| | |
|---|
| | | # FunASR-1.x.x 注册模型教程 |
|---|
| | | # FunASR-1.x.x 注册模型教程 |
|---|
| | | |
|---|
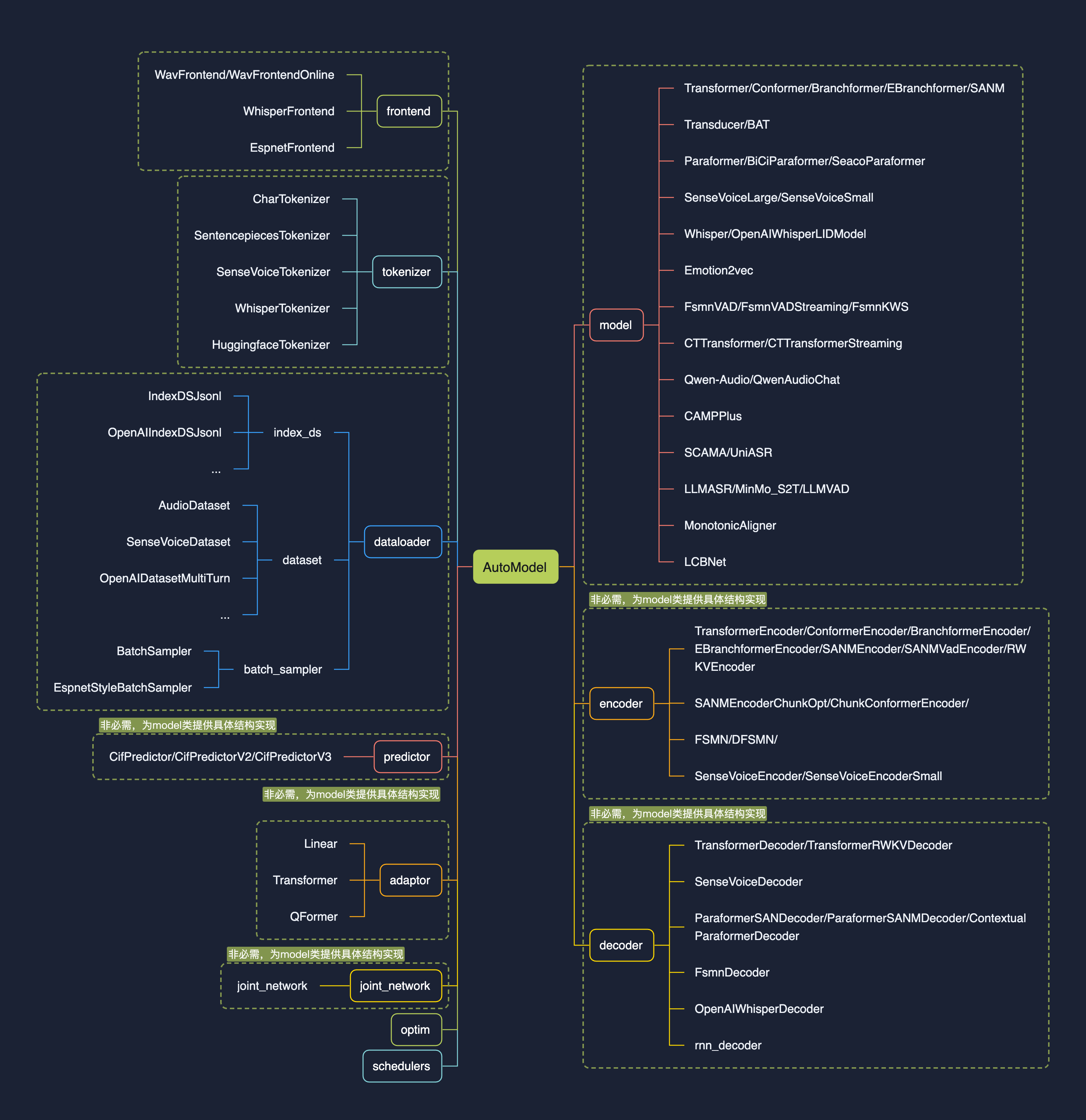
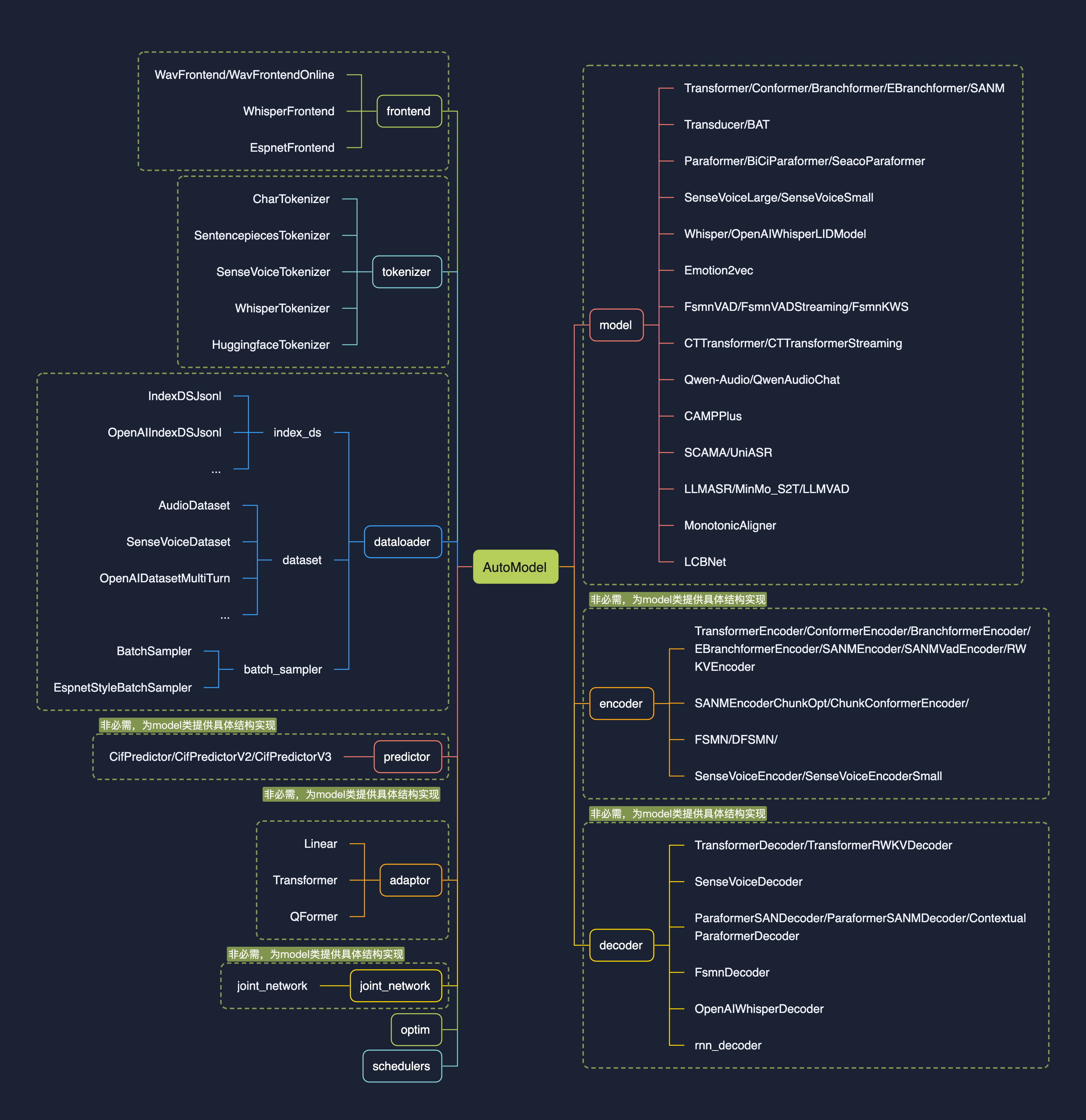
| | | 1.0版本的设计初衷是【**让模型集成更简单**】,核心feature为注册表与AutoModel: |
|---|
| | | |
|---|
| | |
|---|
| | | * 统一学术与工业模型推理训练脚本; |
|---|
| | | |
|---|
| | | |
|---|
| | |  |
|---|
| | |  |
|---|
| | | |
|---|
| | | # 快速上手 |
|---|
| | | |
|---|
| | |
|---|
| | | res = model.generate(input=[str], output_dir=[str]) |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | * wav文件路径, 例如: asr\_example.wav |
|---|
| | | |
|---|
| | | * pcm文件路径, 例如: asr\_example.pcm,此时需要指定音频采样率fs(默认为16000) |
|---|
| | | |
|---|
| | | * 音频字节数流,例如:麦克风的字节数数据 |
|---|
| | | |
|---|
| | | * wav.scp,kaldi 样式的 wav 列表 (`wav_id \t wav_path`), 例如: |
|---|
| | | |
|---|
| | | * * wav文件路径, 例如: asr\_example.wav |
|---|
| | | |
|---|
| | | * pcm文件路径, 例如: asr\_example.pcm,此时需要指定音频采样率fs(默认为16000) |
|---|
| | | |
|---|
| | | * 音频字节数流,例如:麦克风的字节数数据 |
|---|
| | | |
|---|
| | | * wav.scp,kaldi 样式的 wav 列表 (`wav_id \t wav_path`), 例如: |
|---|
| | | |
|---|
| | | |
|---|
| | | ```plaintext |
|---|
| | | asr_example1 ./audios/asr_example1.wav |
|---|
| | |
|---|
| | | |
|---|
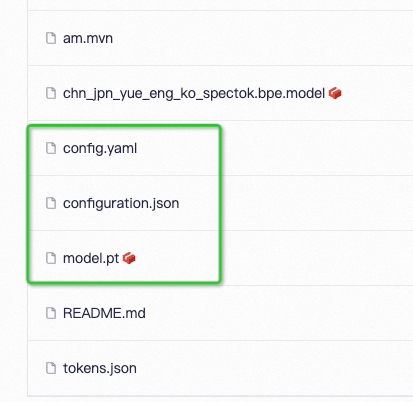
| | | ## 模型资源目录 |
|---|
| | | |
|---|
| | |  |
|---|
| | |  |
|---|
| | | |
|---|
| | | **模型链接为:**[https://www.modelscope.cn/models/iic/SenseVoiceSmall/files](https://www.modelscope.cn/models/iic/SenseVoiceSmall/files) |
|---|
| | | |
|---|
| | | **配置文件**:config.yaml |
|---|
| | | |
|---|
| | | ```yaml |
|---|
| | | model: SenseVoiceLarge |
|---|
| | | model_conf: |
|---|
| | | lsm_weight: 0.1 |
|---|
| | | length_normalized_loss: true |
|---|
| | | activation_checkpoint: true |
|---|
| | | sos: <|startoftranscript|> |
|---|
| | | eos: <|endoftext|> |
|---|
| | | downsample_rate: 4 |
|---|
| | | use_padmask: true |
|---|
| | | |
|---|
| | | encoder: SenseVoiceEncoder |
|---|
| | | encoder: SenseVoiceEncoderSmall |
|---|
| | | encoder_conf: |
|---|
| | | input_size: 128 |
|---|
| | | attention_heads: 20 |
|---|
| | | linear_units: 1280 |
|---|
| | | num_blocks: 32 |
|---|
| | | dropout_rate: 0.1 |
|---|
| | | positional_dropout_rate: 0.1 |
|---|
| | | attention_dropout_rate: 0.1 |
|---|
| | | kernel_size: 31 |
|---|
| | | sanm_shfit: 0 |
|---|
| | | att_type: self_att_fsmn_sdpa |
|---|
| | | downsample_rate: 4 |
|---|
| | | use_padmask: true |
|---|
| | | max_position_embeddings: 2048 |
|---|
| | | rope_theta: 10000 |
|---|
| | | |
|---|
| | | frontend: WhisperFrontend |
|---|
| | | frontend_conf: |
|---|
| | | fs: 16000 |
|---|
| | | n_mels: 128 |
|---|
| | | do_pad_trim: false |
|---|
| | | filters_path: null |
|---|
| | | output_size: 512 |
|---|
| | | attention_heads: 4 |
|---|
| | | linear_units: 2048 |
|---|
| | | num_blocks: 50 |
|---|
| | | tp_blocks: 20 |
|---|
| | | dropout_rate: 0.1 |
|---|
| | | positional_dropout_rate: 0.1 |
|---|
| | | attention_dropout_rate: 0.1 |
|---|
| | | input_layer: pe |
|---|
| | | pos_enc_class: SinusoidalPositionEncoder |
|---|
| | | normalize_before: true |
|---|
| | | kernel_size: 11 |
|---|
| | | sanm_shfit: 0 |
|---|
| | | selfattention_layer_type: sanm |
|---|
| | | |
|---|
| | | tokenizer: SenseVoiceTokenizer |
|---|
| | | |
|---|
| | | model: SenseVoiceSmall |
|---|
| | | model_conf: |
|---|
| | | length_normalized_loss: true |
|---|
| | | sos: 1 |
|---|
| | | eos: 2 |
|---|
| | | ignore_id: -1 |
|---|
| | | |
|---|
| | | tokenizer: SentencepiecesTokenizer |
|---|
| | | tokenizer_conf: |
|---|
| | | vocab_path: null |
|---|
| | | is_multilingual: true |
|---|
| | | num_languages: 8749 |
|---|
| | | bpemodel: null |
|---|
| | | unk_symbol: <unk> |
|---|
| | | split_with_space: true |
|---|
| | | |
|---|
| | | dataset: SenseVoiceDataset |
|---|
| | | frontend: WavFrontend |
|---|
| | | frontend_conf: |
|---|
| | | fs: 16000 |
|---|
| | | window: hamming |
|---|
| | | n_mels: 80 |
|---|
| | | frame_length: 25 |
|---|
| | | frame_shift: 10 |
|---|
| | | lfr_m: 7 |
|---|
| | | lfr_n: 6 |
|---|
| | | cmvn_file: null |
|---|
| | | |
|---|
| | | |
|---|
| | | dataset: SenseVoiceCTCDataset |
|---|
| | | dataset_conf: |
|---|
| | | index_ds: IndexDSJsonl |
|---|
| | | batch_sampler: BatchSampler |
|---|
| | | batch_sampler: EspnetStyleBatchSampler |
|---|
| | | data_split_num: 32 |
|---|
| | | batch_type: token |
|---|
| | | batch_size: 12000 |
|---|
| | | sort_size: 64 |
|---|
| | | batch_size: 14000 |
|---|
| | | max_token_length: 2000 |
|---|
| | | min_token_length: 60 |
|---|
| | | max_source_length: 2000 |
|---|
| | | min_source_length: 60 |
|---|
| | | max_target_length: 150 |
|---|
| | | max_target_length: 200 |
|---|
| | | min_target_length: 0 |
|---|
| | | shuffle: true |
|---|
| | | num_workers: 4 |
|---|
| | | sos: ${model_conf.sos} |
|---|
| | | eos: ${model_conf.eos} |
|---|
| | | IndexDSJsonl: IndexDSJsonl |
|---|
| | | retry: 20 |
|---|
| | | |
|---|
| | | train_conf: |
|---|
| | | accum_grad: 1 |
|---|
| | | grad_clip: 5 |
|---|
| | | max_epoch: 5 |
|---|
| | | keep_nbest_models: 200 |
|---|
| | | avg_nbest_model: 200 |
|---|
| | | max_epoch: 20 |
|---|
| | | keep_nbest_models: 10 |
|---|
| | | avg_nbest_model: 10 |
|---|
| | | log_interval: 100 |
|---|
| | | resume: true |
|---|
| | | validate_interval: 10000 |
|---|
| | |
|---|
| | | |
|---|
| | | optim: adamw |
|---|
| | | optim_conf: |
|---|
| | | lr: 2.5e-05 |
|---|
| | | |
|---|
| | | lr: 0.00002 |
|---|
| | | scheduler: warmuplr |
|---|
| | | scheduler_conf: |
|---|
| | | warmup_steps: 20000 |
|---|
| | | warmup_steps: 25000 |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | |
|---|
| | |
|---|
| | | "file_path_metas": { |
|---|
| | | "init_param":"model.pt", |
|---|
| | | "config":"config.yaml", |
|---|
| | | "tokenizer_conf": {"vocab_path": "tokens.tiktoken"}, |
|---|
| | | "frontend_conf":{"filters_path": "mel_filters.npz"}} |
|---|
| | | "tokenizer_conf": {"bpemodel": "chn_jpn_yue_eng_ko_spectok.bpe.model"}, |
|---|
| | | "frontend_conf":{"cmvn_file": "am.mvn"}} |
|---|
| | | } |
|---|
| | | ``` |
|---|
| | | |
|---|
| | |
|---|
| | | |
|---|
| | | ### 查看注册表 |
|---|
| | | |
|---|
| | | ```python |
|---|
| | | ```plaintext |
|---|
| | | from funasr.register import tables |
|---|
| | | |
|---|
| | | tables.print() |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | 支持查看指定类型的注册表:`tables.print("model")` |
|---|
| | | 支持查看指定类型的注册表:\`tables.print("model")\` |
|---|
| | | |
|---|
| | | |
|---|
| | | ### 新注册 |
|---|
| | | ### 注册模型 |
|---|
| | | |
|---|
| | | ```python |
|---|
| | | from funasr.register import tables |
|---|
| | | |
|---|
| | | @tables.register("model_classes", "MinMo_S2T") |
|---|
| | | class MinMo_S2T(nn.Module): |
|---|
| | | @tables.register("model_classes", "SenseVoiceSmall") |
|---|
| | | class SenseVoiceSmall(nn.Module): |
|---|
| | | def __init__(*args, **kwargs): |
|---|
| | | ... |
|---|
| | | |
|---|
| | |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | 在config.yaml中指定新注册模型 |
|---|
| | | 在需要注册的类名前加上 `@tables.register("model_classes","SenseVoiceSmall")`,即可完成注册,类需要实现有:__init__,forward,inference方法。 |
|---|
| | | |
|---|
| | | ```yaml |
|---|
| | | model: MinMo_S2T |
|---|
| | | 完整代码:[https://github.com/modelscope/FunASR/blob/main/funasr/models/sense\_voice/model.py#L443](https://github.com/modelscope/FunASR/blob/main/funasr/models/sense_voice/model.py#L443) |
|---|
| | | |
|---|
| | | 注册完成后,在config.yaml中指定新注册模型,即可实现对模型的定义 |
|---|
| | | |
|---|
| | | ```python |
|---|
| | | model: SenseVoiceSmall |
|---|
| | | model_conf: |
|---|
| | | ... |
|---|
| | | ``` |
|---|

