
README.md
@@ -20,9 +20,18 @@ | [**M2MET2.0 Challenge**](https://github.com/alibaba-damo-academy/FunASR#multi-channel-multi-party-meeting-transcription-20-m2met20-challenge) ## What's new: ### FunASR runtime-SDK - 2023.07.02: We have release the FunASR runtime-SDK-0.1.0, file transcription service (Mandarin) is now supported ([ZH](funasr/runtime/readme_cn.md)/[EN](funasr/runtime/readme.md)) ### Multi-Channel Multi-Party Meeting Transcription 2.0 (M2MeT2.0) Challenge We are pleased to announce that the M2MeT2.0 challenge has been accepted by the ASRU 2023 challenge special session. The registration is now open. The baseline system is conducted on FunASR and is provided as a receipe of AliMeeting corpus. For more details you can see the guidence of M2MET2.0 ([CN](https://alibaba-damo-academy.github.io/FunASR/m2met2_cn/index.html)/[EN](https://alibaba-damo-academy.github.io/FunASR/m2met2/index.html)). ### Release notes For the release notes, please ref to [news](https://github.com/alibaba-damo-academy/FunASR/releases) ## Highlights funasr/bin/asr_inference_launch.py
@@ -1604,6 +1604,8 @@ return inference_mfcca(**kwargs) elif mode == "rnnt": return inference_transducer(**kwargs) elif mode == "bat": return inference_transducer(**kwargs) elif mode == "sa_asr": return inference_sa_asr(**kwargs) else: funasr/build_utils/build_asr_model.py
@@ -26,6 +26,7 @@ from funasr.models.e2e_asr_mfcca import MFCCA from funasr.models.e2e_asr_transducer import TransducerModel, UnifiedTransducerModel from funasr.models.e2e_asr_bat import BATModel from funasr.models.e2e_sa_asr import SAASRModel from funasr.models.e2e_asr_paraformer import Paraformer, ParaformerOnline, ParaformerBert, BiCifParaformer, ContextualParaformer @@ -46,7 +47,7 @@ from funasr.models.frontend.wav_frontend import WavFrontend from funasr.models.frontend.windowing import SlidingWindow from funasr.models.joint_net.joint_network import JointNetwork from funasr.models.predictor.cif import CifPredictor, CifPredictorV2, CifPredictorV3 from funasr.models.predictor.cif import CifPredictor, CifPredictorV2, CifPredictorV3, BATPredictor from funasr.models.specaug.specaug import SpecAug from funasr.models.specaug.specaug import SpecAugLFR from funasr.modules.subsampling import Conv1dSubsampling @@ -99,7 +100,7 @@ rnnt=TransducerModel, rnnt_unified=UnifiedTransducerModel, sa_asr=SAASRModel, bat=BATModel, ), default="asr", ) @@ -188,6 +189,7 @@ ctc_predictor=None, cif_predictor_v2=CifPredictorV2, cif_predictor_v3=CifPredictorV3, bat_predictor=BATPredictor, ), default="cif_predictor", optional=True, @@ -313,12 +315,15 @@ encoder = encoder_class(input_size=input_size, **args.encoder_conf) # decoder decoder_class = decoder_choices.get_class(args.decoder) decoder = decoder_class( vocab_size=vocab_size, encoder_output_size=encoder.output_size(), **args.decoder_conf, ) if hasattr(args, "decoder") and args.decoder is not None: decoder_class = decoder_choices.get_class(args.decoder) decoder = decoder_class( vocab_size=vocab_size, encoder_output_size=encoder.output_size(), **args.decoder_conf, ) else: decoder = None # ctc ctc = CTC( @@ -463,6 +468,53 @@ joint_network=joint_network, **args.model_conf, ) elif args.model == "bat": # 5. Decoder encoder_output_size = encoder.output_size() rnnt_decoder_class = rnnt_decoder_choices.get_class(args.rnnt_decoder) decoder = rnnt_decoder_class( vocab_size, **args.rnnt_decoder_conf, ) decoder_output_size = decoder.output_size if getattr(args, "decoder", None) is not None: att_decoder_class = decoder_choices.get_class(args.decoder) att_decoder = att_decoder_class( vocab_size=vocab_size, encoder_output_size=encoder_output_size, **args.decoder_conf, ) else: att_decoder = None # 6. Joint Network joint_network = JointNetwork( vocab_size, encoder_output_size, decoder_output_size, **args.joint_network_conf, ) predictor_class = predictor_choices.get_class(args.predictor) predictor = predictor_class(**args.predictor_conf) model_class = model_choices.get_class(args.model) # 7. Build model model = model_class( vocab_size=vocab_size, token_list=token_list, frontend=frontend, specaug=specaug, normalize=normalize, encoder=encoder, decoder=decoder, att_decoder=att_decoder, joint_network=joint_network, predictor=predictor, **args.model_conf, ) elif args.model == "sa_asr": asr_encoder_class = asr_encoder_choices.get_class(args.asr_encoder) asr_encoder = asr_encoder_class(input_size=input_size, **args.asr_encoder_conf) funasr/models/e2e_asr_bat.py
New file @@ -0,0 +1,496 @@ """Boundary Aware Transducer (BAT) model.""" import logging from contextlib import contextmanager from typing import Dict, List, Optional, Tuple, Union import torch from packaging.version import parse as V from funasr.losses.label_smoothing_loss import ( LabelSmoothingLoss, # noqa: H301 ) from funasr.models.frontend.abs_frontend import AbsFrontend from funasr.models.specaug.abs_specaug import AbsSpecAug from funasr.models.decoder.rnnt_decoder import RNNTDecoder from funasr.models.decoder.abs_decoder import AbsDecoder as AbsAttDecoder from funasr.models.encoder.abs_encoder import AbsEncoder from funasr.models.joint_net.joint_network import JointNetwork from funasr.modules.nets_utils import get_transducer_task_io from funasr.modules.nets_utils import th_accuracy from funasr.modules.nets_utils import make_pad_mask from funasr.modules.add_sos_eos import add_sos_eos from funasr.layers.abs_normalize import AbsNormalize from funasr.torch_utils.device_funcs import force_gatherable from funasr.models.base_model import FunASRModel if V(torch.__version__) >= V("1.6.0"): from torch.cuda.amp import autocast else: @contextmanager def autocast(enabled=True): yield class BATModel(FunASRModel): """BATModel module definition. Args: vocab_size: Size of complete vocabulary (w/ EOS and blank included). token_list: List of token frontend: Frontend module. specaug: SpecAugment module. normalize: Normalization module. encoder: Encoder module. decoder: Decoder module. joint_network: Joint Network module. transducer_weight: Weight of the Transducer loss. fastemit_lambda: FastEmit lambda value. auxiliary_ctc_weight: Weight of auxiliary CTC loss. auxiliary_ctc_dropout_rate: Dropout rate for auxiliary CTC loss inputs. auxiliary_lm_loss_weight: Weight of auxiliary LM loss. auxiliary_lm_loss_smoothing: Smoothing rate for LM loss' label smoothing. ignore_id: Initial padding ID. sym_space: Space symbol. sym_blank: Blank Symbol report_cer: Whether to report Character Error Rate during validation. report_wer: Whether to report Word Error Rate during validation. extract_feats_in_collect_stats: Whether to use extract_feats stats collection. """ def __init__( self, vocab_size: int, token_list: Union[Tuple[str, ...], List[str]], frontend: Optional[AbsFrontend], specaug: Optional[AbsSpecAug], normalize: Optional[AbsNormalize], encoder: AbsEncoder, decoder: RNNTDecoder, joint_network: JointNetwork, att_decoder: Optional[AbsAttDecoder] = None, predictor = None, transducer_weight: float = 1.0, predictor_weight: float = 1.0, cif_weight: float = 1.0, fastemit_lambda: float = 0.0, auxiliary_ctc_weight: float = 0.0, auxiliary_ctc_dropout_rate: float = 0.0, auxiliary_lm_loss_weight: float = 0.0, auxiliary_lm_loss_smoothing: float = 0.0, ignore_id: int = -1, sym_space: str = "<space>", sym_blank: str = "<blank>", report_cer: bool = True, report_wer: bool = True, extract_feats_in_collect_stats: bool = True, lsm_weight: float = 0.0, length_normalized_loss: bool = False, r_d: int = 5, r_u: int = 5, ) -> None: """Construct an BATModel object.""" super().__init__() # The following labels ID are reserved: 0 (blank) and vocab_size - 1 (sos/eos) self.blank_id = 0 self.vocab_size = vocab_size self.ignore_id = ignore_id self.token_list = token_list.copy() self.sym_space = sym_space self.sym_blank = sym_blank self.frontend = frontend self.specaug = specaug self.normalize = normalize self.encoder = encoder self.decoder = decoder self.joint_network = joint_network self.criterion_transducer = None self.error_calculator = None self.use_auxiliary_ctc = auxiliary_ctc_weight > 0 self.use_auxiliary_lm_loss = auxiliary_lm_loss_weight > 0 if self.use_auxiliary_ctc: self.ctc_lin = torch.nn.Linear(encoder.output_size(), vocab_size) self.ctc_dropout_rate = auxiliary_ctc_dropout_rate if self.use_auxiliary_lm_loss: self.lm_lin = torch.nn.Linear(decoder.output_size, vocab_size) self.lm_loss_smoothing = auxiliary_lm_loss_smoothing self.transducer_weight = transducer_weight self.fastemit_lambda = fastemit_lambda self.auxiliary_ctc_weight = auxiliary_ctc_weight self.auxiliary_lm_loss_weight = auxiliary_lm_loss_weight self.report_cer = report_cer self.report_wer = report_wer self.extract_feats_in_collect_stats = extract_feats_in_collect_stats self.criterion_pre = torch.nn.L1Loss() self.predictor_weight = predictor_weight self.predictor = predictor self.cif_weight = cif_weight if self.cif_weight > 0: self.cif_output_layer = torch.nn.Linear(encoder.output_size(), vocab_size) self.criterion_cif = LabelSmoothingLoss( size=vocab_size, padding_idx=ignore_id, smoothing=lsm_weight, normalize_length=length_normalized_loss, ) self.r_d = r_d self.r_u = r_u def forward( self, speech: torch.Tensor, speech_lengths: torch.Tensor, text: torch.Tensor, text_lengths: torch.Tensor, **kwargs, ) -> Tuple[torch.Tensor, Dict[str, torch.Tensor], torch.Tensor]: """Forward architecture and compute loss(es). Args: speech: Speech sequences. (B, S) speech_lengths: Speech sequences lengths. (B,) text: Label ID sequences. (B, L) text_lengths: Label ID sequences lengths. (B,) kwargs: Contains "utts_id". Return: loss: Main loss value. stats: Task statistics. weight: Task weights. """ assert text_lengths.dim() == 1, text_lengths.shape assert ( speech.shape[0] == speech_lengths.shape[0] == text.shape[0] == text_lengths.shape[0] ), (speech.shape, speech_lengths.shape, text.shape, text_lengths.shape) batch_size = speech.shape[0] text = text[:, : text_lengths.max()] # 1. Encoder encoder_out, encoder_out_lens = self.encode(speech, speech_lengths) if hasattr(self.encoder, 'overlap_chunk_cls') and self.encoder.overlap_chunk_cls is not None: encoder_out, encoder_out_lens = self.encoder.overlap_chunk_cls.remove_chunk(encoder_out, encoder_out_lens, chunk_outs=None) encoder_out_mask = (~make_pad_mask(encoder_out_lens, maxlen=encoder_out.size(1))[:, None, :]).to(encoder_out.device) # 2. Transducer-related I/O preparation decoder_in, target, t_len, u_len = get_transducer_task_io( text, encoder_out_lens, ignore_id=self.ignore_id, ) # 3. Decoder self.decoder.set_device(encoder_out.device) decoder_out = self.decoder(decoder_in, u_len) pre_acoustic_embeds, pre_token_length, _, pre_peak_index = self.predictor(encoder_out, text, encoder_out_mask, ignore_id=self.ignore_id) loss_pre = self.criterion_pre(text_lengths.type_as(pre_token_length), pre_token_length) if self.cif_weight > 0.0: cif_predict = self.cif_output_layer(pre_acoustic_embeds) loss_cif = self.criterion_cif(cif_predict, text) else: loss_cif = 0.0 # 5. Losses boundary = torch.zeros((encoder_out.size(0), 4), dtype=torch.int64, device=encoder_out.device) boundary[:, 2] = u_len.long().detach() boundary[:, 3] = t_len.long().detach() pre_peak_index = torch.floor(pre_peak_index).long() s_begin = pre_peak_index - self.r_d T = encoder_out.size(1) B = encoder_out.size(0) U = decoder_out.size(1) mask = torch.arange(0, T, device=encoder_out.device).reshape(1, T).expand(B, T) mask = mask <= boundary[:, 3].reshape(B, 1) - 1 s_begin_padding = boundary[:, 2].reshape(B, 1) - (self.r_u+self.r_d) + 1 # handle the cases where `len(symbols) < s_range` s_begin_padding = torch.clamp(s_begin_padding, min=0) s_begin = torch.where(mask, s_begin, s_begin_padding) mask2 = s_begin < boundary[:, 2].reshape(B, 1) - (self.r_u+self.r_d) + 1 s_begin = torch.where(mask2, s_begin, boundary[:, 2].reshape(B, 1) - (self.r_u+self.r_d) + 1) s_begin = torch.clamp(s_begin, min=0) ranges = s_begin.reshape((B, T, 1)).expand((B, T, min(self.r_u+self.r_d, min(u_len)))) + torch.arange(min(self.r_d+self.r_u, min(u_len)), device=encoder_out.device) import fast_rnnt am_pruned, lm_pruned = fast_rnnt.do_rnnt_pruning( am=self.joint_network.lin_enc(encoder_out), lm=self.joint_network.lin_dec(decoder_out), ranges=ranges, ) logits = self.joint_network(am_pruned, lm_pruned, project_input=False) with torch.cuda.amp.autocast(enabled=False): loss_trans = fast_rnnt.rnnt_loss_pruned( logits=logits.float(), symbols=target.long(), ranges=ranges, termination_symbol=self.blank_id, boundary=boundary, reduction="sum", ) cer_trans, wer_trans = None, None if not self.training and (self.report_cer or self.report_wer): if self.error_calculator is None: from funasr.modules.e2e_asr_common import ErrorCalculatorTransducer as ErrorCalculator self.error_calculator = ErrorCalculator( self.decoder, self.joint_network, self.token_list, self.sym_space, self.sym_blank, report_cer=self.report_cer, report_wer=self.report_wer, ) cer_trans, wer_trans = self.error_calculator(encoder_out, target, t_len) loss_ctc, loss_lm = 0.0, 0.0 if self.use_auxiliary_ctc: loss_ctc = self._calc_ctc_loss( encoder_out, target, t_len, u_len, ) if self.use_auxiliary_lm_loss: loss_lm = self._calc_lm_loss(decoder_out, target) loss = ( self.transducer_weight * loss_trans + self.auxiliary_ctc_weight * loss_ctc + self.auxiliary_lm_loss_weight * loss_lm + self.predictor_weight * loss_pre + self.cif_weight * loss_cif ) stats = dict( loss=loss.detach(), loss_transducer=loss_trans.detach(), loss_pre=loss_pre.detach(), loss_cif=loss_cif.detach() if loss_cif > 0.0 else None, aux_ctc_loss=loss_ctc.detach() if loss_ctc > 0.0 else None, aux_lm_loss=loss_lm.detach() if loss_lm > 0.0 else None, cer_transducer=cer_trans, wer_transducer=wer_trans, ) # force_gatherable: to-device and to-tensor if scalar for DataParallel loss, stats, weight = force_gatherable((loss, stats, batch_size), loss.device) return loss, stats, weight def collect_feats( self, speech: torch.Tensor, speech_lengths: torch.Tensor, text: torch.Tensor, text_lengths: torch.Tensor, **kwargs, ) -> Dict[str, torch.Tensor]: """Collect features sequences and features lengths sequences. Args: speech: Speech sequences. (B, S) speech_lengths: Speech sequences lengths. (B,) text: Label ID sequences. (B, L) text_lengths: Label ID sequences lengths. (B,) kwargs: Contains "utts_id". Return: {}: "feats": Features sequences. (B, T, D_feats), "feats_lengths": Features sequences lengths. (B,) """ if self.extract_feats_in_collect_stats: feats, feats_lengths = self._extract_feats(speech, speech_lengths) else: # Generate dummy stats if extract_feats_in_collect_stats is False logging.warning( "Generating dummy stats for feats and feats_lengths, " "because encoder_conf.extract_feats_in_collect_stats is " f"{self.extract_feats_in_collect_stats}" ) feats, feats_lengths = speech, speech_lengths return {"feats": feats, "feats_lengths": feats_lengths} def encode( self, speech: torch.Tensor, speech_lengths: torch.Tensor, ) -> Tuple[torch.Tensor, torch.Tensor]: """Encoder speech sequences. Args: speech: Speech sequences. (B, S) speech_lengths: Speech sequences lengths. (B,) Return: encoder_out: Encoder outputs. (B, T, D_enc) encoder_out_lens: Encoder outputs lengths. (B,) """ with autocast(False): # 1. Extract feats feats, feats_lengths = self._extract_feats(speech, speech_lengths) # 2. Data augmentation if self.specaug is not None and self.training: feats, feats_lengths = self.specaug(feats, feats_lengths) # 3. Normalization for feature: e.g. Global-CMVN, Utterance-CMVN if self.normalize is not None: feats, feats_lengths = self.normalize(feats, feats_lengths) # 4. Forward encoder encoder_out, encoder_out_lens, _ = self.encoder(feats, feats_lengths) assert encoder_out.size(0) == speech.size(0), ( encoder_out.size(), speech.size(0), ) assert encoder_out.size(1) <= encoder_out_lens.max(), ( encoder_out.size(), encoder_out_lens.max(), ) return encoder_out, encoder_out_lens def _extract_feats( self, speech: torch.Tensor, speech_lengths: torch.Tensor ) -> Tuple[torch.Tensor, torch.Tensor]: """Extract features sequences and features sequences lengths. Args: speech: Speech sequences. (B, S) speech_lengths: Speech sequences lengths. (B,) Return: feats: Features sequences. (B, T, D_feats) feats_lengths: Features sequences lengths. (B,) """ assert speech_lengths.dim() == 1, speech_lengths.shape # for data-parallel speech = speech[:, : speech_lengths.max()] if self.frontend is not None: feats, feats_lengths = self.frontend(speech, speech_lengths) else: feats, feats_lengths = speech, speech_lengths return feats, feats_lengths def _calc_ctc_loss( self, encoder_out: torch.Tensor, target: torch.Tensor, t_len: torch.Tensor, u_len: torch.Tensor, ) -> torch.Tensor: """Compute CTC loss. Args: encoder_out: Encoder output sequences. (B, T, D_enc) target: Target label ID sequences. (B, L) t_len: Encoder output sequences lengths. (B,) u_len: Target label ID sequences lengths. (B,) Return: loss_ctc: CTC loss value. """ ctc_in = self.ctc_lin( torch.nn.functional.dropout(encoder_out, p=self.ctc_dropout_rate) ) ctc_in = torch.log_softmax(ctc_in.transpose(0, 1), dim=-1) target_mask = target != 0 ctc_target = target[target_mask].cpu() with torch.backends.cudnn.flags(deterministic=True): loss_ctc = torch.nn.functional.ctc_loss( ctc_in, ctc_target, t_len, u_len, zero_infinity=True, reduction="sum", ) loss_ctc /= target.size(0) return loss_ctc def _calc_lm_loss( self, decoder_out: torch.Tensor, target: torch.Tensor, ) -> torch.Tensor: """Compute LM loss. Args: decoder_out: Decoder output sequences. (B, U, D_dec) target: Target label ID sequences. (B, L) Return: loss_lm: LM loss value. """ lm_loss_in = self.lm_lin(decoder_out[:, :-1, :]).view(-1, self.vocab_size) lm_target = target.view(-1).type(torch.int64) with torch.no_grad(): true_dist = lm_loss_in.clone() true_dist.fill_(self.lm_loss_smoothing / (self.vocab_size - 1)) # Ignore blank ID (0) ignore = lm_target == 0 lm_target = lm_target.masked_fill(ignore, 0) true_dist.scatter_(1, lm_target.unsqueeze(1), (1 - self.lm_loss_smoothing)) loss_lm = torch.nn.functional.kl_div( torch.log_softmax(lm_loss_in, dim=1), true_dist, reduction="none", ) loss_lm = loss_lm.masked_fill(ignore.unsqueeze(1), 0).sum() / decoder_out.size( 0 ) return loss_lm funasr/models/e2e_asr_transducer.py
@@ -353,11 +353,6 @@ """ if self.criterion_transducer is None: try: # from warprnnt_pytorch import RNNTLoss # self.criterion_transducer = RNNTLoss( # reduction="mean", # fastemit_lambda=self.fastemit_lambda, # ) from warp_rnnt import rnnt_loss as RNNTLoss self.criterion_transducer = RNNTLoss @@ -368,12 +363,6 @@ ) exit(1) # loss_transducer = self.criterion_transducer( # joint_out, # target, # t_len, # u_len, # ) log_probs = torch.log_softmax(joint_out, dim=-1) loss_transducer = self.criterion_transducer( @@ -637,7 +626,6 @@ batch_size = speech.shape[0] text = text[:, : text_lengths.max()] #print(speech.shape) # 1. Encoder encoder_out, encoder_out_chunk, encoder_out_lens = self.encode(speech, speech_lengths) @@ -854,11 +842,6 @@ """ if self.criterion_transducer is None: try: # from warprnnt_pytorch import RNNTLoss # self.criterion_transducer = RNNTLoss( # reduction="mean", # fastemit_lambda=self.fastemit_lambda, # ) from warp_rnnt import rnnt_loss as RNNTLoss self.criterion_transducer = RNNTLoss @@ -869,12 +852,6 @@ ) exit(1) # loss_transducer = self.criterion_transducer( # joint_out, # target, # t_len, # u_len, # ) log_probs = torch.log_softmax(joint_out, dim=-1) loss_transducer = self.criterion_transducer( funasr/models/predictor/cif.py
@@ -1,10 +1,12 @@ import torch from torch import nn from torch import Tensor import logging import numpy as np from funasr.torch_utils.device_funcs import to_device from funasr.modules.nets_utils import make_pad_mask from funasr.modules.streaming_utils.utils import sequence_mask from typing import Optional, Tuple class CifPredictor(nn.Module): def __init__(self, idim, l_order, r_order, threshold=1.0, dropout=0.1, smooth_factor=1.0, noise_threshold=0, tail_threshold=0.45): @@ -747,3 +749,128 @@ predictor_alignments = index_div_bool_zeros_count_tile_out predictor_alignments_length = predictor_alignments.sum(-1).type(encoder_sequence_length.dtype) return predictor_alignments.detach(), predictor_alignments_length.detach() class BATPredictor(nn.Module): def __init__(self, idim, l_order, r_order, threshold=1.0, dropout=0.1, smooth_factor=1.0, noise_threshold=0, return_accum=False): super(BATPredictor, self).__init__() self.pad = nn.ConstantPad1d((l_order, r_order), 0) self.cif_conv1d = nn.Conv1d(idim, idim, l_order + r_order + 1, groups=idim) self.cif_output = nn.Linear(idim, 1) self.dropout = torch.nn.Dropout(p=dropout) self.threshold = threshold self.smooth_factor = smooth_factor self.noise_threshold = noise_threshold self.return_accum = return_accum def cif( self, input: Tensor, alpha: Tensor, beta: float = 1.0, return_accum: bool = False, ) -> Tuple[Tensor, Tensor, Tensor, Tensor]: B, S, C = input.size() assert tuple(alpha.size()) == (B, S), f"{alpha.size()} != {(B, S)}" dtype = alpha.dtype alpha = alpha.float() alpha_sum = alpha.sum(1) feat_lengths = (alpha_sum / beta).floor().long() T = feat_lengths.max() # aggregate and integrate csum = alpha.cumsum(-1) with torch.no_grad(): # indices used for scattering right_idx = (csum / beta).floor().long().clip(max=T) left_idx = right_idx.roll(1, dims=1) left_idx[:, 0] = 0 # count # of fires from each source fire_num = right_idx - left_idx extra_weights = (fire_num - 1).clip(min=0) # The extra entry in last dim is for output = input.new_zeros((B, T + 1, C)) source_range = torch.arange(1, 1 + S).unsqueeze(0).type_as(input) zero = alpha.new_zeros((1,)) # right scatter fire_mask = fire_num > 0 right_weight = torch.where( fire_mask, csum - right_idx.type_as(alpha) * beta, zero ).type_as(input) # assert right_weight.ge(0).all(), f"{right_weight} should be non-negative." output.scatter_add_( 1, right_idx.unsqueeze(-1).expand(-1, -1, C), right_weight.unsqueeze(-1) * input ) # left scatter left_weight = ( alpha - right_weight - extra_weights.type_as(alpha) * beta ).type_as(input) output.scatter_add_( 1, left_idx.unsqueeze(-1).expand(-1, -1, C), left_weight.unsqueeze(-1) * input ) # extra scatters if extra_weights.ge(0).any(): extra_steps = extra_weights.max().item() tgt_idx = left_idx src_feats = input * beta for _ in range(extra_steps): tgt_idx = (tgt_idx + 1).clip(max=T) # (B, S, 1) src_mask = (extra_weights > 0) output.scatter_add_( 1, tgt_idx.unsqueeze(-1).expand(-1, -1, C), src_feats * src_mask.unsqueeze(2) ) extra_weights -= 1 output = output[:, :T, :] if return_accum: return output, csum else: return output, alpha def forward(self, hidden, target_label=None, mask=None, ignore_id=-1, mask_chunk_predictor=None, target_label_length=None): h = hidden context = h.transpose(1, 2) queries = self.pad(context) memory = self.cif_conv1d(queries) output = memory + context output = self.dropout(output) output = output.transpose(1, 2) output = torch.relu(output) output = self.cif_output(output) alphas = torch.sigmoid(output) alphas = torch.nn.functional.relu(alphas*self.smooth_factor - self.noise_threshold) if mask is not None: alphas = alphas * mask.transpose(-1, -2).float() if mask_chunk_predictor is not None: alphas = alphas * mask_chunk_predictor alphas = alphas.squeeze(-1) if target_label_length is not None: target_length = target_label_length elif target_label is not None: target_length = (target_label != ignore_id).float().sum(-1) # logging.info("target_length: {}".format(target_length)) else: target_length = None token_num = alphas.sum(-1) if target_length is not None: # length_noise = torch.rand(alphas.size(0), device=alphas.device) - 0.5 # target_length = length_noise + target_length alphas *= ((target_length + 1e-4) / token_num)[:, None].repeat(1, alphas.size(1)) acoustic_embeds, cif_peak = self.cif(hidden, alphas, self.threshold, self.return_accum) return acoustic_embeds, token_num, alphas, cif_peak funasr/modules/embedding.py
@@ -393,8 +393,9 @@ def encode(self, positions: torch.Tensor = None, depth: int = None, dtype: torch.dtype = torch.float32): batch_size = positions.size(0) positions = positions.type(dtype) log_timescale_increment = torch.log(torch.tensor([10000], dtype=dtype)) / (depth / 2 - 1) inv_timescales = torch.exp(torch.arange(depth / 2).type(dtype) * (-log_timescale_increment)) device = positions.device log_timescale_increment = torch.log(torch.tensor([10000], dtype=dtype, device=device)) / (depth / 2 - 1) inv_timescales = torch.exp(torch.arange(depth / 2, device=device).type(dtype) * (-log_timescale_increment)) inv_timescales = torch.reshape(inv_timescales, [batch_size, -1]) scaled_time = torch.reshape(positions, [1, -1, 1]) * torch.reshape(inv_timescales, [1, 1, -1]) encoding = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], dim=2) @@ -402,7 +403,7 @@ def forward(self, x): batch_size, timesteps, input_dim = x.size() positions = torch.arange(1, timesteps+1)[None, :] positions = torch.arange(1, timesteps+1, device=x.device)[None, :] position_encoding = self.encode(positions, input_dim, x.dtype).to(x.device) return x + position_encoding funasr/runtime/deploy_tools/funasr-runtime-deploy-offline-cpu-zh.sh
New file @@ -0,0 +1,1450 @@ #!/usr/bin/env bash scriptVersion="0.0.4" scriptDate="20230702" # Set color RED="\033[31;1m" GREEN="\033[32;1m" YELLOW="\033[33;1m" BLUE="\033[34;1m" CYAN="\033[36;1m" PLAIN="\033[0m" # Info messages DONE="${GREEN}[DONE]${PLAIN}" ERROR="${RED}[ERROR]${PLAIN}" WARNING="${YELLOW}[WARNING]${PLAIN}" # Font Format BOLD="\033[1m" UNDERLINE="\033[4m" # Current folder cur_dir=`pwd` DEFAULT_DOCKER_OFFLINE_CPU_ZH_LISTS="https://raw.githubusercontent.com/alibaba-damo-academy/FunASR/main/funasr/runtime/docs/docker_offline_cpu_zh_lists" DEFAULT_DOCKER_IMAGE_LISTS=$DEFAULT_DOCKER_OFFLINE_CPU_ZH_LISTS DEFAULT_FUNASR_DOCKER_URL="registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr" DEFAULT_FUNASR_RUNTIME_RESOURCES="funasr-runtime-resources" DEFAULT_FUNASR_LOCAL_WORKSPACE="${cur_dir}/${DEFAULT_FUNASR_RUNTIME_RESOURCES}" DEFAULT_FUNASR_CONFIG_DIR="/var/funasr" DEFAULT_FUNASR_CONFIG_FILE="${DEFAULT_FUNASR_CONFIG_DIR}/config" DEFAULT_FUNASR_PROGRESS_TXT="${DEFAULT_FUNASR_CONFIG_DIR}/progress.txt" DEFAULT_FUNASR_SERVER_LOG="${DEFAULT_FUNASR_CONFIG_DIR}/server_console.log" DEFAULT_FUNASR_WORKSPACE_DIR="/workspace/models" DEFAULT_DOCKER_PORT="10095" DEFAULT_PROGRESS_FILENAME="progress.txt" DEFAULT_SERVER_EXEC_NAME="funasr-wss-server" DEFAULT_DOCKER_EXEC_DIR="/workspace/FunASR/funasr/runtime/websocket/build/bin" DEFAULT_DOCKER_EXEC_PATH=${DEFAULT_DOCKER_EXEC_DIR}/${DEFAULT_SERVER_EXEC_NAME} DEFAULT_SAMPLES_NAME="funasr_samples" DEFAULT_SAMPLES_DIR="samples" DEFAULT_SAMPLES_URL="https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/${DEFAULT_SAMPLES_NAME}.tar.gz" SAMPLE_CLIENTS=( \ "Python" \ "Linux_Cpp" \ ) DOCKER_IMAGES=() # Handles the download progress bar asr_percent_int=0 vad_percent_int=0 punc_percent_int=0 asr_title="Downloading" asr_percent="0" asr_speed="0KB/s" asr_revision="" vad_title="Downloading" vad_percent="0" vad_speed="0KB/s" vad_revision="" punc_title="Downloading" punc_percent="0" punc_speed="0KB/s" punc_revision="" serverProgress(){ status_flag="STATUS:" stage=0 wait=0 server_status="" while true do if [ -f "$DEFAULT_FUNASR_PROGRESS_TXT" ]; then break else sleep 1 let wait=wait+1 if [ ${wait} -ge 6 ]; then break fi fi done if [ ! -f "$DEFAULT_FUNASR_PROGRESS_TXT" ]; then echo -e " ${RED}The note of progress does not exist.($DEFAULT_FUNASR_PROGRESS_TXT) ${PLAIN}" return 98 fi stage=1 while read line do if [ $stage -eq 1 ]; then result=$(echo $line | grep "STATUS:") if [ "$result" != "" ]; then stage=2 server_status=${line#*:} status=`expr $server_status + 0` if [ $status -eq 99 ]; then stage=99 fi continue fi elif [ $stage -eq 2 ]; then result=$(echo $line | grep "ASR") if [ "$result" != "" ]; then stage=3 continue fi elif [ $stage -eq 3 ]; then result=$(echo $line | grep "VAD") if [ "$result" != "" ]; then stage=4 continue fi result=$(echo $line | grep "title:") if [ "$result" != "" ]; then asr_title=${line#*:} continue fi result=$(echo $line | grep "percent:") if [ "$result" != "" ]; then asr_percent=${line#*:} continue fi result=$(echo $line | grep "speed:") if [ "$result" != "" ]; then asr_speed=${line#*:} continue fi result=$(echo $line | grep "revision:") if [ "$result" != "" ]; then asr_revision=${line#*:} continue fi elif [ $stage -eq 4 ]; then result=$(echo $line | grep "PUNC") if [ "$result" != "" ]; then stage=5 continue fi result=$(echo $line | grep "title:") if [ "$result" != "" ]; then vad_title=${line#*:} continue fi result=$(echo $line | grep "percent:") if [ "$result" != "" ]; then vad_percent=${line#*:} continue fi result=$(echo $line | grep "speed:") if [ "$result" != "" ]; then vad_speed=${line#*:} continue fi result=$(echo $line | grep "revision:") if [ "$result" != "" ]; then vad_revision=${line#*:} continue fi elif [ $stage -eq 5 ]; then result=$(echo $line | grep "DONE") if [ "$result" != "" ]; then # Done and break. stage=6 break fi result=$(echo $line | grep "title:") if [ "$result" != "" ]; then punc_title=${line#*:} continue fi result=$(echo $line | grep "percent:") if [ "$result" != "" ]; then punc_percent=${line#*:} continue fi result=$(echo $line | grep "speed:") if [ "$result" != "" ]; then punc_speed=${line#*:} continue fi result=$(echo $line | grep "revision:") if [ "$result" != "" ]; then punc_revision=${line#*:} continue fi elif [ $stage -eq 99 ]; then echo -e " ${RED}ERROR: $line${PLAIN}" fi done < $DEFAULT_FUNASR_PROGRESS_TXT if [ $stage -ne 99 ]; then drawProgress "ASR " $asr_title $asr_percent $asr_speed $asr_revision $asr_percent_int asr_percent_int=$? drawProgress "VAD " $vad_title $vad_percent $vad_speed $vad_revision $vad_percent_int vad_percent_int=$? drawProgress "PUNC" $punc_title $punc_percent $punc_speed $punc_revision $punc_percent_int punc_percent_int=$? fi return $stage } drawProgress(){ model=$1 title=$2 percent_str=$3 speed=$4 revision=$5 latest_percent=$6 progress=0 if [ ! -z "$percent_str" ]; then progress=`expr $percent_str + 0` latest_percent=`expr $latest_percent + 0` if [ $progress -ne 0 ] && [ $progress -lt $latest_percent ]; then progress=$latest_percent fi fi loading_flag="Loading" if [ "$title" = "$loading_flag" ]; then progress=100 fi i=0 str="" let max=progress/2 while [ $i -lt $max ] do let i++ str+='=' done let color=36 let index=max*2 if [ -z "$speed" ]; then printf "\r \e[0;${CYAN}[%s][%-11s][%-50s][%d%%][%s]\e[0m" "$model" "$title" "$str" "$$index" "$revision" else printf "\r \e[0;${CYAN}[%s][%-11s][%-50s][%3d%%][%8s][%s]\e[0m" "$model" "$title" "$str" "$index" "$speed" "$revision" fi printf "\n" return $progress } menuSelection(){ local menu menu=($(echo "$@")) result=1 show_no=1 menu_no=0 len=${#menu[@]} while true do echo -e " ${BOLD}${show_no})${PLAIN} ${menu[menu_no]}" let show_no++ let menu_no++ if [ $menu_no -ge $len ]; then break fi done while true do echo -e " Enter your choice, default(${CYAN}1${PLAIN}): \c" read result if [ -z "$result" ]; then result=1 fi expr $result + 0 &>/dev/null if [ $? -eq 0 ]; then if [ $result -ge 1 ] && [ $result -le $len ]; then break else echo -e " ${RED}Input error, please input correct number!${PLAIN}" fi else echo -e " ${RED}Input error, please input correct number!${PLAIN}" fi done return $result } full_path="" relativePathToFullPath(){ relativePath=$1 firstChar=${relativePath: 0: 1} if [[ "$firstChar" == "" ]]; then full_path=$relativePath elif [[ "$firstChar" == "/" ]]; then full_path=$relativePath fi tmpPath1=`dirname $relativePath` tmpFullpath1=`cd $tmpPath1 && pwd` tmpPath2=`basename $relativePath` full_path=${tmpFullpath1}/${tmpPath2} } initConfiguration(){ if [ ! -z "$DEFAULT_FUNASR_CONFIG_DIR" ]; then mkdir -p $DEFAULT_FUNASR_CONFIG_DIR fi if [ ! -f $DEFAULT_FUNASR_CONFIG_FILE ]; then touch $DEFAULT_FUNASR_CONFIG_FILE fi } initParameters(){ # Init workspace in local by new parameters. PARAMS_FUNASR_SAMPLES_LOCAL_PATH=${PARAMS_FUNASR_LOCAL_WORKSPACE}/${DEFAULT_SAMPLES_NAME}.tar.gz PARAMS_FUNASR_SAMPLES_LOCAL_DIR=${PARAMS_FUNASR_LOCAL_WORKSPACE}/${DEFAULT_SAMPLES_DIR} PARAMS_FUNASR_LOCAL_MODELS_DIR="${PARAMS_FUNASR_LOCAL_WORKSPACE}/models" if [ ! -z "$PARAMS_FUNASR_LOCAL_WORKSPACE" ]; then mkdir -p $PARAMS_FUNASR_LOCAL_WORKSPACE fi if [ ! -z "$PARAMS_FUNASR_LOCAL_MODELS_DIR" ]; then mkdir -p $PARAMS_FUNASR_LOCAL_MODELS_DIR fi } # Parse the parameters from the docker list file. docker_info_cur_key="" docker_info_cur_val="" findTypeOfDockerInfo(){ line=$1 result=$(echo $line | grep ":") if [ "$result" != "" ]; then docker_info_cur_key=$result docker_info_cur_val="" else docker_info_cur_val=$(echo $line) fi } # Get a list of docker images. readDockerInfoFromUrl(){ list_url=$DEFAULT_DOCKER_IMAGE_LISTS while true do content=$(curl --connect-timeout 10 -m 10 -s $list_url) if [ ! -z "$content" ]; then break else echo -e " ${RED}Unable to get docker image list due to network issues, try again.${PLAIN}" fi done array=($(echo "$content")) len=${#array[@]} stage=0 docker_flag="DOCKER:" judge_flag=":" for i in ${array[@]} do findTypeOfDockerInfo $i if [ "$docker_info_cur_key" = "DOCKER:" ]; then if [ ! -z "$docker_info_cur_val" ]; then docker_name=${DEFAULT_FUNASR_DOCKER_URL}:${docker_info_cur_val} DOCKER_IMAGES[${#DOCKER_IMAGES[*]}]=$docker_name fi elif [ "$docker_info_cur_key" = "DEFAULT_ASR_MODEL:" ]; then if [ ! -z "$docker_info_cur_val" ]; then PARAMS_ASR_ID=$docker_info_cur_val fi elif [ "$docker_info_cur_key" = "DEFAULT_VAD_MODEL:" ]; then if [ ! -z "$docker_info_cur_val" ]; then PARAMS_VAD_ID=$docker_info_cur_val fi elif [ "$docker_info_cur_key" = "DEFAULT_PUNC_MODEL:" ]; then if [ ! -z "$docker_info_cur_val" ]; then PARAMS_PUNC_ID=$docker_info_cur_val fi fi done echo -e " $DONE" } # Make sure root user. rootNess(){ echo -e "${UNDERLINE}${BOLD}[0/5]${PLAIN}" echo -e " ${YELLOW}Please check root access.${PLAIN}" echo -e " ${WARNING} MUST RUN AS ${RED}ROOT${PLAIN} USER!" if [[ $EUID -ne 0 ]]; then echo -e " ${ERROR} MUST RUN AS ${RED}ROOT${PLAIN} USER!" fi cd $cur_dir echo } # Get a list of docker images and select them. selectDockerImages(){ echo -e "${UNDERLINE}${BOLD}[1/5]${PLAIN}" echo -e " ${YELLOW}Getting the list of docker images, please wait a few seconds.${PLAIN}" readDockerInfoFromUrl echo echo -e " ${YELLOW}Please choose the Docker image.${PLAIN}" menuSelection ${DOCKER_IMAGES[*]} result=$? index=`expr $result - 1` PARAMS_DOCKER_IMAGE=${DOCKER_IMAGES[${index}]} echo -e " ${UNDERLINE}You have chosen the Docker image:${PLAIN} ${GREEN}${PARAMS_DOCKER_IMAGE}${PLAIN}" checkDockerExist result=$? result=`expr $result + 0` if [ ${result} -eq 50 ]; then return 50 fi echo } # Configure FunASR server host port setting. setupHostPort(){ echo -e "${UNDERLINE}${BOLD}[2/5]${PLAIN}" params_host_port=`sed '/^PARAMS_HOST_PORT=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ -z "$params_host_port" ]; then PARAMS_HOST_PORT="10095" else PARAMS_HOST_PORT=$params_host_port fi while true do echo -e " ${YELLOW}Please input the opened port in the host used for FunASR server.${PLAIN}" echo -e " Setting the opened host port [1-65535], default(${CYAN}${PARAMS_HOST_PORT}${PLAIN}): \c" read PARAMS_HOST_PORT if [ -z "$PARAMS_HOST_PORT" ]; then params_host_port=`sed '/^PARAMS_HOST_PORT=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ -z "$params_host_port" ]; then PARAMS_HOST_PORT="10095" else PARAMS_HOST_PORT=$params_host_port fi fi expr $PARAMS_HOST_PORT + 0 &>/dev/null if [ $? -eq 0 ]; then if [ $PARAMS_HOST_PORT -ge 1 ] && [ $PARAMS_HOST_PORT -le 65535 ]; then echo -e " ${UNDERLINE}The port of the host is${PLAIN} ${GREEN}${PARAMS_HOST_PORT}${PLAIN}" echo -e " ${UNDERLINE}The port in Docker for FunASR server is${PLAIN} ${GREEN}${PARAMS_DOCKER_PORT}${PLAIN}" break else echo -e " ${RED}Input error, please input correct number!${PLAIN}" fi else echo -e " ${RED}Input error, please input correct number!${PLAIN}" fi done echo } complementParameters(){ # parameters about ASR model if [ ! -z "$PARAMS_ASR_ID" ]; then PARAMS_DOCKER_ASR_PATH=${PARAMS_DOWNLOAD_MODEL_DIR}/${PARAMS_ASR_ID} PARAMS_DOCKER_ASR_DIR=$(dirname "$PARAMS_DOCKER_ASR_PATH") PARAMS_LOCAL_ASR_PATH=${PARAMS_FUNASR_LOCAL_MODELS_DIR}/${PARAMS_ASR_ID} PARAMS_LOCAL_ASR_DIR=$(dirname "$PARAMS_LOCAL_ASR_PATH") fi # parameters about VAD model if [ ! -z "$PARAMS_VAD_ID" ]; then PARAMS_DOCKER_VAD_PATH=${PARAMS_DOWNLOAD_MODEL_DIR}/${PARAMS_VAD_ID} PARAMS_DOCKER_VAD_DIR=$(dirname "$PARAMS_DOCKER_VAD_PATH") PARAMS_LOCAL_VAD_PATH=${PARAMS_FUNASR_LOCAL_MODELS_DIR}/${PARAMS_VAD_ID} PARAMS_LOCAL_VAD_DIR=$(dirname "$PARAMS_LOCAL_VAD_PATH") fi # parameters about PUNC model if [ ! -z "$PARAMS_PUNC_ID" ]; then PARAMS_DOCKER_PUNC_PATH=${PARAMS_DOWNLOAD_MODEL_DIR}/${PARAMS_PUNC_ID} PARAMS_DOCKER_PUNC_DIR=$(dirname "${PARAMS_DOCKER_PUNC_PATH}") PARAMS_LOCAL_PUNC_PATH=${PARAMS_FUNASR_LOCAL_MODELS_DIR}/${PARAMS_PUNC_ID} PARAMS_LOCAL_PUNC_DIR=$(dirname "${PARAMS_LOCAL_PUNC_PATH}") fi # parameters about thread_num params_decoder_thread_num=`sed '/^PARAMS_DECODER_THREAD_NUM=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ -z "$params_decoder_thread_num" ]; then PARAMS_DECODER_THREAD_NUM=$CPUNUM else PARAMS_DECODER_THREAD_NUM=$params_decoder_thread_num fi multiple_io=4 PARAMS_DECODER_THREAD_NUM=`expr ${PARAMS_DECODER_THREAD_NUM} + 0` PARAMS_IO_THREAD_NUM=`expr ${PARAMS_DECODER_THREAD_NUM} / ${multiple_io}` if [ $PARAMS_IO_THREAD_NUM -eq 0 ]; then PARAMS_IO_THREAD_NUM=1 fi } paramsFromDefault(){ initConfiguration echo -e " ${YELLOW}Load parameters from${PLAIN} ${GREEN}${DEFAULT_FUNASR_CONFIG_FILE}${PLAIN}" echo funasr_local_workspace=`sed '/^PARAMS_FUNASR_LOCAL_WORKSPACE=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$funasr_local_workspace" ]; then PARAMS_FUNASR_LOCAL_WORKSPACE=$funasr_local_workspace fi funasr_samples_local_dir=`sed '/^PARAMS_FUNASR_SAMPLES_LOCAL_DIR=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$funasr_samples_local_dir" ]; then PARAMS_FUNASR_SAMPLES_LOCAL_DIR=$funasr_samples_local_dir fi funasr_samples_local_path=`sed '/^PARAMS_FUNASR_SAMPLES_LOCAL_PATH=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$funasr_samples_local_path" ]; then PARAMS_FUNASR_SAMPLES_LOCAL_PATH=$funasr_samples_local_path fi funasr_local_models_dir=`sed '/^PARAMS_FUNASR_LOCAL_MODELS_DIR=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$funasr_local_models_dir" ]; then PARAMS_FUNASR_LOCAL_MODELS_DIR=$funasr_local_models_dir fi funasr_config_path=`sed '/^PARAMS_FUNASR_CONFIG_PATH=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$funasr_config_path" ]; then PARAMS_FUNASR_CONFIG_PATH=$funasr_config_path fi docker_image=`sed '/^PARAMS_DOCKER_IMAGE=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$docker_image" ]; then PARAMS_DOCKER_IMAGE=$docker_image fi download_model_dir=`sed '/^PARAMS_DOWNLOAD_MODEL_DIR=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$download_model_dir" ]; then PARAMS_DOWNLOAD_MODEL_DIR=$download_model_dir fi PARAMS_LOCAL_ASR_PATH=`sed '/^PARAMS_LOCAL_ASR_PATH=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$local_asr_path" ]; then PARAMS_LOCAL_ASR_PATH=$local_asr_path fi docker_asr_path=`sed '/^PARAMS_DOCKER_ASR_PATH=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$docker_asr_path" ]; then PARAMS_DOCKER_ASR_PATH=$docker_asr_path fi asr_id=`sed '/^PARAMS_ASR_ID=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$asr_id" ]; then PARAMS_ASR_ID=$asr_id fi local_vad_path=`sed '/^PARAMS_LOCAL_VAD_PATH=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$local_vad_path" ]; then PARAMS_LOCAL_VAD_PATH=$local_vad_path fi docker_vad_path=`sed '/^PARAMS_DOCKER_VAD_PATH=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$docker_vad_path" ]; then PARAMS_DOCKER_VAD_PATH=$docker_vad_path fi vad_id=`sed '/^PARAMS_VAD_ID=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$vad_id" ]; then PARAMS_VAD_ID=$vad_id fi local_punc_path=`sed '/^PARAMS_LOCAL_PUNC_PATH=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$local_punc_path" ]; then PARAMS_LOCAL_PUNC_PATH=$local_punc_path fi docker_punc_path=`sed '/^PARAMS_DOCKER_PUNC_PATH=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$docker_punc_path" ]; then PARAMS_DOCKER_PUNC_PATH=$docker_punc_path fi punc_id=`sed '/^PARAMS_PUNC_ID=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$punc_id" ]; then PARAMS_PUNC_ID=$punc_id fi docker_exec_path=`sed '/^PARAMS_DOCKER_EXEC_PATH=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$docker_exec_path" ]; then PARAMS_DOCKER_EXEC_PATH=$docker_exec_path fi host_port=`sed '/^PARAMS_HOST_PORT=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$host_port" ]; then PARAMS_HOST_PORT=$host_port fi docker_port=`sed '/^PARAMS_DOCKER_PORT=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$docker_port" ]; then PARAMS_DOCKER_PORT=$docker_port fi decode_thread_num=`sed '/^PARAMS_DECODER_THREAD_NUM=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$decode_thread_num" ]; then PARAMS_DECODER_THREAD_NUM=$decode_thread_num fi io_thread_num=`sed '/^PARAMS_IO_THREAD_NUM=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ ! -z "$io_thread_num" ]; then PARAMS_IO_THREAD_NUM=$io_thread_num fi } saveParams(){ echo "$i" > $DEFAULT_FUNASR_CONFIG_FILE echo -e " ${GREEN}Parameters are stored in the file ${DEFAULT_FUNASR_CONFIG_FILE}${PLAIN}" echo "PARAMS_DOCKER_IMAGE=${PARAMS_DOCKER_IMAGE}" > $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_FUNASR_LOCAL_WORKSPACE=${PARAMS_FUNASR_LOCAL_WORKSPACE}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_FUNASR_SAMPLES_LOCAL_DIR=${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_FUNASR_SAMPLES_LOCAL_PATH=${PARAMS_FUNASR_SAMPLES_LOCAL_PATH}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_FUNASR_LOCAL_MODELS_DIR=${PARAMS_FUNASR_LOCAL_MODELS_DIR}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_FUNASR_CONFIG_PATH=${PARAMS_FUNASR_CONFIG_PATH}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DOWNLOAD_MODEL_DIR=${PARAMS_DOWNLOAD_MODEL_DIR}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DOCKER_EXEC_PATH=${PARAMS_DOCKER_EXEC_PATH}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DOCKER_EXEC_DIR=${PARAMS_DOCKER_EXEC_DIR}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_LOCAL_ASR_PATH=${PARAMS_LOCAL_ASR_PATH}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_LOCAL_ASR_DIR=${PARAMS_LOCAL_ASR_DIR}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DOCKER_ASR_PATH=${PARAMS_DOCKER_ASR_PATH}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DOCKER_ASR_DIR=${PARAMS_DOCKER_ASR_DIR}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_ASR_ID=${PARAMS_ASR_ID}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_LOCAL_PUNC_PATH=${PARAMS_LOCAL_PUNC_PATH}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_LOCAL_PUNC_DIR=${PARAMS_LOCAL_PUNC_DIR}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DOCKER_PUNC_PATH=${PARAMS_DOCKER_PUNC_PATH}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DOCKER_PUNC_DIR=${PARAMS_DOCKER_PUNC_DIR}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_PUNC_ID=${PARAMS_PUNC_ID}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_LOCAL_VAD_PATH=${PARAMS_LOCAL_VAD_PATH}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_LOCAL_VAD_DIR=${PARAMS_LOCAL_VAD_DIR}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DOCKER_VAD_PATH=${PARAMS_DOCKER_VAD_PATH}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DOCKER_VAD_DIR=${PARAMS_DOCKER_VAD_DIR}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_VAD_ID=${PARAMS_VAD_ID}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_HOST_PORT=${PARAMS_HOST_PORT}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DOCKER_PORT=${PARAMS_DOCKER_PORT}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_DECODER_THREAD_NUM=${PARAMS_DECODER_THREAD_NUM}" >> $DEFAULT_FUNASR_CONFIG_FILE echo "PARAMS_IO_THREAD_NUM=${PARAMS_IO_THREAD_NUM}" >> $DEFAULT_FUNASR_CONFIG_FILE } showAllParams(){ echo -e "${UNDERLINE}${BOLD}[3/5]${PLAIN}" echo -e " ${YELLOW}Show parameters of FunASR server setting and confirm to run ...${PLAIN}" echo if [ ! -z "$PARAMS_DOCKER_IMAGE" ]; then echo -e " The current Docker image is : ${GREEN}${PARAMS_DOCKER_IMAGE}${PLAIN}" fi if [ ! -z "$PARAMS_FUNASR_LOCAL_WORKSPACE" ]; then echo -e " The local workspace path is : ${GREEN}${PARAMS_FUNASR_LOCAL_WORKSPACE}${PLAIN}" fi if [ ! -z "$PARAMS_DOWNLOAD_MODEL_DIR" ]; then echo -e " The model will be automatically downloaded in Docker : ${GREEN}${PARAMS_DOWNLOAD_MODEL_DIR}${PLAIN}" fi echo if [ ! -z "$PARAMS_ASR_ID" ]; then echo -e " The ASR model_id used : ${GREEN}${PARAMS_ASR_ID}${PLAIN}" fi if [ ! -z "$PARAMS_LOCAL_ASR_PATH" ]; then echo -e " The path to the local ASR model directory for the load : ${GREEN}${PARAMS_LOCAL_ASR_PATH}${PLAIN}" fi echo -e " The ASR model directory corresponds to the directory in Docker : ${GREEN}${PARAMS_DOCKER_ASR_PATH}${PLAIN}" if [ ! -z "$PARAMS_VAD_ID" ]; then echo -e " The VAD model_id used : ${GREEN}${PARAMS_VAD_ID}${PLAIN}" fi if [ ! -z "$PARAMS_LOCAL_VAD_PATH" ]; then echo -e " The path to the local VAD model directory for the load : ${GREEN}${PARAMS_LOCAL_VAD_PATH}${PLAIN}" fi echo -e " The VAD model directory corresponds to the directory in Docker : ${GREEN}${PARAMS_DOCKER_VAD_PATH}${PLAIN}" if [ ! -z "$PARAMS_PUNC_ID" ]; then echo -e " The PUNC model_id used : ${GREEN}${PARAMS_PUNC_ID}${PLAIN}" fi if [ ! -z "$PARAMS_LOCAL_PUNC_PATH" ]; then echo -e " The path to the local PUNC model directory for the load : ${GREEN}${PARAMS_LOCAL_PUNC_PATH}${PLAIN}" fi echo -e " The PUNC model directory corresponds to the directory in Docker: ${GREEN}${PARAMS_DOCKER_PUNC_PATH}${PLAIN}" echo echo -e " The path in the docker of the FunASR service executor : ${GREEN}${PARAMS_DOCKER_EXEC_PATH}${PLAIN}" echo -e " Set the host port used for use by the FunASR service : ${GREEN}${PARAMS_HOST_PORT}${PLAIN}" echo -e " Set the docker port used by the FunASR service : ${GREEN}${PARAMS_DOCKER_PORT}${PLAIN}" echo -e " Set the number of threads used for decoding the FunASR service : ${GREEN}${PARAMS_DECODER_THREAD_NUM}${PLAIN}" echo -e " Set the number of threads used for IO the FunASR service : ${GREEN}${PARAMS_IO_THREAD_NUM}${PLAIN}" echo if [ ! -z "$PARAMS_FUNASR_SAMPLES_LOCAL_DIR" ]; then echo -e " Sample code will be store in local : ${GREEN}${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}${PLAIN}" fi echo while true do params_confirm="y" echo -e " ${YELLOW}Please input [Y/n] to confirm the parameters.${PLAIN}" echo -e " [y] Verify that these parameters are correct and that the service will run." echo -e " [n] The parameters set are incorrect, it will be rolled out, please rerun." echo -e " read confirmation[${CYAN}Y${PLAIN}/n]: \c" read params_confirm if [ -z "$params_confirm" ]; then params_confirm="y" fi YES="Y" yes="y" NO="N" no="n" echo if [ "$params_confirm" = "$YES" ] || [ "$params_confirm" = "$yes" ]; then echo -e " ${GREEN}Will run FunASR server later ...${PLAIN}" break elif [ "$params_confirm" = "$NO" ] || [ "$params_confirm" = "$no" ]; then echo -e " ${RED}The parameters set are incorrect, please rerun ...${PLAIN}" exit 1 else echo "again ..." fi done saveParams echo sleep 1 } # Install docker installFunasrDocker(){ echo -e "${UNDERLINE}${BOLD}[4/5]${PLAIN}" if [ $DOCKERINFOLEN -gt 30 ]; then echo -e " ${YELLOW}Docker has installed.${PLAIN}" else lowercase_osid=$(echo ${OSID} | tr '[A-Z]' '[a-z]') echo -e " ${YELLOW}Start install docker for ${lowercase_osid} ${PLAIN}" DOCKER_INSTALL_CMD="curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun" DOCKER_INSTALL_RUN_CMD="" case "$lowercase_osid" in ubuntu) DOCKER_INSTALL_CMD="curl -fsSL https://test.docker.com -o test-docker.sh" DOCKER_INSTALL_RUN_CMD="sudo sh test-docker.sh" ;; centos) DOCKER_INSTALL_CMD="curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun" ;; debian) DOCKER_INSTALL_CMD="curl -fsSL https://get.docker.com -o get-docker.sh" DOCKER_INSTALL_RUN_CMD="sudo sh get-docker.sh" ;; \"alios\") DOCKER_INSTALL_CMD="curl -fsSL https://get.docker.com -o get-docker.sh" DOCKER_INSTALL_RUN_CMD="sudo sh get-docker.sh" ;; \"alinux\") DOCKER_INSTALL_CMD="sudo yum -y install dnf" DOCKER_INSTALL_RUN_CMD="sudo dnf -y install docker" ;; *) echo -e " ${RED}$lowercase_osid is not supported.${PLAIN}" ;; esac echo -e " Get docker installer: ${GREEN}${DOCKER_INSTALL_CMD}${PLAIN}" echo -e " Get docker run: ${GREEN}${DOCKER_INSTALL_RUN_CMD}${PLAIN}" $DOCKER_INSTALL_CMD if [ ! -z "$DOCKER_INSTALL_RUN_CMD" ]; then $DOCKER_INSTALL_RUN_CMD fi sudo systemctl start docker DOCKERINFO=$(sudo docker info | wc -l) DOCKERINFOLEN=`expr ${DOCKERINFO} + 0` if [ $DOCKERINFOLEN -gt 30 ]; then echo -e " ${GREEN}Docker install success, start docker server.${PLAIN}" sudo systemctl start docker else echo -e " ${RED}Docker install failed!${PLAIN}" exit 1 fi fi echo sleep 1 # Download docker image echo -e " ${YELLOW}Pull docker image(${PARAMS_DOCKER_IMAGE})...${PLAIN}" sudo docker pull $PARAMS_DOCKER_IMAGE echo sleep 1 } dockerRun(){ echo -e "${UNDERLINE}${BOLD}[5/5]${PLAIN}" echo -e " ${YELLOW}Construct command and run docker ...${PLAIN}" run_cmd="sudo docker run" port_map=" -p ${PARAMS_HOST_PORT}:${PARAMS_DOCKER_PORT}" dir_params=" --privileged=true" dir_map_params="" if [ ! -z "$PARAMS_LOCAL_ASR_DIR" ]; then if [ -z "$dir_map_params" ]; then dir_map_params="${dir_params} -v ${PARAMS_LOCAL_ASR_DIR}:${PARAMS_DOCKER_ASR_DIR}" else dir_map_params="${dir_map_params} -v ${PARAMS_LOCAL_ASR_DIR}:${PARAMS_DOCKER_ASR_DIR}" fi fi if [ ! -z "$PARAMS_LOCAL_VAD_DIR" ]; then if [ -z "$dir_map_params" ]; then dir_map_params="${dir_params} -v ${PARAMS_LOCAL_VAD_DIR}:${PARAMS_DOCKER_VAD_DIR}" else dir_map_params="${dir_map_params} -v ${PARAMS_LOCAL_VAD_DIR}:${PARAMS_DOCKER_VAD_DIR}" fi fi if [ ! -z "$PARAMS_LOCAL_PUNC_DIR" ]; then if [ -z "$dir_map_params" ]; then dir_map_params="${dir_params} -v ${PARAMS_LOCAL_PUNC_DIR}:${PARAMS_DOCKER_PUNC_DIR}" else dir_map_params="${dir_map_params} -v ${PARAMS_LOCAL_VAD_DIR}:${PARAMS_DOCKER_VAD_DIR}" fi fi exec_params="\"exec\":\"${PARAMS_DOCKER_EXEC_PATH}\"" if [ ! -z "$PARAMS_ASR_ID" ]; then asr_params="\"--model-dir\":\"${PARAMS_ASR_ID}\"" else asr_params="\"--model-dir\":\"${PARAMS_DOCKER_ASR_PATH}\"" fi if [ ! -z "$PARAMS_VAD_ID" ]; then vad_params="\"--vad-dir\":\"${PARAMS_VAD_ID}\"" else vad_params="\"--vad-dir\":\"${PARAMS_DOCKER_VAD_PATH}\"" fi if [ ! -z "$PARAMS_PUNC_ID" ]; then punc_params="\"--punc-dir\":\"${PARAMS_PUNC_ID}\"" else punc_params="\"--punc-dir\":\"${PARAMS_DOCKER_PUNC_PATH}\"" fi download_params="\"--download-model-dir\":\"${PARAMS_DOWNLOAD_MODEL_DIR}\"" if [ -z "$PARAMS_DOWNLOAD_MODEL_DIR" ]; then model_params="${asr_params},${vad_params},${punc_params}" else model_params="${asr_params},${vad_params},${punc_params},${download_params}" fi decoder_params="\"--decoder-thread-num\":\"${PARAMS_DECODER_THREAD_NUM}\"" io_params="\"--io-thread-num\":\"${PARAMS_IO_THREAD_NUM}\"" thread_params=${decoder_params},${io_params} port_params="\"--port\":\"${PARAMS_DOCKER_PORT}\"" crt_path="\"--certfile\":\"/workspace/FunASR/funasr/runtime/ssl_key/server.crt\"" key_path="\"--keyfile\":\"/workspace/FunASR/funasr/runtime/ssl_key/server.key\"" env_params=" -v ${DEFAULT_FUNASR_CONFIG_DIR}:/workspace/.config" env_params=" ${env_params} --env DAEMON_SERVER_CONFIG={\"server\":[{${exec_params},${model_params},${thread_params},${port_params},${crt_path},${key_path}}]}" run_cmd="${run_cmd}${port_map}${dir_map_params}${env_params}" run_cmd="${run_cmd} -it -d ${PARAMS_DOCKER_IMAGE}" # check Docker checkDockerExist result=$? result=`expr ${result} + 0` if [ ${result} -eq 50 ]; then return 50 fi rm -f ${DEFAULT_FUNASR_PROGRESS_TXT} rm -f ${DEFAULT_FUNASR_SERVER_LOG} $run_cmd echo echo -e " ${YELLOW}Loading models:${PLAIN}" # Hide the cursor, start draw progress. printf "\e[?25l" while true do serverProgress result=$? stage=`expr ${result} + 0` if [ ${stage} -eq 0 ]; then break elif [ ${stage} -gt 0 ] && [ ${stage} -lt 6 ]; then sleep 0.1 # clear 3 lines printf "\033[3A" elif [ ${stage} -eq 6 ]; then break elif [ ${stage} -eq 98 ]; then return 98 else echo -e " ${RED}Starting FunASR server failed.${PLAIN}" echo # Display the cursor printf "\e[?25h" return 99 fi done # Display the cursor printf "\e[?25h" echo -e " ${GREEN}The service has been started.${PLAIN}" echo deploySamples echo -e " ${BOLD}The sample code is already stored in the ${PLAIN}(${GREEN}${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}${PLAIN}) ." echo -e " ${BOLD}If you want to see an example of how to use the client, you can run ${PLAIN}${GREEN}sudo bash funasr-runtime-deploy-offline-cpu-zh.sh client${PLAIN} ." echo } installPythonDependencyForPython(){ echo -e "${YELLOW}Install Python dependent environments ...${PLAIN}" echo -e " Export dependency of Cpp sample." pre_cmd="export LD_LIBRARY_PATH=${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}/cpp/libs:\$LD_LIBRARY_PATH" $pre_cmd echo echo -e " Install requirements of Python sample." pre_cmd="pip3 install click>=8.0.4" $pre_cmd echo pre_cmd="pip3 install -r ${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}/python/requirements_client.txt" echo -e " Run ${BLUE}${pre_cmd}${PLAIN}" $pre_cmd echo lowercase_osid=$(echo ${OSID} | tr '[A-Z]' '[a-z]') case "$lowercase_osid" in ubuntu) pre_cmd="sudo apt-get install -y ffmpeg" ;; centos) pre_cmd="sudo yum install -y ffmpeg" ;; debian) pre_cmd="sudo apt-get install -y ffmpeg" ;; \"alios\") pre_cmd="sudo yum install -y ffmpeg" ;; \"alinux\") pre_cmd="sudo yum install -y ffmpeg" ;; *) echo -e " ${RED}$lowercase_osid is not supported.${PLAIN}" ;; esac echo -e " Run ${BLUE}${pre_cmd}${PLAIN}" echo pre_cmd="pip3 install ffmpeg-python" echo -e " Run ${BLUE}${pre_cmd}${PLAIN}" $pre_cmd echo } deploySamples(){ if [ ! -d $PARAMS_FUNASR_SAMPLES_LOCAL_DIR ]; then echo -e "${YELLOW}Downloading samples to${PLAIN} ${CYAN}${PARAMS_FUNASR_LOCAL_WORKSPACE}${PLAIN} ${YELLOW}...${PLAIN}" download_cmd="curl ${DEFAULT_SAMPLES_URL} -o ${PARAMS_FUNASR_SAMPLES_LOCAL_PATH}" untar_cmd="tar -zxf ${PARAMS_FUNASR_SAMPLES_LOCAL_PATH} -C ${PARAMS_FUNASR_LOCAL_WORKSPACE}" if [ ! -f "$PARAMS_FUNASR_SAMPLES_LOCAL_PATH" ]; then $download_cmd fi $untar_cmd echo installPythonDependencyForPython echo fi } checkDockerExist(){ result=$(sudo docker ps | grep ${PARAMS_DOCKER_IMAGE} | wc -l) result=`expr ${result} + 0` if [ ${result} -ne 0 ]; then echo echo -e " ${RED}Docker: ${PARAMS_DOCKER_IMAGE} has been launched, please run (${PLAIN}${GREEN}sudo bash funasr-runtime-deploy-offline-cpu-zh.sh stop${PLAIN}${RED}) to stop Docker first.${PLAIN}" return 50 fi } dockerExit(){ echo -e " ${YELLOW}Stop docker(${PLAIN}${GREEN}${PARAMS_DOCKER_IMAGE}${PLAIN}${YELLOW}) server ...${PLAIN}" sudo docker stop `sudo docker ps -a| grep ${PARAMS_DOCKER_IMAGE} | awk '{print $1}' ` echo sleep 1 } modelChange(){ model_type=$1 model_id=$2 local_flag=0 if [ -d "$model_id" ]; then local_flag=1 else local_flag=0 fi result=$(echo $model_type | grep "--asr_model") if [ "$result" != "" ]; then if [ $local_flag -eq 0 ]; then PARAMS_ASR_ID=$model_id PARAMS_DOCKER_ASR_PATH=${PARAMS_DOWNLOAD_MODEL_DIR}/${PARAMS_ASR_ID} PARAMS_DOCKER_ASR_DIR=$(dirname "${PARAMS_DOCKER_ASR_PATH}") PARAMS_LOCAL_ASR_PATH=${PARAMS_FUNASR_LOCAL_MODELS_DIR}/${PARAMS_ASR_ID} PARAMS_LOCAL_ASR_DIR=$(dirname "${PARAMS_LOCAL_ASR_PATH}") else PARAMS_ASR_ID="" PARAMS_LOCAL_ASR_PATH=$model_id if [ ! -d "$PARAMS_LOCAL_ASR_PATH" ]; then echo -e " ${RED}${PARAMS_LOCAL_ASR_PATH} does not exist, please set again.${PLAIN}" else model_name=$(basename "${PARAMS_LOCAL_ASR_PATH}") PARAMS_LOCAL_ASR_DIR=$(dirname "${PARAMS_LOCAL_ASR_PATH}") middle=${PARAMS_LOCAL_ASR_DIR#*"${PARAMS_FUNASR_LOCAL_MODELS_DIR}"} PARAMS_DOCKER_ASR_DIR=$PARAMS_DOWNLOAD_MODEL_DIR PARAMS_DOCKER_ASR_PATH=${PARAMS_DOCKER_ASR_DIR}/${middle}/${model_name} fi fi fi result=$(echo ${model_type} | grep "--vad_model") if [ "$result" != "" ]; then if [ $local_flag -eq 0 ]; then PARAMS_VAD_ID=$model_id PARAMS_DOCKER_VAD_PATH=${PARAMS_DOWNLOAD_MODEL_DIR}/${PARAMS_VAD_ID} PARAMS_DOCKER_VAD_DIR=$(dirname "${PARAMS_DOCKER_VAD_PATH}") PARAMS_LOCAL_VAD_PATH=${PARAMS_FUNASR_LOCAL_MODELS_DIR}/${PARAMS_VAD_ID} PARAMS_LOCAL_VAD_DIR=$(dirname "${PARAMS_LOCAL_VAD_PATH}") else PARAMS_VAD_ID="" PARAMS_LOCAL_VAD_PATH=$model_id if [ ! -d "$PARAMS_LOCAL_VAD_PATH" ]; then echo -e " ${RED}${PARAMS_LOCAL_VAD_PATH} does not exist, please set again.${PLAIN}" else model_name=$(basename "${PARAMS_LOCAL_VAD_PATH}") PARAMS_LOCAL_VAD_DIR=$(dirname "${PARAMS_LOCAL_VAD_PATH}") middle=${PARAMS_LOCAL_VAD_DIR#*"${PARAMS_FUNASR_LOCAL_MODELS_DIR}"} PARAMS_DOCKER_VAD_DIR=$PARAMS_DOWNLOAD_MODEL_DIR PARAMS_DOCKER_VAD_PATH=${PARAMS_DOCKER_VAD_DIR}/${middle}/${model_name} fi fi fi result=$(echo $model_type | grep "--punc_model") if [ "$result" != "" ]; then if [ $local_flag -eq 0 ]; then PARAMS_PUNC_ID=$model_id PARAMS_DOCKER_PUNC_PATH=${PARAMS_DOWNLOAD_MODEL_DIR}/${PARAMS_PUNC_ID} PARAMS_DOCKER_PUNC_DIR=$(dirname "${PARAMS_DOCKER_PUNC_PATH}") PARAMS_LOCAL_PUNC_PATH=${PARAMS_FUNASR_LOCAL_MODELS_DIR}/${PARAMS_PUNC_ID} PARAMS_LOCAL_PUNC_DIR=$(dirname "${PARAMS_LOCAL_PUNC_PATH}") else model_name=$(basename "${PARAMS_LOCAL_PUNC_PATH}") PARAMS_LOCAL_PUNC_DIR=$(dirname "${PARAMS_LOCAL_PUNC_PATH}") middle=${PARAMS_LOCAL_PUNC_DIR#*"${PARAMS_FUNASR_LOCAL_MODELS_DIR}"} PARAMS_DOCKER_PUNC_DIR=$PARAMS_DOWNLOAD_MODEL_DIR PARAMS_DOCKER_PUNC_PATH=${PARAMS_DOCKER_PUNC_DIR}/${middle}/${model_name} fi fi } threadNumChange() { type=$1 val=$2 if [ -z "$val"]; then num=`expr ${val} + 0` if [ $num -ge 1 ] && [ $num -le 1024 ]; then result=$(echo ${type} | grep "--decode_thread_num") if [ "$result" != "" ]; then PARAMS_DECODER_THREAD_NUM=$num fi result=$(echo ${type} | grep "--io_thread_num") if [ "$result" != "" ]; then PARAMS_IO_THREAD_NUM=$num fi fi fi } portChange() { type=$1 val=$2 if [ ! -z "$val" ]; then port=`expr ${val} + 0` if [ $port -ge 1 ] && [ $port -le 65536 ]; then result=$(echo ${type} | grep "host_port") if [ "$result" != "" ]; then PARAMS_HOST_PORT=$port fi result=$(echo ${type} | grep "docker_port") if [ "$result" != "" ]; then PARAMS_DOCKER_PORT=$port fi fi fi } sampleClientRun(){ echo -e "${YELLOW}Will download sample tools for the client to show how speech recognition works.${PLAIN}" download_cmd="curl ${DEFAULT_SAMPLES_URL} -o ${PARAMS_FUNASR_SAMPLES_LOCAL_PATH}" untar_cmd="tar -zxf ${PARAMS_FUNASR_SAMPLES_LOCAL_PATH} -C ${PARAMS_FUNASR_LOCAL_WORKSPACE}" if [ ! -f "$PARAMS_FUNASR_SAMPLES_LOCAL_PATH" ]; then $download_cmd fi if [ -f "$PARAMS_FUNASR_SAMPLES_LOCAL_PATH" ]; then $untar_cmd fi if [ -d "$PARAMS_FUNASR_SAMPLES_LOCAL_DIR" ]; then echo -e " Please select the client you want to run." menuSelection ${SAMPLE_CLIENTS[*]} result=$? index=`expr ${result} - 1` lang=${SAMPLE_CLIENTS[${index}]} echo server_ip="127.0.0.1" echo -e " Please enter the IP of server, default(${CYAN}${server_ip}${PLAIN}): \c" read server_ip if [ -z "$server_ip" ]; then server_ip="127.0.0.1" fi host_port=`sed '/^PARAMS_HOST_PORT=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ -z "$host_port" ]; then host_port="10095" fi echo -e " Please enter the port of server, default(${CYAN}${host_port}${PLAIN}): \c" read host_port if [ -z "$host_port" ]; then host_port=`sed '/^PARAMS_HOST_PORT=/!d;s/.*=//' ${DEFAULT_FUNASR_CONFIG_FILE}` if [ -z "$host_port" ]; then host_port="10095" fi fi wav_path="${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}/audio/asr_example.wav" echo -e " Please enter the audio path, default(${CYAN}${wav_path}${PLAIN}): \c" read WAV_PATH if [ -z "$wav_path" ]; then wav_path="${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}/audio/asr_example.wav" fi echo pre_cmd=”“ case "$lang" in Linux_Cpp) pre_cmd="export LD_LIBRARY_PATH=${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}/cpp/libs:\$LD_LIBRARY_PATH" client_exec="${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}/cpp/funasr-wss-client" run_cmd="${client_exec} --server-ip ${server_ip} --port ${host_port} --wav-path ${wav_path}" echo -e " Run ${BLUE}${pre_cmd}${PLAIN}" $pre_cmd echo ;; Python) client_exec="${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}/python/wss_client_asr.py" run_cmd="python3 ${client_exec} --host ${server_ip} --port ${host_port} --mode offline --audio_in ${wav_path} --send_without_sleep --output_dir ${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}/python" pre_cmd="pip3 install click>=8.0.4" echo -e " Run ${BLUE}${pre_cmd}${PLAIN}" $pre_cmd echo pre_cmd="pip3 install -r ${PARAMS_FUNASR_SAMPLES_LOCAL_DIR}/python/requirements_client.txt" echo -e " Run ${BLUE}${pre_cmd}${PLAIN}" $pre_cmd echo ;; *) echo "${lang} is not supported." ;; esac echo -e " Run ${BLUE}${run_cmd}${PLAIN}" $run_cmd echo echo -e " If failed, you can try (${GREEN}${run_cmd}${PLAIN}) in your Shell." echo fi } paramsConfigure(){ initConfiguration initParameters selectDockerImages result=$? result=`expr ${result} + 0` if [ ${result} -eq 50 ]; then return 50 fi setupHostPort complementParameters } # Display Help info displayHelp(){ echo -e "${UNDERLINE}Usage${PLAIN}:" echo -e " $0 [OPTIONAL FLAGS]" echo echo -e "funasr-runtime-deploy-offline-cpu-zh.sh - a Bash script to install&run FunASR docker." echo echo -e "${UNDERLINE}Options${PLAIN}:" echo -e " ${BOLD}-i, install, --install${PLAIN} Install and run FunASR docker." echo -e " install [--workspace] <workspace in local>" echo -e " ${BOLD}-s, start , --start${PLAIN} Run FunASR docker with configuration that has already been set." echo -e " ${BOLD}-p, stop , --stop${PLAIN} Stop FunASR docker." echo -e " ${BOLD}-r, restart, --restart${PLAIN} Restart FunASR docker." echo -e " ${BOLD}-u, update , --update${PLAIN} Update parameters that has already been set." echo -e " update [--workspace] <workspace in local>" echo -e " update [--asr_model | --vad_model | --punc_model] <model_id or local model path>" echo -e " update [--host_port | --docker_port] <port number>" echo -e " update [--decode_thread_num | io_thread_num] <the number of threads>" echo -e " ${BOLD}-c, client , --client${PLAIN} Get a client example to show how to initiate speech recognition." echo -e " ${BOLD}-o, show , --show${PLAIN} Displays all parameters that have been set." echo -e " ${BOLD}-v, version, --version${PLAIN} Display current script version." echo -e " ${BOLD}-h, help , --help${PLAIN} Display this help." echo echo -e " Version : ${scriptVersion} " echo -e " Modify Date: ${scriptDate}" } parseInput(){ local menu menu=($(echo "$@")) len=${#menu[@]} stage="" if [ $len -ge 2 ]; then for val in ${menu[@]} do result=$(echo $val | grep "\-\-") if [ "$result" != "" ]; then stage=$result else if [ "$stage" = "--workspace" ]; then relativePathToFullPath $val PARAMS_FUNASR_LOCAL_WORKSPACE=$full_path if [ ! -z "$PARAMS_FUNASR_LOCAL_WORKSPACE" ]; then mkdir -p $PARAMS_FUNASR_LOCAL_WORKSPACE fi fi fi done fi } # OS OSID=$(grep ^ID= /etc/os-release | cut -d= -f2) OSVER=$(lsb_release -cs) OSNUM=$(grep -oE "[0-9.]+" /etc/issue) CPUNUM=$(cat /proc/cpuinfo |grep "processor"|wc -l) DOCKERINFO=$(sudo docker info | wc -l) DOCKERINFOLEN=`expr ${DOCKERINFO} + 0` # PARAMS # The workspace for FunASR in local PARAMS_FUNASR_LOCAL_WORKSPACE=$DEFAULT_FUNASR_LOCAL_WORKSPACE # The dir stored sample code in local PARAMS_FUNASR_SAMPLES_LOCAL_DIR=${PARAMS_FUNASR_LOCAL_WORKSPACE}/${DEFAULT_SAMPLES_DIR} # The path of sample code in local PARAMS_FUNASR_SAMPLES_LOCAL_PATH=${PARAMS_FUNASR_LOCAL_WORKSPACE}/${DEFAULT_SAMPLES_NAME}.tar.gz # The dir stored models in local PARAMS_FUNASR_LOCAL_MODELS_DIR="${PARAMS_FUNASR_LOCAL_WORKSPACE}/models" # The path of configuration in local PARAMS_FUNASR_CONFIG_PATH="${PARAMS_FUNASR_LOCAL_WORKSPACE}/config" # The server excutor in local PARAMS_DOCKER_EXEC_PATH=$DEFAULT_DOCKER_EXEC_PATH # The dir stored server excutor in docker PARAMS_DOCKER_EXEC_DIR=$DEFAULT_DOCKER_EXEC_DIR # The dir for downloading model in docker PARAMS_DOWNLOAD_MODEL_DIR=$DEFAULT_FUNASR_WORKSPACE_DIR # The Docker image name PARAMS_DOCKER_IMAGE="" # The dir stored punc model in local PARAMS_LOCAL_PUNC_DIR="" # The path of punc model in local PARAMS_LOCAL_PUNC_PATH="" # The dir stored punc model in docker PARAMS_DOCKER_PUNC_DIR="" # The path of punc model in docker PARAMS_DOCKER_PUNC_PATH="" # The punc model ID in ModelScope PARAMS_PUNC_ID="damo/punc_ct-transformer_zh-cn-common-vocab272727-onnx" # The dir stored vad model in local PARAMS_LOCAL_VAD_DIR="" # The path of vad model in local PARAMS_LOCAL_VAD_PATH="" # The dir stored vad model in docker PARAMS_DOCKER_VAD_DIR="" # The path of vad model in docker PARAMS_DOCKER_VAD_PATH="" # The vad model ID in ModelScope PARAMS_VAD_ID="damo/speech_fsmn_vad_zh-cn-16k-common-onnx" # The dir stored asr model in local PARAMS_LOCAL_ASR_DIR="" # The path of asr model in local PARAMS_LOCAL_ASR_PATH="" # The dir stored asr model in docker PARAMS_DOCKER_ASR_DIR="" # The path of asr model in docker PARAMS_DOCKER_ASR_PATH="" # The asr model ID in ModelScope PARAMS_ASR_ID="damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx" PARAMS_HOST_PORT="10095" PARAMS_DOCKER_PORT="10095" PARAMS_DECODER_THREAD_NUM="32" PARAMS_IO_THREAD_NUM="8" echo -e "#############################################################" echo -e "# ${RED}OS${PLAIN}: ${OSID} ${OSNUM} ${OSVER}" echo -e "# ${RED}Kernel${PLAIN}: $(uname -m) Linux $(uname -r)" echo -e "# ${RED}CPU${PLAIN}: $(grep 'model name' /proc/cpuinfo | uniq | awk -F : '{print $2}' | sed 's/^[ \t]*//g' | sed 's/ \+/ /g') " echo -e "# ${RED}CPU NUM${PLAIN}: ${CPUNUM}" echo -e "# ${RED}RAM${PLAIN}: $(cat /proc/meminfo | grep 'MemTotal' | awk -F : '{print $2}' | sed 's/^[ \t]*//g') " echo -e "#" echo -e "# ${RED}Version${PLAIN}: ${scriptVersion} " echo -e "# ${RED}Modify Date${PLAIN}: ${scriptDate}" echo -e "#############################################################" echo # Initialization step case "$1" in install|-i|--install) rootNess paramsFromDefault parseInput $@ paramsConfigure result=$? result=`expr ${result} + 0` if [ ${result} -ne 50 ]; then showAllParams installFunasrDocker dockerRun result=$? stage=`expr ${result} + 0` if [ $stage -eq 98 ]; then dockerExit dockerRun fi fi ;; start|-s|--start) rootNess paramsFromDefault showAllParams dockerRun result=$? stage=`expr ${result} + 0` if [ $stage -eq 98 ]; then dockerExit dockerRun fi ;; restart|-r|--restart) rootNess paramsFromDefault showAllParams dockerExit dockerRun result=$? stage=`expr ${result} + 0` if [ $stage -eq 98 ]; then dockerExit dockerRun fi ;; stop|-p|--stop) rootNess paramsFromDefault dockerExit ;; update|-u|--update) rootNess paramsFromDefault if [ $# -eq 3 ]; then type=$2 val=$3 if [ "$type" = "--asr_model" ] || [ "$type" = "--vad_model" ] || [ "$type" = "--punc_model" ]; then modelChange $type $val elif [ "$type" = "--decode_thread_num" ] || [ "$type" = "--io_thread_num" ]; then threadNumChange $type $val elif [ "$type" = "--host_port" ] || [ "$type" = "--docker_port" ]; then portChange $type $val elif [ "$type" = "--workspace" ]; then relativePathToFullPath $val PARAMS_FUNASR_LOCAL_WORKSPACE=$full_path if [ ! -z "$PARAMS_FUNASR_LOCAL_WORKSPACE" ]; then mkdir -p $PARAMS_FUNASR_LOCAL_WORKSPACE fi else displayHelp fi else displayHelp fi initParameters complementParameters showAllParams dockerExit dockerRun result=$? stage=`expr ${result} + 0` if [ $stage -eq 98 ]; then dockerExit dockerRun fi ;; client|-c|--client) rootNess paramsFromDefault parseInput $@ sampleClientRun ;; show|-o|--show) rootNess paramsFromDefault showAllParams ;; *) displayHelp exit 0 ;; esac funasr/runtime/docs/SDK_advanced_guide_offline.md
New file @@ -0,0 +1,259 @@ # Advanced Development Guide (File transcription service) FunASR provides a Chinese offline file transcription service that can be deployed locally or on a cloud server with just one click. The core of the service is the FunASR runtime SDK, which has been open-sourced. FunASR-runtime combines various capabilities such as speech endpoint detection (VAD), large-scale speech recognition (ASR) using Paraformer-large, and punctuation detection (PUNC), which have all been open-sourced by the speech laboratory of DAMO Academy on the Modelscope community. This enables accurate and efficient high-concurrency transcription of audio files. This document serves as a development guide for the FunASR offline file transcription service. If you wish to quickly experience the offline file transcription service, please refer to the one-click deployment example for the FunASR offline file transcription service ([docs](./SDK_tutorial.md)). ## Installation of Docker The following steps are for manually installing Docker and Docker images. If your Docker image has already been launched, you can ignore this step. ### Installation of Docker environment ```shell # Ubuntu: curl -fsSL https://test.docker.com -o test-docker.sh sudo sh test-docker.sh # Debian: curl -fsSL https://get.docker.com -o get-docker.sh sudo sh get-docker.sh # CentOS: curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun # MacOS: brew install --cask --appdir=/Applications docker ``` More details could ref to [docs](https://alibaba-damo-academy.github.io/FunASR/en/installation/docker.html) ### Starting Docker ```shell sudo systemctl start docker ``` ### Pulling and launching images Use the following command to pull and launch the Docker image for the FunASR runtime-SDK: ```shell sudo docker pull registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-latest sudo docker run -p 10095:10095 -it --privileged=true -v /root:/workspace/models registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-latest ``` Introduction to command parameters: ```text -p <host port>:<mapped docker port>: In the example, host machine (ECS) port 10095 is mapped to port 10095 in the Docker container. Make sure that port 10095 is open in the ECS security rules. -v <host path>:<mounted Docker path>: In the example, the host machine path /root is mounted to the Docker path /workspace/models. ``` ## Starting the server Use the flollowing script to start the server : ```shell ./run_server.sh --vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \ --model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx \ --punc-dir damo/punc_ct-transformer_zh-cn-common-vocab272727-onnx ``` More details about the script run_server.sh: The FunASR-wss-server supports downloading models from Modelscope. You can set the model download address (--download-model-dir, default is /workspace/models) and the model ID (--model-dir, --vad-dir, --punc-dir). Here is an example: ```shell cd /workspace/FunASR/funasr/runtime/websocket/build/bin ./funasr-wss-server \ --download-model-dir /workspace/models \ --model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx \ --vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \ --punc-dir damo/punc_ct-transformer_zh-cn-common-vocab272727-onnx \ --decoder-thread-num 32 \ --io-thread-num 8 \ --port 10095 \ --certfile ../../../ssl_key/server.crt \ --keyfile ../../../ssl_key/server.key ``` Introduction to command parameters: ```text --download-model-dir: Model download address, download models from Modelscope by setting the model ID. --model-dir: Modelscope model ID. --quantize: True for quantized ASR model, False for non-quantized ASR model. Default is True. --vad-dir: Modelscope model ID. --vad-quant: True for quantized VAD model, False for non-quantized VAD model. Default is True. --punc-dir: Modelscope model ID. --punc-quant: True for quantized PUNC model, False for non-quantized PUNC model. Default is True. --port: Port number that the server listens on. Default is 10095. --decoder-thread-num: Number of inference threads that the server starts. Default is 8. --io-thread-num: Number of IO threads that the server starts. Default is 1. --certfile <string>: SSL certificate file. Default is ../../../ssl_key/server.crt. --keyfile <string>: SSL key file. Default is ../../../ssl_key/server.key. ``` The FunASR-wss-server also supports loading models from a local path (see Preparing Model Resources for detailed instructions on preparing local model resources). Here is an example: ```shell cd /workspace/FunASR/funasr/runtime/websocket/build/bin ./funasr-wss-server \ --model-dir /workspace/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx \ --vad-dir /workspace/models/damo/speech_fsmn_vad_zh-cn-16k-common-onnx \ --punc-dir /workspace/models/damo/punc_ct-transformer_zh-cn-common-vocab272727-onnx \ --decoder-thread-num 32 \ --io-thread-num 8 \ --port 10095 \ --certfile ../../../ssl_key/server.crt \ --keyfile ../../../ssl_key/server.key ``` ## Preparing Model Resources If you choose to download models from Modelscope through the FunASR-wss-server, you can skip this step. The vad, asr, and punc model resources in the offline file transcription service of FunASR are all from Modelscope. The model addresses are shown in the table below: | Model | Modelscope url | |-------|------------------------------------------------------------------------------------------------------------------| | VAD | https://www.modelscope.cn/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary | | ASR | https://www.modelscope.cn/models/damo/speech_fsmn_vad_zh-cn-16k-common-pytorch/summary | | PUNC | https://www.modelscope.cn/models/damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/summary | The offline file transcription service deploys quantized ONNX models. Below are instructions on how to export ONNX models and their quantization. You can choose to export ONNX models from Modelscope, local files, or finetuned resources: ### Exporting ONNX models from Modelscope Download the corresponding model with the given model name from the Modelscope website, and then export the quantized ONNX model ```shell python -m funasr.export.export_model \ --export-dir ./export \ --type onnx \ --quantize True \ --model-name damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch \ --model-name damo/speech_fsmn_vad_zh-cn-16k-common-pytorch \ --model-name damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch ``` Introduction to command parameters: ```text --model-name: The name of the model on Modelscope, for example: damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch --export-dir: The export directory of ONNX model. --type: Model type, currently supports ONNX and torch. --quantize: Quantize the int8 model. ``` ### Exporting ONNX models from local files Set the model name to the local path of the model, and export the quantized ONNX model: ```shell python -m funasr.export.export_model --model-name /workspace/models/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch --export-dir ./export --type onnx --quantize True ``` ### Exporting models from finetuned resources If you want to deploy a finetuned model, you can follow these steps: Rename the model you want to deploy after finetuning (for example, 10epoch.pb) to model.pb, and replace the original model.pb in Modelscope with this one. If the path of the replaced model is /path/to/finetune/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch, use the following command to convert the finetuned model to an ONNX model: ```shell python -m funasr.export.export_model --model-name /path/to/finetune/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch --export-dir ./export --type onnx --quantize True ``` ## Starting the client After completing the deployment of FunASR offline file transcription service on the server, you can test and use the service by following these steps. Currently, FunASR-bin supports multiple ways to start the client. The following are command-line examples based on python-client, c++-client, and custom client Websocket communication protocol: ### python-client ```shell python wss_client_asr.py --host "127.0.0.1" --port 10095 --mode offline --audio_in "./data/wav.scp" --send_without_sleep --output_dir "./results" ``` Introduction to command parameters: ```text --host: the IP address of the server. It can be set to 127.0.0.1 for local testing. --port: the port number of the server listener. --audio_in: the audio input. Input can be a path to a wav file or a wav.scp file (a Kaldi-formatted wav list in which each line includes a wav_id followed by a tab and a wav_path). --output_dir: the path to the recognition result output. --ssl: whether to use SSL encryption. The default is to use SSL. --mode: offline mode. ``` ### c++-client ```shell . /funasr-wss-client --server-ip 127.0.0.1 --port 10095 --wav-path test.wav --thread-num 1 --is-ssl 1 ``` Introduction to command parameters: ```text --host: the IP address of the server. It can be set to 127.0.0.1 for local testing. --port: the port number of the server listener. --audio_in: the audio input. Input can be a path to a wav file or a wav.scp file (a Kaldi-formatted wav list in which each line includes a wav_id followed by a tab and a wav_path). --output_dir: the path to the recognition result output. --ssl: whether to use SSL encryption. The default is to use SSL. --mode: offline mode. ``` ### Custom client If you want to define your own client, the Websocket communication protocol is as follows: ```text # First communication {"mode": "offline", "wav_name": wav_name, "is_speaking": True} # Send wav data Bytes data # Send end flag {"is_speaking": False} ``` ## How to customize service deployment The code for FunASR-runtime is open source. If the server and client cannot fully meet your needs, you can further develop them based on your own requirements: ### C++ client https://github.com/alibaba-damo-academy/FunASR/tree/main/funasr/runtime/websocket ### Python client https://github.com/alibaba-damo-academy/FunASR/tree/main/funasr/runtime/python/websocket ### C++ server #### VAD ```c++ // The use of the VAD model consists of two steps: FsmnVadInit and FsmnVadInfer: FUNASR_HANDLE vad_hanlde=FsmnVadInit(model_path, thread_num); // Where: model_path contains "model-dir" and "quantize", thread_num is the ONNX thread count; FUNASR_RESULT result=FsmnVadInfer(vad_hanlde, wav_file.c_str(), NULL, 16000); // Where: vad_hanlde is the return value of FunOfflineInit, wav_file is the path to the audio file, and sampling_rate is the sampling rate (default 16k). ``` See the usage example for details [docs](https://github.com/alibaba-damo-academy/FunASR/blob/main/funasr/runtime/onnxruntime/bin/funasr-onnx-offline-vad.cpp) #### ASR ```text // The use of the ASR model consists of two steps: FunOfflineInit and FunOfflineInfer: FUNASR_HANDLE asr_hanlde=FunOfflineInit(model_path, thread_num); // Where: model_path contains "model-dir" and "quantize", thread_num is the ONNX thread count; FUNASR_RESULT result=FunOfflineInfer(asr_hanlde, wav_file.c_str(), RASR_NONE, NULL, 16000); // Where: asr_hanlde is the return value of FunOfflineInit, wav_file is the path to the audio file, and sampling_rate is the sampling rate (default 16k). ``` See the usage example for details, [docs](https://github.com/alibaba-damo-academy/FunASR/blob/main/funasr/runtime/onnxruntime/bin/funasr-onnx-offline.cpp) #### PUNC ```text // The use of the PUNC model consists of two steps: CTTransformerInit and CTTransformerInfer: FUNASR_HANDLE punc_hanlde=CTTransformerInit(model_path, thread_num); // Where: model_path contains "model-dir" and "quantize", thread_num is the ONNX thread count; FUNASR_RESULT result=CTTransformerInfer(punc_hanlde, txt_str.c_str(), RASR_NONE, NULL); // Where: punc_hanlde is the return value of CTTransformerInit, txt_str is the text ``` See the usage example for details, [docs](https://github.com/alibaba-damo-academy/FunASR/blob/main/funasr/runtime/onnxruntime/bin/funasr-onnx-offline-punc.cpp) funasr/runtime/docs/SDK_advanced_guide_offline_zh.md
File was renamed from funasr/runtime/docs/SDK_advanced_guide_cn.md @@ -35,9 +35,9 @@ 通过下述命令拉取并启动FunASR runtime-SDK的docker镜像: ```shell sudo docker pull registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.0.1 sudo docker pull registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-latest sudo docker run -p 10095:10095 -it --privileged=true -v /root:/workspace/models registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.0.1 sudo docker run -p 10095:10095 -it --privileged=true -v /root:/workspace/models registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-latest ``` 命令参数介绍: @@ -52,6 +52,13 @@ ## 服务端启动 docker启动之后,启动 funasr-wss-server服务程序: ```shell ./run_server.sh --vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \ --model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx \ --punc-dir damo/punc_ct-transformer_zh-cn-common-vocab272727-onnx ``` 详细命令参数介绍: funasr-wss-server支持从Modelscope下载模型,设置模型下载地址(--download-model-dir,默认为/workspace/models)及model ID(--model-dir、--vad-dir、--punc-dir),示例如下: ```shell funasr/runtime/docs/SDK_tutorial.md
@@ -8,10 +8,14 @@ ### Downloading Tools and Deployment Run the following command to perform a one-click deployment of the FunASR runtime-SDK service. Follow the prompts to complete the deployment and running of the service. Currently, only Linux environments are supported, and for other environments, please refer to the Advanced SDK Development Guide. Due to network restrictions, the download of the funasr-runtime-deploy.sh one-click deployment tool may not proceed smoothly. If the tool has not been downloaded and entered into the one-click deployment tool after several seconds, please terminate it with Ctrl + C and run the following command again. Run the following command to perform a one-click deployment of the FunASR runtime-SDK service. Follow the prompts to complete the deployment and running of the service. Currently, only Linux environments are supported, and for other environments, please refer to the Advanced SDK Development Guide ([docs](./SDK_advanced_guide_offline.md)). [//]: # (Due to network restrictions, the download of the funasr-runtime-deploy.sh one-click deployment tool may not proceed smoothly. If the tool has not been downloaded and entered into the one-click deployment tool after several seconds, please terminate it with Ctrl + C and run the following command again.) ```shell curl -O https://raw.githubusercontent.com/alibaba-damo-academy/FunASR-APP/main/TransAudio/funasr-runtime-deploy.sh; sudo bash funasr-runtime-deploy.sh install # For the users in China, you could install with the command: # curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/funasr-runtime-deploy.sh; sudo bash funasr-runtime-deploy.sh install ``` #### Details of Configuration funasr/runtime/docs/SDK_tutorial_cn.md
File was deleted funasr/runtime/docs/SDK_tutorial_zh.md
New file @@ -0,0 +1,188 @@ # FunASR离线文件转写服务便捷部署教程 FunASR提供可便捷本地或者云端服务器部署的离线文件转写服务,内核为FunASR已开源runtime-SDK。 集成了达摩院语音实验室在Modelscope社区开源的语音端点检测(VAD)、Paraformer-large语音识别(ASR)、标点恢复(PUNC) 等相关能力,拥有完整的语音识别链路,可以将几十个小时的音频或视频识别成带标点的文字,而且支持上百路请求同时进行转写。 ## 服务器配置 用户可以根据自己的业务需求,选择合适的服务器配置,推荐配置为: - 配置1: (X86,计算型),4核vCPU,内存8G,单机可以支持大约32路的请求 - 配置2: (X86,计算型),16核vCPU,内存32G,单机可以支持大约64路的请求 - 配置3: (X86,计算型),64核vCPU,内存128G,单机可以支持大约200路的请求 云服务厂商,针对新用户,有3个月免费试用活动,申请教程([点击此处](./aliyun_server_tutorial.md)) ## 快速上手 ### 服务端启动 下载部署工具`funasr-runtime-deploy-offline-cpu-zh.sh` ```shell curl -O https://raw.githubusercontent.com/alibaba-damo-academy/FunASR/main/funasr/runtime/deploy_tools/funasr-runtime-deploy-offline-cpu-zh.sh; # 如遇到网络问题,中国大陆用户,可以用个下面的命令: # curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/funasr-runtime-deploy-offline-cpu-zh.sh; ``` 执行部署工具,在提示处输入回车键即可完成服务端安装与部署。目前便捷部署工具暂时仅支持Linux环境,其他环境部署参考开发指南([点击此处](./SDK_advanced_guide_zh.md)) ```shell sudo bash funasr-runtime-deploy-offline-cpu-zh.sh install --workspace /root/funasr-runtime-resources ``` ### 客户端测试与使用 运行上面安装指令后,会在/root/funasr-runtime-resources(默认安装目录)中下载客户端测试工具目录samples, 我们以Python语言客户端为例,进行说明,支持多种音频格式输入(.wav, .pcm, .mp3等),也支持视频输入(.mp4等),以及多文件列表wav.scp输入,其他版本客户端请参考文档([点击此处](#客户端用法详解)) ```shell python3 wss_client_asr.py --host "127.0.0.1" --port 10095 --mode offline --audio_in "../audio/asr_example.wav" --output_dir "./results" ``` ## 客户端用法详解 在服务器上完成FunASR服务部署以后,可以通过如下的步骤来测试和使用离线文件转写服务。 目前分别支持以下几种编程语言客户端 - [Python](#python-client) - [CPP](#cpp-client) - [html网页版本](#Html网页版) - [Java](#Java-client) 更多版本客户端支持请参考[开发指南](./SDK_advanced_guide_offline_zh.md) ### python-client 若想直接运行client进行测试,可参考如下简易说明,以python版本为例: ```shell python3 wss_client_asr.py --host "127.0.0.1" --port 10095 --mode offline --audio_in "../audio/asr_example.wav" --output_dir "./results" ``` 命令参数说明: ```text --host 为FunASR runtime-SDK服务部署机器ip,默认为本机ip(127.0.0.1),如果client与服务不在同一台服务器,需要改为部署机器ip --port 10095 部署端口号 --mode offline表示离线文件转写 --audio_in 需要进行转写的音频文件,支持文件路径,文件列表wav.scp --output_dir 识别结果保存路径 ``` ### cpp-client 进入samples/cpp目录后,可以用cpp进行测试,指令如下: ```shell ./funasr-wss-client --server-ip 127.0.0.1 --port 10095 --wav-path ../audio/asr_example.wav ``` 命令参数说明: ```text --server-ip 为FunASR runtime-SDK服务部署机器ip,默认为本机ip(127.0.0.1),如果client与服务不在同一台服务器,需要改为部署机器ip --port 10095 部署端口号 --wav-path 需要进行转写的音频文件,支持文件路径 ``` ### Html网页版 在浏览器中打开 html/static/index.html,即可出现如下页面,支持麦克风输入与文件上传,直接进行体验 <img src="images/html.png" width="900"/> ### Java-client ```shell FunasrWsClient --host localhost --port 10095 --audio_in ./asr_example.wav --mode offline ``` 详细可以参考文档([点击此处](../java/readme.md)) ## 服务端用法详解 ### 启动已经部署过的FunASR服务 一键部署后若出现重启电脑等关闭Docker的动作,可通过如下命令直接启动FunASR服务,启动配置为上次一键部署的设置。 ```shell sudo bash funasr-runtime-deploy-offline-cpu-zh.sh start ``` ### 关闭FunASR服务 ```shell sudo bash funasr-runtime-deploy-offline-cpu-zh.sh stop ``` ### 重启FunASR服务 根据上次一键部署的设置重启启动FunASR服务。 ```shell sudo bash funasr-runtime-deploy-offline-cpu-zh.sh restart ``` ### 替换模型并重启FunASR服务 替换正在使用的模型,并重新启动FunASR服务。模型需为ModelScope中的ASR/VAD/PUNC模型,或者从ModelScope中模型finetune后的模型。 ```shell sudo bash funasr-runtime-deploy-offline-cpu-zh.sh update [--asr_model | --vad_model | --punc_model] <model_id or local model path> e.g sudo bash funasr-runtime-deploy-offline-cpu-zh.sh update --asr_model damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch ``` ### 更新参数并重启FunASR服务 更新已配置参数,并重新启动FunASR服务生效。可更新参数包括宿主机和Docker的端口号,以及推理和IO的线程数量。 ```shell sudo bash funasr-runtime-deploy-offline-cpu-zh.sh update [--host_port | --docker_port] <port number> sudo bash funasr-runtime-deploy-offline-cpu-zh.sh update [--decode_thread_num | --io_thread_num] <the number of threads> sudo bash funasr-runtime-deploy-offline-cpu-zh.sh update [--workspace] <workspace in local> e.g sudo bash funasr-runtime-deploy-offline-cpu-zh.sh update --decode_thread_num 32 sudo bash funasr-runtime-deploy-offline-cpu-zh.sh update --workspace /root/funasr-runtime-resources ``` ## 服务端启动过程配置详解 ##### 选择FunASR Docker镜像 推荐选择1)使用我们的最新发布版镜像,也可选择历史版本。 ```text [1/5] Getting the list of docker images, please wait a few seconds. [DONE] Please choose the Docker image. 1) registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.1.0 Enter your choice, default(1): You have chosen the Docker image: registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.1.0 ``` ##### 设置宿主机提供给FunASR的端口 设置提供给Docker的宿主机端口,默认为10095。请保证此端口可用。 ```text [2/5] Please input the opened port in the host used for FunASR server. Setting the opened host port [1-65535], default(10095): The port of the host is 10095 The port in Docker for FunASR server is 10095 ``` ## 视频demo [点击此处]()
@@ -2,16 +2,6 @@ 我们以阿里云([点此链接](https://www.aliyun.com/))为例,演示如何申请云服务器 ## 服务器配置 用户可以根据自己的业务需求,选择合适的服务器配置,推荐配置为: - 配置一(高配):X86架构,32/64核8369CPU,内存8G以上; - 配置二:X86架构,32/64核8163CPU,内存8G以上; 详细性能测试报告:[点此链接](./benchmark_onnx_cpp.md) 我们以免费试用(1~3个月)为例,演示如何申请服务器流程,图文步骤如下: ### 登陆个人账号 打开阿里云官网[点此链接](https://www.aliyun.com/),注册并登陆个人账号,如下图标号1所示 @@ -69,6 +59,6 @@ <img src="images/aliyun12.png" width="900"/> 上图表示已经成功申请了云服务器,后续可以根据FunASR runtime-SDK部署文档进行一键部署([点击此处]()) 上图表示已经成功申请了云服务器,后续可以根据FunASR runtime-SDK部署文档进行一键部署([点击此处](./SDK_tutorial_cn.md))
New file @@ -0,0 +1,8 @@ DOCKER: funasr-runtime-sdk-cpu-0.1.0 DEFAULT_ASR_MODEL: damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx DEFAULT_VAD_MODEL: damo/speech_fsmn_vad_zh-cn-16k-common-onnx DEFAULT_PUNC_MODEL: damo/punc_ct-transformer_zh-cn-common-vocab272727-onnx funasr/runtime/docs/images/html.png
@@ -74,7 +74,7 @@ Loadding from wav.scp(kaldi style) ```shell # --chunk_interval, "10": 600/10=60ms, "5"=600/5=120ms, "20": 600/12=30ms python wss_client_asr.py --host "0.0.0.0" --port 10095 --mode offline --chunk_interval 10 --words_max_print 100 --audio_in "./data/wav.scp" --send_without_sleep --output_dir "./results" python wss_client_asr.py --host "0.0.0.0" --port 10095 --mode offline --chunk_interval 10 --words_max_print 100 --audio_in "./data/wav.scp" --output_dir "./results" ``` ##### ASR streaming client funasr/runtime/python/websocket/wss_client_asr.py
@@ -40,7 +40,7 @@ help="audio_in") parser.add_argument("--send_without_sleep", action="store_true", default=False, default=True, help="if audio_in is set, send_without_sleep") parser.add_argument("--test_thread_num", type=int, @@ -161,7 +161,8 @@ #voices.put(message) await websocket.send(message) sleep_duration = 0.001 if args.send_without_sleep else 60 * args.chunk_size[1] / args.chunk_interval / 1000 sleep_duration = 0.001 if args.mode == "offline" else 60 * args.chunk_size[1] / args.chunk_interval / 1000 await asyncio.sleep(sleep_duration) # when all data sent, we need to close websocket while not voices.empty(): funasr/runtime/readme.md
@@ -27,4 +27,4 @@ ### Advanced Development Guide The documentation mainly targets advanced developers who require modifications and customization of the service. It supports downloading model deployments from modelscope and also supports deploying models that users have fine-tuned. For detailed information, please refer to the documentation available by [docs](websocket/readme.md) The documentation mainly targets advanced developers who require modifications and customization of the service. It supports downloading model deployments from modelscope and also supports deploying models that users have fine-tuned. For detailed information, please refer to the documentation available by [docs](./docs/SDK_advanced_guide_offline.md) funasr/runtime/readme_cn.md
@@ -9,23 +9,23 @@ - 中文离线文件转写服务(GPU版本),进行中 - 英文离线转写服务,进行中 - 流式语音识别服务,进行中 - 。。。 - 更多支持中 ## 中文离线文件转写服务部署(CPU版本) 目前FunASR runtime-SDK-0.0.1版本已支持中文语音离线文件服务部署(CPU版本),拥有完整的语音识别链路,可以将几十个小时的音频识别成带标点的文字,而且支持上百路并发同时进行识别。 中文语音离线文件服务部署(CPU版本),拥有完整的语音识别链路,可以将几十个小时的音频与视频识别成带标点的文字,而且支持上百路请求同时进行转写。 为了支持不同用户的需求,针对不同场景,准备了不同的图文教程: 为了支持不同用户的需求,我们分别针对小白与高阶开发者,准备了不同的图文教程: ### 便捷部署教程 适用场景为,对服务部署SDK无修改需求,部署模型来自于ModelScope,或者用户finetune,详细教程参考([点击此处](./docs/SDK_tutorial_zh.md)) ### 开发指南 适用场景为,对服务部署SDK有修改需求,部署模型来自于ModelScope,或者用户finetune,详细文档参考([点击此处](./docs/SDK_advanced_guide_offline_zh.md)) ### 技术原理揭秘 文档介绍了背后技术原理,识别准确率,计算效率等,以及核心优势介绍:便捷、高精度、高效率、长音频链路,详细文档参考([点击此处](https://mp.weixin.qq.com/s?__biz=MzA3MTQ0NTUyMw==&tempkey=MTIyNF84d05USjMxSEpPdk5GZXBJUFNJNzY0bU1DTkxhV19mcWY4MTNWQTJSYXhUaFgxOWFHZTZKR0JzWC1JRmRCdUxCX2NoQXg0TzFpNmVJX2R1WjdrcC02N2FEcUc3MDhzVVhpNWQ5clU4QUdqNFdkdjFYb18xRjlZMmc5c3RDOTl0U0NiRkJLb05ZZ0RmRlVkVjFCZnpXNWFBVlRhbXVtdWs4bUMwSHZnfn4%3D&chksm=1f2c3254285bbb42bc8f76a82e9c5211518a0bb1ff8c357d085c1b78f675ef2311f3be6e282c#rd)) ### 便捷部署教程 文档主要针对小白用户与初级开发者,没有修改、定制需求,支持从modelscope中下载模型部署,也支持用户finetune后的模型部署,详细教程参考([点击此处](./docs/SDK_tutorial_cn.md)) ### 高阶开发指南 文档主要针对高阶开发者,需要对服务进行修改与定制,支持从modelscope中下载模型部署,也支持用户finetune后的模型部署,详细文档参考([点击此处](./docs/SDK_advanced_guide_cn.md)) funasr/runtime/run_server.sh
New file @@ -0,0 +1,25 @@ download_model_dir="/workspace/models" model_dir="damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx" vad_dir="damo/speech_fsmn_vad_zh-cn-16k-common-onnx" punc_dir="damo/punc_ct-transformer_zh-cn-common-vocab272727-onnx" decoder_thread_num=32 io_thread_num=8 port=10095 certfile="../../../ssl_key/server.crt" keyfile="../../../ssl_key/server.key" . ../../egs/aishell/transformer/utils/parse_options.sh || exit 1; cd /workspace/FunASR/funasr/runtime/websocket/build/bin ./funasr-wss-server \ --download-model-dir ${download_model_dir} \ --model-dir ${model_dir} \ --vad-dir ${vad_dir} \ --punc-dir ${punc_dir} \ --decoder-thread-num ${decoder_thread_num} \ --io-thread-num ${io_thread_num} \ --port ${port} \ --certfile ${certfile} \ --keyfile ${keyfile}
@@ -47,6 +47,7 @@ from funasr.models.e2e_sa_asr import SAASRModel from funasr.models.e2e_uni_asr import UniASR from funasr.models.e2e_asr_transducer import TransducerModel, UnifiedTransducerModel from funasr.models.e2e_asr_bat import BATModel from funasr.models.encoder.abs_encoder import AbsEncoder from funasr.models.encoder.conformer_encoder import ConformerEncoder, ConformerChunkEncoder from funasr.models.encoder.data2vec_encoder import Data2VecEncoder @@ -66,7 +67,7 @@ from funasr.models.postencoder.hugging_face_transformers_postencoder import ( HuggingFaceTransformersPostEncoder, # noqa: H301 ) from funasr.models.predictor.cif import CifPredictor, CifPredictorV2, CifPredictorV3 from funasr.models.predictor.cif import CifPredictor, CifPredictorV2, CifPredictorV3, BATPredictor from funasr.models.preencoder.abs_preencoder import AbsPreEncoder from funasr.models.preencoder.linear import LinearProjection from funasr.models.preencoder.sinc import LightweightSincConvs @@ -135,6 +136,7 @@ timestamp_prediction=TimestampPredictor, rnnt=TransducerModel, rnnt_unified=UnifiedTransducerModel, bat=BATModel, sa_asr=SAASRModel, ), type_check=FunASRModel, @@ -266,6 +268,7 @@ ctc_predictor=None, cif_predictor_v2=CifPredictorV2, cif_predictor_v3=CifPredictorV3, bat_predictor=BATPredictor, ), type_check=None, default="cif_predictor", @@ -1508,6 +1511,139 @@ return model class ASRBATTask(ASRTask): """ASR Boundary Aware Transducer Task definition.""" num_optimizers: int = 1 class_choices_list = [ model_choices, frontend_choices, specaug_choices, normalize_choices, encoder_choices, rnnt_decoder_choices, joint_network_choices, predictor_choices, ] trainer = Trainer @classmethod def build_model(cls, args: argparse.Namespace) -> BATModel: """Required data depending on task mode. Args: cls: ASRBATTask object. args: Task arguments. Return: model: ASR BAT model. """ assert check_argument_types() if isinstance(args.token_list, str): with open(args.token_list, encoding="utf-8") as f: token_list = [line.rstrip() for line in f] # Overwriting token_list to keep it as "portable". args.token_list = list(token_list) elif isinstance(args.token_list, (tuple, list)): token_list = list(args.token_list) else: raise RuntimeError("token_list must be str or list") vocab_size = len(token_list) logging.info(f"Vocabulary size: {vocab_size }") # 1. frontend if args.input_size is None: # Extract features in the model frontend_class = frontend_choices.get_class(args.frontend) frontend = frontend_class(**args.frontend_conf) input_size = frontend.output_size() else: # Give features from data-loader frontend = None input_size = args.input_size # 2. Data augmentation for spectrogram if args.specaug is not None: specaug_class = specaug_choices.get_class(args.specaug) specaug = specaug_class(**args.specaug_conf) else: specaug = None # 3. Normalization layer if args.normalize is not None: normalize_class = normalize_choices.get_class(args.normalize) normalize = normalize_class(**args.normalize_conf) else: normalize = None # 4. Encoder if getattr(args, "encoder", None) is not None: encoder_class = encoder_choices.get_class(args.encoder) encoder = encoder_class(input_size, **args.encoder_conf) else: encoder = Encoder(input_size, **args.encoder_conf) encoder_output_size = encoder.output_size() # 5. Decoder rnnt_decoder_class = rnnt_decoder_choices.get_class(args.rnnt_decoder) decoder = rnnt_decoder_class( vocab_size, **args.rnnt_decoder_conf, ) decoder_output_size = decoder.output_size if getattr(args, "decoder", None) is not None: att_decoder_class = decoder_choices.get_class(args.decoder) att_decoder = att_decoder_class( vocab_size=vocab_size, encoder_output_size=encoder_output_size, **args.decoder_conf, ) else: att_decoder = None # 6. Joint Network joint_network = JointNetwork( vocab_size, encoder_output_size, decoder_output_size, **args.joint_network_conf, ) predictor_class = predictor_choices.get_class(args.predictor) predictor = predictor_class(**args.predictor_conf) # 7. Build model try: model_class = model_choices.get_class(args.model) except AttributeError: model_class = model_choices.get_class("rnnt_unified") model = model_class( vocab_size=vocab_size, token_list=token_list, frontend=frontend, specaug=specaug, normalize=normalize, encoder=encoder, decoder=decoder, att_decoder=att_decoder, joint_network=joint_network, predictor=predictor, **args.model_conf, ) # 8. Initialize model if args.init is not None: raise NotImplementedError( "Currently not supported.", "Initialization part will be reworked in a short future.", ) #assert check_return_type(model) return model class ASRTaskSAASR(ASRTask): # If you need more than one optimizers, change this value

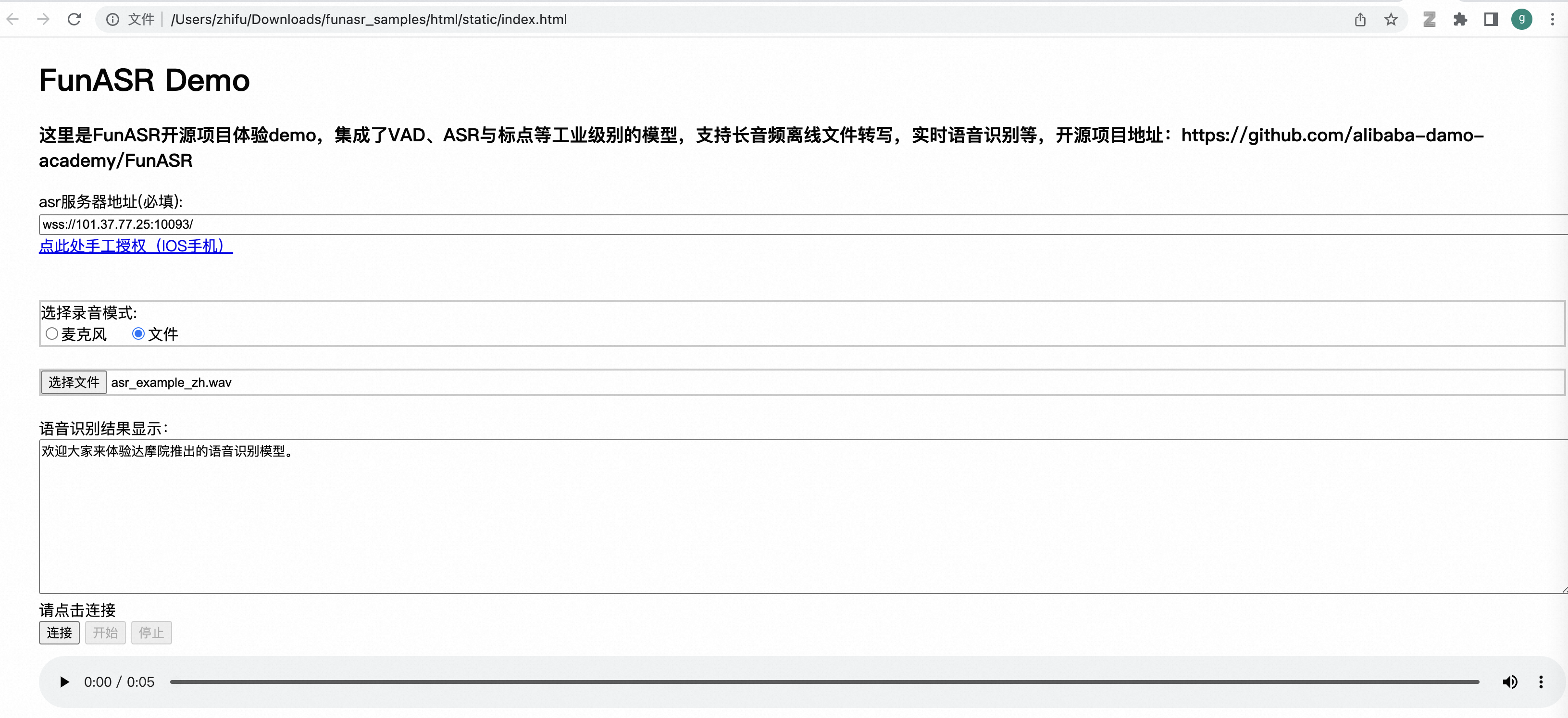
{kind=link}