Merge pull request #48 from dyyzhmm/main
grpc client and server for streaming-upload audio bytes.
| New file |
| | |
|---|
| | | # Using paraformer with grpc |
|---|
| | | We can send streaming audio data to server in real-time with grpc client every 10 ms e.g., and get transcribed text when stop speaking. |
|---|
| | | The audio data is in streaming, the asr inference process is in offline. |
|---|
| | | |
|---|
| | | |
|---|
| | | ## Steps |
|---|
| | | |
|---|
| | | Step 1) Prepare server environment (on server). |
|---|
| | | ``` |
|---|
| | | # Optional, modelscope cuda docker is preferred. |
|---|
| | | CID=`docker run --network host -d -it --gpus '"device=0"' registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.3.0-py37-torch1.11.0-tf1.15.5-1.2.0` |
|---|
| | | echo $CID |
|---|
| | | docker exec -it $CID /bin/bash |
|---|
| | | cd /opt/conda/lib/python3.7/site-packages/funasr/runtime/python/grpc |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | Step 2) Generate protobuf file (for server and client). |
|---|
| | | ``` |
|---|
| | | # Optional, paraformer_pb2.py and paraformer_pb2_grpc.py are already generated. |
|---|
| | | python -m grpc_tools.protoc --proto_path=./proto -I ./proto --python_out=. --grpc_python_out=./ ./proto/paraformer.proto |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | Step 3) Start grpc server (on server). |
|---|
| | | ``` |
|---|
| | | python grpc_main_server.py --port 10095 |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | Step 4) Start grpc client (on client with microphone). |
|---|
| | | ``` |
|---|
| | | # Install dependency. Optional. |
|---|
| | | python -m pip install pyaudio webrtcvad |
|---|
| | | ``` |
|---|
| | | ``` |
|---|
| | | # Start client. |
|---|
| | | python grpc_main_client_mic.py --host 127.0.0.1 --port 10095 |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | |
|---|
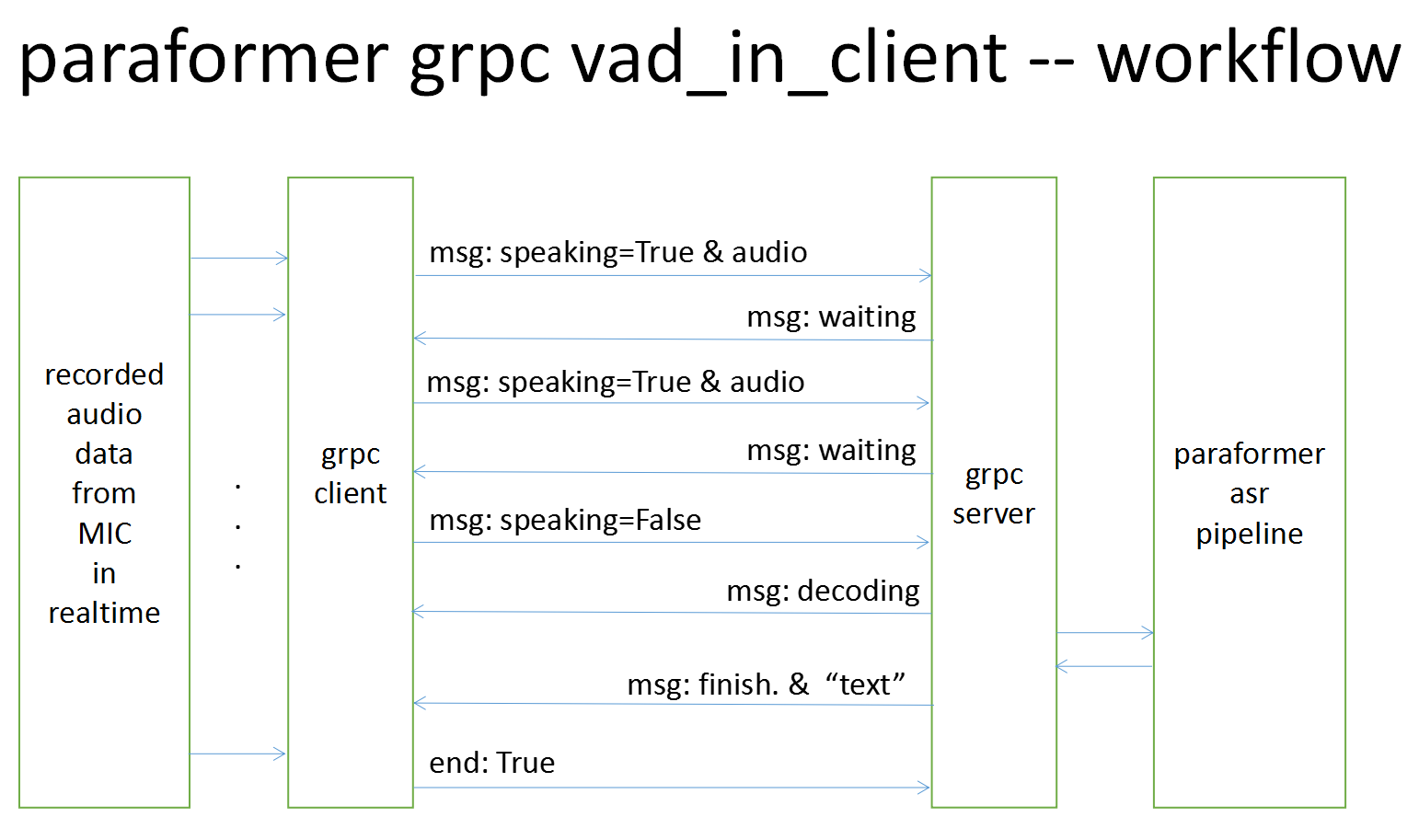
| | | ## Workflow in desgin |
|---|
| | |  |
|---|
| | | |
|---|
| | | |
|---|
| | | ## Reference |
|---|
| | | We borrow or refer to some code from: |
|---|
| | | |
|---|
| | | 1)https://github.com/wenet-e2e/wenet/tree/main/runtime/core/grpc |
|---|
| | | |
|---|
| | | 2)https://github.com/Open-Speech-EkStep/inference_service/blob/main/realtime_inference_service.py |
|---|
| New file |
| | |
|---|
| | | import queue |
|---|
| | | import paraformer_pb2 |
|---|
| | | |
|---|
| | | def transcribe_audio_bytes(stub, chunk, user='zksz', language='zh-CN', speaking = True, isEnd = False): |
|---|
| | | req = paraformer_pb2.Request() |
|---|
| | | if chunk is not None: |
|---|
| | | req.audio_data = chunk |
|---|
| | | req.user = user |
|---|
| | | req.language = language |
|---|
| | | req.speaking = speaking |
|---|
| | | req.isEnd = isEnd |
|---|
| | | my_queue = queue.SimpleQueue() |
|---|
| | | my_queue.put(req) |
|---|
| | | return stub.Recognize(iter(my_queue.get, None)) |
|---|
| | | |
|---|
| | | |
|---|
| | | |
|---|
| New file |
| | |
|---|
| | | import pyaudio |
|---|
| | | import grpc |
|---|
| | | import json |
|---|
| | | import webrtcvad |
|---|
| | | import time |
|---|
| | | import asyncio |
|---|
| | | import argparse |
|---|
| | | |
|---|
| | | from grpc_client import transcribe_audio_bytes |
|---|
| | | from paraformer_pb2_grpc import ASRStub |
|---|
| | | |
|---|
| | | async def deal_chunk(sig_mic): |
|---|
| | | global stub,SPEAKING,asr_user,language,sample_rate |
|---|
| | | if vad.is_speech(sig_mic, sample_rate): #speaking |
|---|
| | | SPEAKING = True |
|---|
| | | response = transcribe_audio_bytes(stub, sig_mic, user=asr_user, language=language, speaking = True, isEnd = False) #speaking, send audio to server. |
|---|
| | | else: #silence |
|---|
| | | begin_time = 0 |
|---|
| | | if SPEAKING: #means we have some audio recorded, send recognize order to server. |
|---|
| | | SPEAKING = False |
|---|
| | | begin_time = int(round(time.time() * 1000)) |
|---|
| | | response = transcribe_audio_bytes(stub, None, user=asr_user, language=language, speaking = False, isEnd = False) #speak end, call server for recognize one sentence |
|---|
| | | resp = response.next() |
|---|
| | | if "decoding" == resp.action: |
|---|
| | | resp = response.next() #TODO, blocking operation may leads to miss some audio clips. C++ multi-threading is preferred. |
|---|
| | | if "finish" == resp.action: |
|---|
| | | end_time = int(round(time.time() * 1000)) |
|---|
| | | print (json.loads(resp.sentence)) |
|---|
| | | print ("delay in ms: %d " % (end_time - begin_time)) |
|---|
| | | else: |
|---|
| | | pass |
|---|
| | | |
|---|
| | | |
|---|
| | | async def record(host,port,sample_rate,mic_chunk,record_seconds,asr_user,language): |
|---|
| | | with grpc.insecure_channel('{}:{}'.format(host, port)) as channel: |
|---|
| | | global stub |
|---|
| | | stub = ASRStub(channel) |
|---|
| | | for i in range(0, int(sample_rate / mic_chunk * record_seconds)): |
|---|
| | | |
|---|
| | | sig_mic = stream.read(mic_chunk,exception_on_overflow = False) |
|---|
| | | await asyncio.create_task(deal_chunk(sig_mic)) |
|---|
| | | |
|---|
| | | #end grpc |
|---|
| | | response = transcribe_audio_bytes(stub, None, user=asr_user, language=language, speaking = False, isEnd = True) |
|---|
| | | print (response.next().action) |
|---|
| | | |
|---|
| | | |
|---|
| | | if __name__ == '__main__': |
|---|
| | | parser = argparse.ArgumentParser() |
|---|
| | | parser.add_argument("--host", |
|---|
| | | type=str, |
|---|
| | | default="127.0.0.1", |
|---|
| | | required=True, |
|---|
| | | help="grpc server host ip") |
|---|
| | | |
|---|
| | | parser.add_argument("--port", |
|---|
| | | type=int, |
|---|
| | | default=10095, |
|---|
| | | required=True, |
|---|
| | | help="grpc server port") |
|---|
| | | |
|---|
| | | parser.add_argument("--user_allowed", |
|---|
| | | type=str, |
|---|
| | | default="project1_user1", |
|---|
| | | help="allowed user for grpc client") |
|---|
| | | |
|---|
| | | parser.add_argument("--sample_rate", |
|---|
| | | type=int, |
|---|
| | | default=16000, |
|---|
| | | help="audio sample_rate from client") |
|---|
| | | |
|---|
| | | parser.add_argument("--mic_chunk", |
|---|
| | | type=int, |
|---|
| | | default=160, |
|---|
| | | help="chunk size for mic") |
|---|
| | | |
|---|
| | | parser.add_argument("--record_seconds", |
|---|
| | | type=int, |
|---|
| | | default=120, |
|---|
| | | help="run specified seconds then exit ") |
|---|
| | | |
|---|
| | | args = parser.parse_args() |
|---|
| | | |
|---|
| | | |
|---|
| | | SPEAKING = False |
|---|
| | | asr_user = args.user_allowed |
|---|
| | | sample_rate = args.sample_rate |
|---|
| | | language = 'zh-CN' |
|---|
| | | |
|---|
| | | |
|---|
| | | vad = webrtcvad.Vad() |
|---|
| | | vad.set_mode(1) |
|---|
| | | |
|---|
| | | FORMAT = pyaudio.paInt16 |
|---|
| | | CHANNELS = 1 |
|---|
| | | p = pyaudio.PyAudio() |
|---|
| | | |
|---|
| | | stream = p.open(format=FORMAT, |
|---|
| | | channels=CHANNELS, |
|---|
| | | rate=args.sample_rate, |
|---|
| | | input=True, |
|---|
| | | frames_per_buffer=args.mic_chunk) |
|---|
| | | |
|---|
| | | print("* recording") |
|---|
| | | asyncio.run(record(args.host,args.port,args.sample_rate,args.mic_chunk,args.record_seconds,args.user_allowed,language)) |
|---|
| | | stream.stop_stream() |
|---|
| | | stream.close() |
|---|
| | | p.terminate() |
|---|
| | | print("recording stop") |
|---|
| | | |
|---|
| | | |
|---|
| | | |
|---|
| New file |
| | |
|---|
| | | import grpc |
|---|
| | | from concurrent import futures |
|---|
| | | import argparse |
|---|
| | | |
|---|
| | | import paraformer_pb2_grpc |
|---|
| | | from grpc_server import ASRServicer |
|---|
| | | |
|---|
| | | def serve(args): |
|---|
| | | server = grpc.server(futures.ThreadPoolExecutor(max_workers=10), |
|---|
| | | # interceptors=(AuthInterceptor('Bearer mysecrettoken'),) |
|---|
| | | ) |
|---|
| | | paraformer_pb2_grpc.add_ASRServicer_to_server(ASRServicer(args.user_allowed, args.model, args.sample_rate), server) |
|---|
| | | port = "[::]:" + str(args.port) |
|---|
| | | server.add_insecure_port(port) |
|---|
| | | server.start() |
|---|
| | | print("grpc server started!") |
|---|
| | | server.wait_for_termination() |
|---|
| | | |
|---|
| | | if __name__ == '__main__': |
|---|
| | | parser = argparse.ArgumentParser() |
|---|
| | | parser.add_argument("--port", |
|---|
| | | type=int, |
|---|
| | | default=10095, |
|---|
| | | required=True, |
|---|
| | | help="grpc server port") |
|---|
| | | |
|---|
| | | parser.add_argument("--user_allowed", |
|---|
| | | type=str, |
|---|
| | | default="project1_user1|project1_user2|project2_user3", |
|---|
| | | help="allowed user for grpc client") |
|---|
| | | |
|---|
| | | parser.add_argument("--model", |
|---|
| | | type=str, |
|---|
| | | default="damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch", |
|---|
| | | help="model from modelscope") |
|---|
| | | |
|---|
| | | parser.add_argument("--sample_rate", |
|---|
| | | type=int, |
|---|
| | | default=16000, |
|---|
| | | help="audio sample_rate from client") |
|---|
| | | |
|---|
| | | |
|---|
| | | |
|---|
| | | args = parser.parse_args() |
|---|
| | | |
|---|
| | | serve(args) |
|---|
| New file |
| | |
|---|
| | | from concurrent import futures |
|---|
| | | import grpc |
|---|
| | | import json |
|---|
| | | import time |
|---|
| | | |
|---|
| | | from modelscope.pipelines import pipeline |
|---|
| | | from modelscope.utils.constant import Tasks |
|---|
| | | import paraformer_pb2_grpc |
|---|
| | | from paraformer_pb2 import Response |
|---|
| | | |
|---|
| | | |
|---|
| | | class ASRServicer(paraformer_pb2_grpc.ASRServicer): |
|---|
| | | def __init__(self, user_allowed, model, sample_rate): |
|---|
| | | print("ASRServicer init") |
|---|
| | | self.init_flag = 0 |
|---|
| | | self.client_buffers = {} |
|---|
| | | self.client_transcription = {} |
|---|
| | | self.auth_user = user_allowed.split("|") |
|---|
| | | self.inference_16k_pipeline = pipeline(task=Tasks.auto_speech_recognition, model=model) |
|---|
| | | self.sample_rate = sample_rate |
|---|
| | | |
|---|
| | | def clear_states(self, user): |
|---|
| | | self.clear_buffers(user) |
|---|
| | | self.clear_transcriptions(user) |
|---|
| | | |
|---|
| | | def clear_buffers(self, user): |
|---|
| | | if user in self.client_buffers: |
|---|
| | | del self.client_buffers[user] |
|---|
| | | |
|---|
| | | def clear_transcriptions(self, user): |
|---|
| | | if user in self.client_transcription: |
|---|
| | | del self.client_transcription[user] |
|---|
| | | |
|---|
| | | def disconnect(self, user): |
|---|
| | | self.clear_states(user) |
|---|
| | | print("Disconnecting user: %s" % str(user)) |
|---|
| | | |
|---|
| | | def Recognize(self, request_iterator, context): |
|---|
| | | |
|---|
| | | |
|---|
| | | for req in request_iterator: |
|---|
| | | if req.user not in self.auth_user: |
|---|
| | | result = {} |
|---|
| | | result["success"] = False |
|---|
| | | result["detail"] = "Not Authorized user: %s " % req.user |
|---|
| | | result["text"] = "" |
|---|
| | | yield Response(sentence=json.dumps(result), user=req.user, action="terminate", language=req.language) |
|---|
| | | elif req.isEnd: #end grpc |
|---|
| | | print("asr end") |
|---|
| | | self.disconnect(req.user) |
|---|
| | | result = {} |
|---|
| | | result["success"] = True |
|---|
| | | result["detail"] = "asr end" |
|---|
| | | result["text"] = "" |
|---|
| | | yield Response(sentence=json.dumps(result), user=req.user, action="terminate",language=req.language) |
|---|
| | | elif req.speaking: #continue speaking |
|---|
| | | if req.audio_data is not None and len(req.audio_data) > 0: |
|---|
| | | if req.user in self.client_buffers: |
|---|
| | | self.client_buffers[req.user] += req.audio_data #append audio |
|---|
| | | else: |
|---|
| | | self.client_buffers[req.user] = req.audio_data |
|---|
| | | result = {} |
|---|
| | | result["success"] = True |
|---|
| | | result["detail"] = "speaking" |
|---|
| | | result["text"] = "" |
|---|
| | | yield Response(sentence=json.dumps(result), user=req.user, action="speaking", language=req.language) |
|---|
| | | elif not req.speaking: #silence |
|---|
| | | if req.user not in self.client_buffers: |
|---|
| | | result = {} |
|---|
| | | result["success"] = True |
|---|
| | | result["detail"] = "waiting_for_more_voice" |
|---|
| | | result["text"] = "" |
|---|
| | | yield Response(sentence=json.dumps(result), user=req.user, action="waiting", language=req.language) |
|---|
| | | else: |
|---|
| | | begin_time = int(round(time.time() * 1000)) |
|---|
| | | tmp_data = self.client_buffers[req.user] |
|---|
| | | self.clear_states(req.user) |
|---|
| | | result = {} |
|---|
| | | result["success"] = True |
|---|
| | | result["detail"] = "decoding data: %d bytes" % len(tmp_data) |
|---|
| | | result["text"] = "" |
|---|
| | | yield Response(sentence=json.dumps(result), user=req.user, action="decoding", language=req.language) |
|---|
| | | if len(tmp_data) < 9600: #min input_len for asr model , 300ms |
|---|
| | | end_time = int(round(time.time() * 1000)) |
|---|
| | | delay_str = str(end_time - begin_time) |
|---|
| | | result = {} |
|---|
| | | result["success"] = True |
|---|
| | | result["detail"] = "waiting_for_more_voice" |
|---|
| | | result["server_delay_ms"] = delay_str |
|---|
| | | result["text"] = "" |
|---|
| | | print ("user: %s , delay(ms): %s, info: %s " % (req.user, delay_str, "waiting_for_more_voice")) |
|---|
| | | yield Response(sentence=json.dumps(result), user=req.user, action="waiting", language=req.language) |
|---|
| | | else: |
|---|
| | | asr_result = self.inference_16k_pipeline(audio_in=tmp_data, audio_fs = self.sample_rate) |
|---|
| | | if "text" in asr_result: |
|---|
| | | asr_result = asr_result['text'] |
|---|
| | | else: |
|---|
| | | asr_result = "" |
|---|
| | | end_time = int(round(time.time() * 1000)) |
|---|
| | | delay_str = str(end_time - begin_time) |
|---|
| | | print ("user: %s , delay(ms): %s, text: %s " % (req.user, delay_str, asr_result)) |
|---|
| | | result = {} |
|---|
| | | result["success"] = True |
|---|
| | | result["detail"] = "finish_sentence" |
|---|
| | | result["server_delay_ms"] = delay_str |
|---|
| | | result["text"] = asr_result |
|---|
| | | yield Response(sentence=json.dumps(result), user=req.user, action="finish", language=req.language) |
|---|
| | | else: |
|---|
| | | result = {} |
|---|
| | | result["success"] = False |
|---|
| | | result["detail"] = "error, no condition matched! Unknown reason." |
|---|
| | | result["text"] = "" |
|---|
| | | self.disconnect(req.user) |
|---|
| | | yield Response(sentence=json.dumps(result), user=req.user, action="terminate", language=req.language) |
|---|
| | | |
|---|
| | | |
|---|
| New file |
| | |
|---|
| | | # -*- coding: utf-8 -*- |
|---|
| | | # Generated by the protocol buffer compiler. DO NOT EDIT! |
|---|
| | | # source: paraformer.proto |
|---|
| | | """Generated protocol buffer code.""" |
|---|
| | | from google.protobuf.internal import builder as _builder |
|---|
| | | from google.protobuf import descriptor as _descriptor |
|---|
| | | from google.protobuf import descriptor_pool as _descriptor_pool |
|---|
| | | from google.protobuf import symbol_database as _symbol_database |
|---|
| | | # @@protoc_insertion_point(imports) |
|---|
| | | |
|---|
| | | _sym_db = _symbol_database.Default() |
|---|
| | | |
|---|
| | | |
|---|
| | | |
|---|
| | | |
|---|
| | | DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(b'\n\x10paraformer.proto\x12\nparaformer\"^\n\x07Request\x12\x12\n\naudio_data\x18\x01 \x01(\x0c\x12\x0c\n\x04user\x18\x02 \x01(\t\x12\x10\n\x08language\x18\x03 \x01(\t\x12\x10\n\x08speaking\x18\x04 \x01(\x08\x12\r\n\x05isEnd\x18\x05 \x01(\x08\"L\n\x08Response\x12\x10\n\x08sentence\x18\x01 \x01(\t\x12\x0c\n\x04user\x18\x02 \x01(\t\x12\x10\n\x08language\x18\x03 \x01(\t\x12\x0e\n\x06\x61\x63tion\x18\x04 \x01(\t2C\n\x03\x41SR\x12<\n\tRecognize\x12\x13.paraformer.Request\x1a\x14.paraformer.Response\"\x00(\x01\x30\x01\x42\x16\n\x07\x65x.grpc\xa2\x02\nparaformerb\x06proto3') |
|---|
| | | |
|---|
| | | _builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, globals()) |
|---|
| | | _builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, 'paraformer_pb2', globals()) |
|---|
| | | if _descriptor._USE_C_DESCRIPTORS == False: |
|---|
| | | |
|---|
| | | DESCRIPTOR._options = None |
|---|
| | | DESCRIPTOR._serialized_options = b'\n\007ex.grpc\242\002\nparaformer' |
|---|
| | | _REQUEST._serialized_start=32 |
|---|
| | | _REQUEST._serialized_end=126 |
|---|
| | | _RESPONSE._serialized_start=128 |
|---|
| | | _RESPONSE._serialized_end=204 |
|---|
| | | _ASR._serialized_start=206 |
|---|
| | | _ASR._serialized_end=273 |
|---|
| | | # @@protoc_insertion_point(module_scope) |
|---|
| New file |
| | |
|---|
| | | # Generated by the gRPC Python protocol compiler plugin. DO NOT EDIT! |
|---|
| | | """Client and server classes corresponding to protobuf-defined services.""" |
|---|
| | | import grpc |
|---|
| | | |
|---|
| | | import paraformer_pb2 as paraformer__pb2 |
|---|
| | | |
|---|
| | | |
|---|
| | | class ASRStub(object): |
|---|
| | | """Missing associated documentation comment in .proto file.""" |
|---|
| | | |
|---|
| | | def __init__(self, channel): |
|---|
| | | """Constructor. |
|---|
| | | |
|---|
| | | Args: |
|---|
| | | channel: A grpc.Channel. |
|---|
| | | """ |
|---|
| | | self.Recognize = channel.stream_stream( |
|---|
| | | '/paraformer.ASR/Recognize', |
|---|
| | | request_serializer=paraformer__pb2.Request.SerializeToString, |
|---|
| | | response_deserializer=paraformer__pb2.Response.FromString, |
|---|
| | | ) |
|---|
| | | |
|---|
| | | |
|---|
| | | class ASRServicer(object): |
|---|
| | | """Missing associated documentation comment in .proto file.""" |
|---|
| | | |
|---|
| | | def Recognize(self, request_iterator, context): |
|---|
| | | """Missing associated documentation comment in .proto file.""" |
|---|
| | | context.set_code(grpc.StatusCode.UNIMPLEMENTED) |
|---|
| | | context.set_details('Method not implemented!') |
|---|
| | | raise NotImplementedError('Method not implemented!') |
|---|
| | | |
|---|
| | | |
|---|
| | | def add_ASRServicer_to_server(servicer, server): |
|---|
| | | rpc_method_handlers = { |
|---|
| | | 'Recognize': grpc.stream_stream_rpc_method_handler( |
|---|
| | | servicer.Recognize, |
|---|
| | | request_deserializer=paraformer__pb2.Request.FromString, |
|---|
| | | response_serializer=paraformer__pb2.Response.SerializeToString, |
|---|
| | | ), |
|---|
| | | } |
|---|
| | | generic_handler = grpc.method_handlers_generic_handler( |
|---|
| | | 'paraformer.ASR', rpc_method_handlers) |
|---|
| | | server.add_generic_rpc_handlers((generic_handler,)) |
|---|
| | | |
|---|
| | | |
|---|
| | | # This class is part of an EXPERIMENTAL API. |
|---|
| | | class ASR(object): |
|---|
| | | """Missing associated documentation comment in .proto file.""" |
|---|
| | | |
|---|
| | | @staticmethod |
|---|
| | | def Recognize(request_iterator, |
|---|
| | | target, |
|---|
| | | options=(), |
|---|
| | | channel_credentials=None, |
|---|
| | | call_credentials=None, |
|---|
| | | insecure=False, |
|---|
| | | compression=None, |
|---|
| | | wait_for_ready=None, |
|---|
| | | timeout=None, |
|---|
| | | metadata=None): |
|---|
| | | return grpc.experimental.stream_stream(request_iterator, target, '/paraformer.ASR/Recognize', |
|---|
| | | paraformer__pb2.Request.SerializeToString, |
|---|
| | | paraformer__pb2.Response.FromString, |
|---|
| | | options, channel_credentials, |
|---|
| | | insecure, call_credentials, compression, wait_for_ready, timeout, metadata) |
|---|
| New file |
| | |
|---|
| | | ``` |
|---|
| | | service ASR { //grpc service |
|---|
| | | rpc Recognize (stream Request) returns (stream Response) {} //Stub |
|---|
| | | } |
|---|
| | | |
|---|
| | | message Request { //request data |
|---|
| | | bytes audio_data = 1; //audio data in bytes. |
|---|
| | | string user = 2; //user allowed. |
|---|
| | | string language = 3; //language, zh-CN for now. |
|---|
| | | bool speaking = 4; //flag for speaking. |
|---|
| | | bool isEnd = 5; //flag for end. set isEnd to true when you stop asr: |
|---|
| | | //vad:is_speech then speaking=True & isEnd = False, audio data will be appended for the specfied user. |
|---|
| | | //vad:silence then speaking=False & isEnd = False, clear audio buffer and do asr inference. |
|---|
| | | } |
|---|
| | | |
|---|
| | | message Response { //response data. |
|---|
| | | string sentence = 1; //json, includes flag for success and asr text . |
|---|
| | | string user = 2; //same to request user. |
|---|
| | | string language = 3; //same to request language. |
|---|
| | | string action = 4; //server status: |
|---|
| | | //terminate:asr stopped; |
|---|
| | | //speaking:user is speaking, audio data is appended; |
|---|
| | | //decoding: server is decoding; |
|---|
| | | //finish: get asr text, most used. |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | // Copyright (c) 2021 Ximalaya Speech Team (Xiang Lyu) |
|---|
| | | // |
|---|
| | | // Licensed under the Apache License, Version 2.0 (the "License"); |
|---|
| | | // you may not use this file except in compliance with the License. |
|---|
| | | // You may obtain a copy of the License at |
|---|
| | | // |
|---|
| | | // http://www.apache.org/licenses/LICENSE-2.0 |
|---|
| | | // |
|---|
| | | // Unless required by applicable law or agreed to in writing, software |
|---|
| | | // distributed under the License is distributed on an "AS IS" BASIS, |
|---|
| | | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. |
|---|
| | | // See the License for the specific language governing permissions and |
|---|
| | | // limitations under the License. |
|---|
| | | syntax = "proto3"; |
|---|
| | | |
|---|
| | | option java_package = "ex.grpc"; |
|---|
| | | option objc_class_prefix = "paraformer"; |
|---|
| | | |
|---|
| | | package paraformer; |
|---|
| | | |
|---|
| | | service ASR { |
|---|
| | | rpc Recognize (stream Request) returns (stream Response) {} |
|---|
| | | } |
|---|
| | | |
|---|
| | | message Request { |
|---|
| | | bytes audio_data = 1; |
|---|
| | | string user = 2; |
|---|
| | | string language = 3; |
|---|
| | | bool speaking = 4; |
|---|
| | | bool isEnd = 5; |
|---|
| | | } |
|---|
| | | |
|---|
| | | message Response { |
|---|
| | | string sentence = 1; |
|---|
| | | string user = 2; |
|---|
| | | string language = 3; |
|---|
| | | string action = 4; |
|---|
| | | } |
|---|


{kind=link}