "same": [2, 5], "posit": 2, "overlap": [2, 3], "between": [2, 6], "exampl": 2, "fig": 2, "1": 2, "within": [2, 3], "one": [2, 5], "ensur": 2, "ratio": 2, "select": [2, 3, 5, 6], "topic": 2, "medic": 2, "treatment": 2, "educ": 2, "busi": 2, "organ": [2, 3, 5, 6, 7], "manag": 2, "industri": [2, 3], "product": 2, "daili": 2, "routin": 2, "averag": 2, "42": 2, "27": 2, "34": 2, "76": 2, "A": [2, 4], "distribut": 2, "were": 2, "ident": [2, 6], "compris": [2, 3, 7], "therebi": 2, "share": 2, "similar": 2, "configur": 2, "field": [2, 3, 6], "signal": [2, 3], "headset": 2, "": [2, 6], "own": 2, "transcrib": [2, 3, 6], "It": [2, 6], "worth": [2, 6], "note": [2, 6], "far": [2, 3], "synchron": 2, "common": 2, "prepar": 2, "textgrid": 2, "format": 2, "inform": [2, 3], "durat": 2, "id": 2, "timestamp": [2, 6], "mention": 2, "abov": 2, "openslr": 2, "via": 2, "follow": [2, 5], "link": 2, "particularli": 2, "baselin": [2, 3, 7], "conveni": 2, "automat": [3, 7], "recognit": [3, 7], "diariz": 3, "signific": 3, "stride": 3, "recent": 3, "year": 3, "result": 3, "surg": 3, "technologi": 3, "applic": 3, "across": 3, "domain": 3, "present": 3, "uniqu": [3, 6], "complex": [3, 5], "divers": 3, "style": 3, "variabl": 3, "confer": 3, "environment": 3, "reverber": [3, 5], "over": 3, "sever": 3, "been": 3, "advanc": [3, 7], "develop": [3, 6], "rich": 3, "comput": [3, 5], "hear": 3, "multisourc": 3, "environ": 3, "chime": 3, "latest": 3, "iter": 3, "ha": 3, "particular": 3, "focu": 3, "distant": 3, "gener": 3, "topologi": 3, "scenario": 3, "while": 3, "progress": 3, "english": 3, "languag": [3, 5], "barrier": 3, "achiev": 3, "compar": 3, "non": 3, "multimod": 3, "base": 3, "process": [3, 6], "misp": 3, "instrument": 3, "seek": 3, "address": 3, "problem": 3, "visual": 3, "everydai": 3, "home": 3, "focus": 3, "tackl": 3, "issu": 3, "offlin": 3, "icassp2022": 3, "main": 3, "task": [3, 6, 7], "former": 3, "involv": [3, 6], "identifi": 3, "who": 3, "spoke": 3, "when": 3, "latter": 3, "aim": 3, "multipl": [3, 6], "simultan": 3, "pose": [3, 6], "technic": 3, "difficulti": 3, "interfer": 3, "build": [3, 6, 7], "success": [3, 7], "previou": 3, "excit": 3, "propos": [3, 7], "asru": 3, "special": [3, 5, 7], "origin": [3, 5], "metric": [3, 7], "wa": [3, 6], "independ": 3, "meant": 3, "could": 3, "determin": 3, "correspond": [3, 5], "further": 3, "current": [3, 7], "talker": [3, 7], "toward": 3, "practic": 3, "attribut": [3, 7], "sub": [3, 5, 7], "track": [3, 5, 7], "what": 3, "facilit": [3, 7], "reproduc": [3, 7], "research": [3, 4, 7], "offer": 3, "comprehens": [3, 7], "overview": [3, 7], "rule": [3, 7], "furthermor": 3, "carefulli": 3, "curat": 3, "approxim": [3, 6], "design": 3, "enabl": 3, "valid": 3, "state": [3, 6, 7], "art": [3, 7], "area": 3, "april": 3, "29": 3, "registr": 3, "mai": 3, "11": 3, "22": 3, "deadlin": 3, "date": 3, "join": 3, "june": 3, "16": 3, "leaderboard": 3, "final": [3, 5, 6], "submiss": 3, "leaderboar": 3, "26": 3, "juli": 3, "paper": [3, 6], "decemb": 3, "12": 3, "workshop": 3, "interest": 3, "whether": 3, "academia": 3, "regist": 3, "complet": 3, "googl": 3, "form": 3, "below": 3, "welcom": 3, "keep": 3, "up": 3, "updat": 3, "work": 3, "dai": 3, "send": 3, "invit": 3, "elig": [3, 5], "team": 3, "qualifi": 3, "adher": [3, 5], "publish": 3, "page": 3, "prior": 3, "submit": 3, "descript": [3, 6], "document": 3, "approach": [3, 5], "method": 3, "top": 3, "asru2023": [3, 7], "proceed": 3, "lei": 4, "xie": 4, "professor": 4, "foundat": 4, "china": 4, "lxie": 4, "nwpu": 4, "edu": 4, "kong": 4, "aik": 4, "lee": 4, "senior": 4, "scientist": 4, "institut": 4, "infocomm": 4, "star": 4, "singapor": 4, "kongaik": 4, "ieee": 4, "org": 4, "zhiji": 4, "yan": 4, "princip": 4, "engin": 4, "alibaba": 4, "yzj": 4, "inc": 4, "shiliang": 4, "zhang": 4, "sly": 4, "zsl": 4, "yanmin": 4, "qian": 4, "shanghai": 4, "jiao": 4, "tong": 4, "univers": 4, "yanminqian": 4, "sjtu": 4, "zhuo": 4, "chen": 4, "appli": 4, "microsoft": 4, "usa": 4, "zhuc": 4, "jian": 4, "wu": 4, "wujian": 4, "hui": 4, "bu": 4, "ceo": 4, "buhui": 4, "aishelldata": 4, "should": 5, "augment": 5, "allow": [5, 6], "ad": 5, "speed": 5, "perturb": 5, "tone": 5, "chang": 5, "permit": 5, "purpos": 5, "instead": [5, 6], "util": [5, 6], "tune": 5, "violat": 5, "strictli": [5, 6], "prohibit": [5, 6], "fine": 5, "cpcer": [5, 6], "lower": 5, "judg": 5, "superior": 5, "forc": 5, "align": 5, "obtain": [5, 6], "frame": 5, "level": 5, "classif": 5, "basi": 5, "shallow": 5, "fusion": 5, "end": 5, "e": [5, 6], "g": 5, "la": 5, "rnnt": 5, "transform": [5, 6], "come": 5, "right": 5, "interpret": 5, "belong": 5, "case": 5, "circumst": 5, "coordin": 5, "assign": 6, "illustr": 6, "aishell4": 6, "constrain": 6, "sourc": 6, "addition": 6, "soon": 6, "simpl": 6, "voic": 6, "activ": 6, "detect": 6, "vad": 6, "concaten": 6, "minimum": 6, "permut": 6, "charact": 6, "error": 6, "rate": 6, "calcul": 6, "step": 6, "firstli": 6, "refer": 6, "hypothesi": 6, "chronolog": 6, "order": 6, "secondli": 6, "cer": 6, "repeat": 6, "possibl": 6, "lowest": 6, "tthe": 6, "insert": 6, "Ins": 6, "substitut": 6, "delet": 6, "del": 6, "output": 6, "text": 6, "frac": 6, "mathcal": 6, "n_": 6, "100": 6, "where": 6, "usag": 6, "third": 6, "hug": 6, "face": 6, "list": 6, "clearli": 6, "privat": 6, "simul": 6, "thei": 6, "mandatori": 6, "clear": 6, "scheme": 6, "delight": 7, "introduct": 7, "contact": 7}, "objects": {}, "objtypes": {}, "objnames": {}, "titleterms": {"baselin": 0, "overview": [0, 2], "quick": 0, "start": 0, "result": 0, "contact": 1, "dataset": 2, "train": [2, 6], "data": 2, "detail": 2, "alimeet": 2, "corpu": 2, "get": 2, "introduct": 3, "call": 3, "particip": 3, "timelin": 3, "aoe": 3, "time": 3, "guidelin": 3, "organ": 4, "rule": 5, "track": 6, "evalu": 6, "speaker": 6, "attribut": 6, "asr": 6, "metric": 6, "sub": 6, "arrang": 6, "i": 6, "fix": 6, "condit": 6, "ii": 6, "open": 6, "asru": 7, "2023": 7, "multi": 7, "channel": 7, "parti": 7, "meet": 7, "transcript": 7, "challeng": 7, "2": 7, "0": 7, "m2met2": 7, "content": 7}, "envversion": {"sphinx.domains.c": 2, "sphinx.domains.changeset": 1, "sphinx.domains.citation": 1, "sphinx.domains.cpp": 8, "sphinx.domains.index": 1, "sphinx.domains.javascript": 2, "sphinx.domains.math": 2, "sphinx.domains.python": 3, "sphinx.domains.rst": 2, "sphinx.domains.std": 2, "sphinx": 57}, "alltitles": {"Baseline": [[0, "baseline"]], "Overview": [[0, "overview"]], "Quick start": [[0, "quick-start"]], "Baseline results": [[0, "baseline-results"]], "Contact": [[1, "contact"]], "Datasets": [[2, "datasets"]], "Overview of training data": [[2, "overview-of-training-data"]], "Detail of AliMeeting corpus": [[2, "detail-of-alimeeting-corpus"]], "Get the data": [[2, "get-the-data"]], "Introduction": [[3, "introduction"]], "Call for participation": [[3, "call-for-participation"]], "Timeline(AOE Time)": [[3, "timeline-aoe-time"]], "Guidelines": [[3, "guidelines"]], "Organizers": [[4, "organizers"]], "Rules": [[5, "rules"]], "Track & Evaluation": [[6, "track-evaluation"]], "Speaker-Attributed ASR": [[6, "speaker-attributed-asr"]], "Evaluation metric": [[6, "evaluation-metric"]], "Sub-track arrangement": [[6, "sub-track-arrangement"]], "Sub-track I (Fixed Training Condition):": [[6, "sub-track-i-fixed-training-condition"]], "Sub-track II (Open Training Condition):": [[6, "sub-track-ii-open-training-condition"]], "ASRU 2023 MULTI-CHANNEL MULTI-PARTY MEETING TRANSCRIPTION CHALLENGE 2.0 (M2MeT2.0)": [[7, "asru-2023-multi-channel-multi-party-meeting-transcription-challenge-2-0-m2met2-0"]], "Contents:": [[7, null]]}, "indexentries": {}}) |
|---|
| | |
|---|
| | | æ´å¤åºçº¿ç³»ç»è¯¦æ
è§[æ¤å¤](https://github.com/alibaba-damo-academy/FunASR/blob/main/egs/alimeeting/sa-asr/README.md) |
|---|
| | | ## åºçº¿ç»æ |
|---|
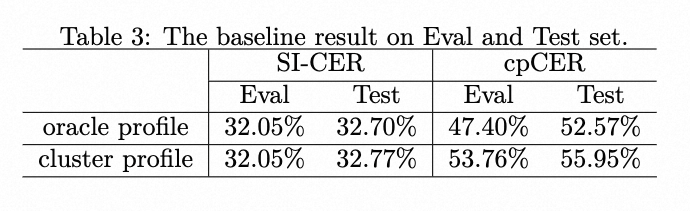
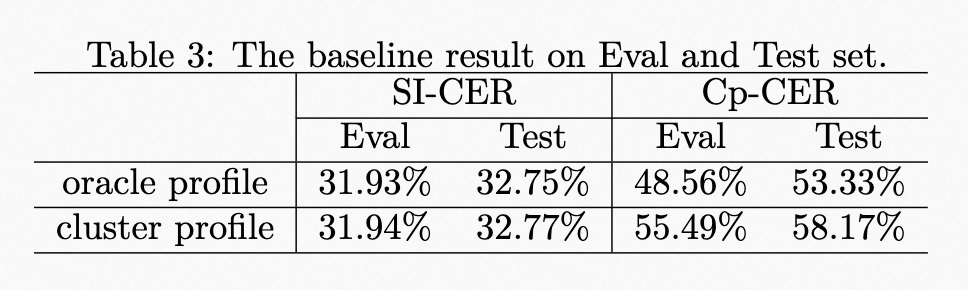
| | | åºçº¿ç³»ç»çç»æå¦è¡¨3æ示ãå¨è®ç»æé´ï¼è¯´è¯äººæ¡£æ¡éç¨äºçå®è¯´è¯äººåµå
¥ãç¶èç±äºå¨è¯ä¼°è¿ç¨ä¸ç¼ºä¹çå®è¯´è¯äººæ ç¾ï¼å æ¤ä½¿ç¨äºç±é¢å¤çè°±èç±»æä¾ç说è¯äººç¹å¾ãåæ¶æ们è¿æä¾äºå¨è¯ä¼°åæµè¯éä¸ä½¿ç¨çå®è¯´è¯äººæ¡£æ¡çç»æï¼ä»¥æ¾ç¤ºè¯´è¯äººæ¡£æ¡åç¡®æ§çå½±åã |
|---|
| | |  |
|---|
| | | |
|---|
| | |  |
|---|
| | |
|---|
| | | </section> |
|---|
| | | <section id="id4"> |
|---|
| | | <h2>åºçº¿ç»æ<a class="headerlink" href="#id4" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h2> |
|---|
| | | <p>åºçº¿ç³»ç»çç»æå¦è¡¨3æ示ãå¨è®ç»æé´ï¼è¯´è¯äººæ¡£æ¡éç¨äºçå®è¯´è¯äººåµå
¥ãç¶èç±äºå¨è¯ä¼°è¿ç¨ä¸ç¼ºä¹çå®è¯´è¯äººæ ç¾ï¼å æ¤ä½¿ç¨äºç±é¢å¤çè°±èç±»æä¾ç说è¯äººç¹å¾ãåæ¶æ们è¿æä¾äºå¨è¯ä¼°åæµè¯éä¸ä½¿ç¨çå®è¯´è¯äººæ¡£æ¡çç»æï¼ä»¥æ¾ç¤ºè¯´è¯äººæ¡£æ¡åç¡®æ§çå½±åã |
|---|
| | | <img alt="baseline result" src="_images/baseline_result.png" /></p> |
|---|
| | | <p>åºçº¿ç³»ç»çç»æå¦è¡¨3æ示ãå¨è®ç»æé´ï¼è¯´è¯äººæ¡£æ¡éç¨äºçå®è¯´è¯äººåµå
¥ãç¶èç±äºå¨è¯ä¼°è¿ç¨ä¸ç¼ºä¹çå®è¯´è¯äººæ ç¾ï¼å æ¤ä½¿ç¨äºç±é¢å¤çè°±èç±»æä¾ç说è¯äººç¹å¾ãåæ¶æ们è¿æä¾äºå¨è¯ä¼°åæµè¯éä¸ä½¿ç¨çå®è¯´è¯äººæ¡£æ¡çç»æï¼ä»¥æ¾ç¤ºè¯´è¯äººæ¡£æ¡åç¡®æ§çå½±åã</p> |
|---|
| | | <p><img alt="baseline_result" src="_images/baseline_result.png" /></p> |
|---|
| | | </section> |
|---|
| | | </section> |
|---|
| | | |
|---|
| | |
|---|
| | | æ´å¤åºçº¿ç³»ç»è¯¦æ
è§[æ¤å¤](https://github.com/alibaba-damo-academy/FunASR/blob/main/egs/alimeeting/sa-asr/README.md) |
|---|
| | | ## åºçº¿ç»æ |
|---|
| | | åºçº¿ç³»ç»çç»æå¦è¡¨3æ示ãå¨è®ç»æé´ï¼è¯´è¯äººæ¡£æ¡éç¨äºçå®è¯´è¯äººåµå
¥ãç¶èç±äºå¨è¯ä¼°è¿ç¨ä¸ç¼ºä¹çå®è¯´è¯äººæ ç¾ï¼å æ¤ä½¿ç¨äºç±é¢å¤çè°±èç±»æä¾ç说è¯äººç¹å¾ãåæ¶æ们è¿æä¾äºå¨è¯ä¼°åæµè¯éä¸ä½¿ç¨çå®è¯´è¯äººæ¡£æ¡çç»æï¼ä»¥æ¾ç¤ºè¯´è¯äººæ¡£æ¡åç¡®æ§çå½±åã |
|---|
| | |  |
|---|
| | | |
|---|
| | |  |
|---|
| | |
|---|
| | | stage 7 - 9: Language model training (Optional). |
|---|
| | | stage 10 - 11: ASR training (SA-ASR requires loading the pre-trained ASR model). |
|---|
| | | stage 12: SA-ASR training. |
|---|
| | | stage 13 - 18: Inference and evaluation. |
|---|
| | | stage 13 - 16: Inference and evaluation. |
|---|
| | | ``` |
|---|
| | | Before running `run_m2met_2023_infer.sh`, you need to place the new test set `Test_2023_Ali_far` (to be released after the challenge starts) in the `./dataset` directory, which contains only raw audios. Then put the given `wav.scp`, `wav_raw.scp`, `segments`, `utt2spk` and `spk2utt` in the `./data/Test_2023_Ali_far` directory. |
|---|
| | | ```shell |
|---|
| | |
|---|
| | | stage 3: Inference. |
|---|
| | | stage 4: Generation of SA-ASR results required for final submission. |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | The baseline model is available on [ModelScope](https://www.modelscope.cn/models/damo/speech_saasr_asr-zh-cn-16k-alimeeting/summary). |
|---|
| | | After generate stats of AliMeeting corpus(stage 10 in `run.sh`), you can set the `infer_with_pretrained_model=true` in `run.sh` to infer with our official baseline model released on ModelScope without training. |
|---|
| | | |
|---|
| | | # Format of Final Submission |
|---|
| | | Finally, you need to submit a file called `text_spk_merge` with the following format: |
|---|
| | | ```shell |
|---|
| | |
|---|
| | | # inference_asr_model=valid.acc.best.pth |
|---|
| | | # inference_asr_model=valid.loss.ave.pth |
|---|
| | | inference_sa_asr_model=valid.acc_spk.ave.pb |
|---|
| | | download_model= # Download a model from Model Zoo and use it for decoding. |
|---|
| | | |
|---|
| | | infer_with_pretrained_model=false # Use pretrained model for decoding |
|---|
| | | download_sa_asr_model= # Download the SA-ASR model from ModelScope and use it for decoding. |
|---|
| | | # [Task dependent] Set the datadir name created by local/data.sh |
|---|
| | | train_set= # Name of training set. |
|---|
| | | valid_set= # Name of validation set used for monitoring/tuning network training. |
|---|
| | |
|---|
| | | # Note that it will overwrite args in inference config. |
|---|
| | | --inference_lm # Language modle path for decoding (default="${inference_lm}"). |
|---|
| | | --inference_asr_model # ASR model path for decoding (default="${inference_asr_model}"). |
|---|
| | | --download_model # Download a model from Model Zoo and use it for decoding (default="${download_model}"). |
|---|
| | | --infer_with_pretrained_model # Use pretrained model for decoding (default="${infer_with_pretrained_model}"). |
|---|
| | | --download_sa_asr_model= # Download the SA-ASR model from ModelScope and use it for decoding(default="${download_sa_asr_model}"). |
|---|
| | | |
|---|
| | | # [Task dependent] Set the datadir name created by local/data.sh |
|---|
| | | --train_set # Name of training set (required). |
|---|
| | |
|---|
| | | lm_token_type="${token_type}" |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if ${infer_with_pretrained_model}; then |
|---|
| | | skip_train=true |
|---|
| | | fi |
|---|
| | | |
|---|
| | | # Set tag for naming of model directory |
|---|
| | | if [ -z "${asr_tag}" ]; then |
|---|
| | |
|---|
| | | log "Skip the training stages" |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if ${infer_with_pretrained_model}; then |
|---|
| | | log "Use ${download_sa_asr_model} for decoding and evaluation" |
|---|
| | | |
|---|
| | | sa_asr_exp="${expdir}/${download_sa_asr_model}" |
|---|
| | | mkdir -p "${sa_asr_exp}" |
|---|
| | | |
|---|
| | | python local/download_pretrained_model_from_modelscope.py $download_sa_asr_model ${expdir} |
|---|
| | | inference_sa_asr_model="model.pb" |
|---|
| | | inference_config=${sa_asr_exp}/decoding.yaml |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if ! "${skip_eval}"; then |
|---|
| | | if [ ${stage} -le 13 ] && [ ${stop_stage} -ge 13 ]; then |
|---|
| | | log "Stage 13: Decoding multi-talker ASR: training_dir=${asr_exp}" |
|---|
| | | |
|---|
| | | if ${gpu_inference}; then |
|---|
| | | _cmd="${cuda_cmd}" |
|---|
| | | inference_nj=$[${ngpu}*${njob_infer}] |
|---|
| | | _ngpu=1 |
|---|
| | | |
|---|
| | | else |
|---|
| | | _cmd="${decode_cmd}" |
|---|
| | | inference_nj=$inference_nj |
|---|
| | | _ngpu=0 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | _opts= |
|---|
| | | if [ -n "${inference_config}" ]; then |
|---|
| | | _opts+="--config ${inference_config} " |
|---|
| | | fi |
|---|
| | | if "${use_lm}"; then |
|---|
| | | if "${use_word_lm}"; then |
|---|
| | | _opts+="--word_lm_train_config ${lm_exp}/config.yaml " |
|---|
| | | _opts+="--word_lm_file ${lm_exp}/${inference_lm} " |
|---|
| | | else |
|---|
| | | _opts+="--lm_train_config ${lm_exp}/config.yaml " |
|---|
| | | _opts+="--lm_file ${lm_exp}/${inference_lm} " |
|---|
| | | fi |
|---|
| | | fi |
|---|
| | | |
|---|
| | | # 2. Generate run.sh |
|---|
| | | log "Generate '${asr_exp}/${inference_tag}/run.sh'. You can resume the process from stage 13 using this script" |
|---|
| | | mkdir -p "${asr_exp}/${inference_tag}"; echo "${run_args} --stage 13 \"\$@\"; exit \$?" > "${asr_exp}/${inference_tag}/run.sh"; chmod +x "${asr_exp}/${inference_tag}/run.sh" |
|---|
| | | |
|---|
| | | for dset in ${test_sets}; do |
|---|
| | | _data="${data_feats}/${dset}" |
|---|
| | | _dir="${asr_exp}/${inference_tag}/${dset}" |
|---|
| | | _logdir="${_dir}/logdir" |
|---|
| | | mkdir -p "${_logdir}" |
|---|
| | | |
|---|
| | | _feats_type="$(<${_data}/feats_type)" |
|---|
| | | if [ "${_feats_type}" = raw ]; then |
|---|
| | | _scp=wav.scp |
|---|
| | | if [[ "${audio_format}" == *ark* ]]; then |
|---|
| | | _type=kaldi_ark |
|---|
| | | else |
|---|
| | | _type=sound |
|---|
| | | fi |
|---|
| | | else |
|---|
| | | _scp=feats.scp |
|---|
| | | _type=kaldi_ark |
|---|
| | | fi |
|---|
| | | |
|---|
| | | # 1. Split the key file |
|---|
| | | key_file=${_data}/${_scp} |
|---|
| | | split_scps="" |
|---|
| | | _nj=$(min "${inference_nj}" "$(<${key_file} wc -l)") |
|---|
| | | echo $_nj |
|---|
| | | for n in $(seq "${_nj}"); do |
|---|
| | | split_scps+=" ${_logdir}/keys.${n}.scp" |
|---|
| | | done |
|---|
| | | # shellcheck disable=SC2086 |
|---|
| | | utils/split_scp.pl "${key_file}" ${split_scps} |
|---|
| | | |
|---|
| | | # 2. Submit decoding jobs |
|---|
| | | log "Decoding started... log: '${_logdir}/asr_inference.*.log'" |
|---|
| | | |
|---|
| | | ${_cmd} --gpu "${_ngpu}" --max-jobs-run "${_nj}" JOB=1:"${_nj}" "${_logdir}"/asr_inference.JOB.log \ |
|---|
| | | python -m funasr.bin.asr_inference_launch \ |
|---|
| | | --batch_size 1 \ |
|---|
| | | --mc True \ |
|---|
| | | --nbest 1 \ |
|---|
| | | --ngpu "${_ngpu}" \ |
|---|
| | | --njob ${njob_infer} \ |
|---|
| | | --gpuid_list ${device} \ |
|---|
| | | --data_path_and_name_and_type "${_data}/${_scp},speech,${_type}" \ |
|---|
| | | --key_file "${_logdir}"/keys.JOB.scp \ |
|---|
| | | --asr_train_config "${asr_exp}"/config.yaml \ |
|---|
| | | --asr_model_file "${asr_exp}"/"${inference_asr_model}" \ |
|---|
| | | --output_dir "${_logdir}"/output.JOB \ |
|---|
| | | --mode asr \ |
|---|
| | | ${_opts} |
|---|
| | | |
|---|
| | | # 3. Concatenates the output files from each jobs |
|---|
| | | for f in token token_int score text; do |
|---|
| | | for i in $(seq "${_nj}"); do |
|---|
| | | cat "${_logdir}/output.${i}/1best_recog/${f}" |
|---|
| | | done | LC_ALL=C sort -k1 >"${_dir}/${f}" |
|---|
| | | done |
|---|
| | | done |
|---|
| | | fi |
|---|
| | | |
|---|
| | | |
|---|
| | | if [ ${stage} -le 14 ] && [ ${stop_stage} -ge 14 ]; then |
|---|
| | | log "Stage 14: Scoring multi-talker ASR" |
|---|
| | | |
|---|
| | | for dset in ${test_sets}; do |
|---|
| | | _data="${data_feats}/${dset}" |
|---|
| | | _dir="${asr_exp}/${inference_tag}/${dset}" |
|---|
| | | |
|---|
| | | python utils/proce_text.py ${_data}/text ${_data}/text.proc |
|---|
| | | python utils/proce_text.py ${_dir}/text ${_dir}/text.proc |
|---|
| | | |
|---|
| | | python utils/compute_wer.py ${_data}/text.proc ${_dir}/text.proc ${_dir}/text.cer |
|---|
| | | tail -n 3 ${_dir}/text.cer > ${_dir}/text.cer.txt |
|---|
| | | cat ${_dir}/text.cer.txt |
|---|
| | | |
|---|
| | | done |
|---|
| | | |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ ${stage} -le 15 ] && [ ${stop_stage} -ge 15 ]; then |
|---|
| | | log "Stage 15: Decoding SA-ASR (oracle profile): training_dir=${sa_asr_exp}" |
|---|
| | | log "Stage 13: Decoding SA-ASR (oracle profile): training_dir=${sa_asr_exp}" |
|---|
| | | |
|---|
| | | if ${gpu_inference}; then |
|---|
| | | _cmd="${cuda_cmd}" |
|---|
| | |
|---|
| | | done |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ ${stage} -le 16 ] && [ ${stop_stage} -ge 16 ]; then |
|---|
| | | log "Stage 16: Scoring SA-ASR (oracle profile)" |
|---|
| | | if [ ${stage} -le 14 ] && [ ${stop_stage} -ge 14 ]; then |
|---|
| | | log "Stage 14: Scoring SA-ASR (oracle profile)" |
|---|
| | | |
|---|
| | | for dset in ${test_sets}; do |
|---|
| | | _data="${data_feats}/${dset}" |
|---|
| | |
|---|
| | | |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ ${stage} -le 17 ] && [ ${stop_stage} -ge 17 ]; then |
|---|
| | | log "Stage 17: Decoding SA-ASR (cluster profile): training_dir=${sa_asr_exp}" |
|---|
| | | if [ ${stage} -le 15 ] && [ ${stop_stage} -ge 15 ]; then |
|---|
| | | log "Stage 15: Decoding SA-ASR (cluster profile): training_dir=${sa_asr_exp}" |
|---|
| | | |
|---|
| | | if ${gpu_inference}; then |
|---|
| | | _cmd="${cuda_cmd}" |
|---|
| | |
|---|
| | | done |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ ${stage} -le 18 ] && [ ${stop_stage} -ge 18 ]; then |
|---|
| | | log "Stage 18: Scoring SA-ASR (cluster profile)" |
|---|
| | | if [ ${stage} -le 16 ] && [ ${stop_stage} -ge 16 ]; then |
|---|
| | | log "Stage 16: Scoring SA-ASR (cluster profile)" |
|---|
| | | |
|---|
| | | for dset in ${test_sets}; do |
|---|
| | | _data="${data_feats}/${dset}" |
|---|
| New file |
| | |
|---|
| | | from modelscope.hub.snapshot_download import snapshot_download |
|---|
| | | import sys |
|---|
| | | |
|---|
| | | if __name__ == "__main__": |
|---|
| | | model_tag = sys.argv[1] |
|---|
| | | local_model_dir = sys.argv[2] |
|---|
| | | model_dir = snapshot_download(model_tag, cache_dir=local_model_dir, revision='1.0.0') |
|---|
| | |
|---|
| | | ngpu=4 |
|---|
| | | device="0,1,2,3" |
|---|
| | | |
|---|
| | | stage=1 |
|---|
| | | stop_stage=18 |
|---|
| | | stage=12 |
|---|
| | | stop_stage=13 |
|---|
| | | |
|---|
| | | |
|---|
| | | train_set=Train_Ali_far |
|---|
| | |
|---|
| | | asr_config=conf/train_asr_conformer.yaml |
|---|
| | | sa_asr_config=conf/train_sa_asr_conformer.yaml |
|---|
| | | inference_config=conf/decode_asr_rnn.yaml |
|---|
| | | infer_with_pretrained_model=true |
|---|
| | | download_sa_asr_model="damo/speech_saasr_asr-zh-cn-16k-alimeeting" |
|---|
| | | |
|---|
| | | lm_config=conf/train_lm_transformer.yaml |
|---|
| | | use_lm=false |
|---|
| | |
|---|
| | | --stop_stage ${stop_stage} \ |
|---|
| | | --gpu_inference true \ |
|---|
| | | --njob_infer 4 \ |
|---|
| | | --infer_with_pretrained_model ${infer_with_pretrained_model} \ |
|---|
| | | --download_sa_asr_model $download_sa_asr_model \ |
|---|
| | | --asr_exp exp/asr_train_multispeaker_conformer_raw_zh_char_data_alimeeting \ |
|---|
| | | --sa_asr_exp exp/sa_asr_train_conformer_raw_zh_char_data_alimeeting \ |
|---|
| | | --asr_stats_dir exp/asr_stats_multispeaker_conformer_raw_zh_char_data_alimeeting \ |
|---|











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}