Merge pull request #422 from alibaba-damo-academy/main
update with main
8个文件已修改
21个文件已删除
24个文件已添加
6 文件已复制
323 文件已重命名
| | |
|---|
| | | cp -r docs/_build/html/* public/en/ |
|---|
| | | mkdir public/m2met2 |
|---|
| | | touch public/m2met2/.nojekyll |
|---|
| | | cp -r docs_m2met2/_build/html/* public/m2met2/ |
|---|
| | | cp -r docs/m2met2/_build/html/* public/m2met2/ |
|---|
| | | mkdir public/m2met2_cn |
|---|
| | | touch public/m2met2_cn/.nojekyll |
|---|
| | | cp -r docs_m2met2_cn/_build/html/* public/m2met2_cn/ |
|---|
| | | cp -r docs/m2met2_cn/_build/html/* public/m2met2_cn/ |
|---|
| | | |
|---|
| | | - name: deploy github.io pages |
|---|
| | | if: github.ref == 'refs/heads/main' || github.ref == 'refs/heads/dev_wjm' || github.ref == 'refs/heads/dev_lyh' |
|---|
| | |
|---|
| | | | [**Runtime**](https://github.com/alibaba-damo-academy/FunASR/tree/main/funasr/runtime) |
|---|
| | | | [**Model Zoo**](https://github.com/alibaba-damo-academy/FunASR/blob/main/docs/modelscope_models.md) |
|---|
| | | | [**Contact**](#contact) |
|---|
| | | | |
|---|
| | | [**M2MET2.0 Guidence_CN**](https://alibaba-damo-academy.github.io/FunASR/m2met2_cn/index.html) |
|---|
| | | | [**M2MET2.0 Guidence_EN**](https://alibaba-damo-academy.github.io/FunASR/m2met2/index.html) |
|---|
| | | | [**M2MET2.0_CN**](https://alibaba-damo-academy.github.io/FunASR/m2met2_cn/index.html) |
|---|
| | | | [**M2MET2.0_EN**](https://alibaba-damo-academy.github.io/FunASR/m2met2/index.html) |
|---|
| | | |
|---|
| | | ## Multi-Channel Multi-Party Meeting Transcription 2.0 (M2MET2.0) Challenge |
|---|
| | | We are pleased to announce that the M2MeT2.0 challenge will be held in the near future. The baseline system is conducted on FunASR and is provided as a receipe of AliMeeting corpus. For more details you can see the guidence of M2MET2.0 ([CN](https://alibaba-damo-academy.github.io/FunASR/m2met2_cn/index.html)/[EN](https://alibaba-damo-academy.github.io/FunASR/m2met2/index.html)). |
|---|
| | | ## What's new: |
|---|
| | | |
|---|
| | | ### Multi-Channel Multi-Party Meeting Transcription 2.0 (M2MET2.0) Challenge |
|---|
| | | We are pleased to announce that the M2MeT2.0 challenge will be held in the near future. The baseline system is conducted on FunASR and is provided as a receipe of AliMeeting corpus. For more details you can see the guidence of M2MET2.0 ([CN](https://alibaba-damo-academy.github.io/FunASR/m2met2_cn/index.html)/[EN](https://alibaba-damo-academy.github.io/FunASR/m2met2/index.html)). |
|---|
| | | ### Release notes |
|---|
| | | For the release notes, please ref to [news](https://github.com/alibaba-damo-academy/FunASR/releases) |
|---|
| | | |
|---|
| | | ## Highlights |
|---|
| File was renamed from docs_m2met2/Dataset.md |
| | |
|---|
| | | ## Overview of training data |
|---|
| | | In the fixed training condition, the training dataset is restricted to three publicly available corpora, namely, AliMeeting, AISHELL-4, and CN-Celeb. To evaluate the performance of the models trained on these datasets, we will release a new Test set called Test-2023 for scoring and ranking. We will describe the AliMeeting dataset and the Test-2023 set in detail. |
|---|
| | | ## Detail of AliMeeting corpus |
|---|
| | | AliMeeting contains 118.75 hours of speech data in total. The dataset is divided into 104.75 hours for training (Train), 4 hours for evaluation (Eval) and 10 hours as test set (Test) for scoring and ranking. Specifically, the Train and Eval sets contain 212 and 8 sessions, respectively. Each session consists of a 15 to 30-minute discussion by a group of participants. The total number of participants in Train and Eval sets is 456 and 25, respectively, with balanced gender coverage. |
|---|
| | | AliMeeting contains 118.75 hours of speech data in total. The dataset is divided into 104.75 hours for training (Train), 4 hours for evaluation (Eval) and 10 hours as test set (Test) for scoring and ranking. Specifically, the Train, Eval and Test sets contain 212, 8 and 20 sessions, respectively. Each session consists of a 15 to 30-minute discussion by a group of participants. The total number of participants in Train, Eval and Test sets is 456, 25 and 60, respectively, with balanced gender coverage. |
|---|
| | | |
|---|
| | | The dataset is collected in 13 meeting venues, which are categorized into three types: small, medium, and large rooms with sizes ranging from 8 m$^{2}$ to 55 m$^{2}$. Different rooms give us a variety of acoustic properties and layouts. The detailed parameters of each meeting venue will be released together with the Train data. The type of wall material of the meeting venues covers cement, glass, etc. Other furnishings in meeting venues include sofa, TV, blackboard, fan, air conditioner, plants, etc. During recording, the participants of the meeting sit around the microphone array which is placed on the table and conduct a natural conversation. The microphone-speaker distance ranges from 0.3 m to 5.0 m. All participants are native Chinese speakers speaking Mandarin without strong accents. During the meeting, various kinds of indoor noise including but not limited to clicking, keyboard, door opening/closing, fan, bubble noise, etc., are made naturally. For both Train and Eval sets, the participants are required to remain in the same position during recording. There is no speaker overlap between the Train and Eval set. An example of the recording venue from the Train set is shown in Fig 1. |
|---|
| | | |
|---|
| File was renamed from docs_m2met2/Introduction.md |
| | |
|---|
| | | Building on the success of the previous M2MeT challenge, we are excited to propose the M2MeT2.0 challenge as an ASRU2023 challenge special session. In the original M2MeT challenge, the evaluation metric was speaker-independent, which meant that the transcription could be determined, but not the corresponding speaker. To address this limitation and further advance the current multi-talker ASR system towards practicality, the M2MeT2.0 challenge proposes the speaker-attributed ASR task with two sub-tracks: fixed and open training conditions. The speaker-attribute automatic speech recognition (ASR) task aims to tackle the practical and challenging problem of identifying "who spoke what at when". To facilitate reproducible research in this field, we offer a comprehensive overview of the dataset, rules, evaluation metrics, and baseline systems. Furthermore, we will release a carefully curated test set, comprising approximately 10 hours of audio, according to the timeline. The new test set is designed to enable researchers to validate and compare their models' performance and advance the state of the art in this area. |
|---|
| | | |
|---|
| | | ## Timeline(AOE Time) |
|---|
| | | |
|---|
| | | - $ May~5^{th}, 2023: $ Registration deadline, the due date for participants to join the Challenge. |
|---|
| | | - $ June~9^{th}, 2023: $ Test data release. |
|---|
| | | - $ June~13^{rd}, 2023: $ Final submission deadline. |
|---|
| | | - $ June~19^{th}, 2023: $ Evaluation result and ranking release. |
|---|
| | | - $ July~3^{rd}, 2023: $ Deadline for paper submission. |
|---|
| | | - $ July~10^{th}, 2023: $ Deadline for final paper submission. |
|---|
| | | - $ December~12^{nd}\ to\ 16^{th}, 2023: $ ASRU Workshop |
|---|
| | | - $ April~29, 2023: $ Challenge and registration open. |
|---|
| | | - $ May~8, 2023: $ Baseline release. |
|---|
| | | - $ May~15, 2023: $ Registration deadline, the due date for participants to join the Challenge. |
|---|
| | | - $ June~9, 2023: $ Test data release and leaderboard open. |
|---|
| | | - $ June~13, 2023: $ Final submission deadline. |
|---|
| | | - $ June~19, 2023: $ Evaluation result and ranking release. |
|---|
| | | - $ July~3, 2023: $ Deadline for paper submission. |
|---|
| | | - $ July~10, 2023: $ Deadline for final paper submission. |
|---|
| | | - $ December~12\ to\ 16, 2023: $ ASRU Workshop and challenge session |
|---|
| | | |
|---|
| | | ## Guidelines |
|---|
| | | |
|---|
| | | Interested participants, whether from academia or industry, must register for the challenge by completing a Google form, which will be available here. The deadline for registration is May 5, 2023. |
|---|
| | | Interested participants, whether from academia or industry, must register for the challenge by completing the Google form below. The deadline for registration is May 15, 2023. |
|---|
| | | |
|---|
| | | [M2MET2.0 Registration](https://docs.google.com/forms/d/e/1FAIpQLSf77T9vAl7Ym-u5g8gXu18SBofoWRaFShBo26Ym0-HDxHW9PQ/viewform?usp=sf_link) |
|---|
| | | |
|---|
| | | Within three working days, the challenge organizer will send email invitations to eligible teams to participate in the challenge. All qualified teams are required to adhere to the challenge rules, which will be published on the challenge page. Prior to the ranking release time, each participant must submit a system description document detailing their approach and methods. The organizer will select the top three submissions to be included in the ASRU2023 Proceedings. |
|---|
| File was renamed from docs_m2met2/Rules.md |
| | |
|---|
| | | - Data augmentation is allowed on the original training dataset, including, but not limited to, adding noise or reverberation, speed perturbation and tone change. |
|---|
| | | |
|---|
| | | - Participants are permitted to use the Eval set for model training, but it is not allowed to use the Test set for this purpose. Instead, the Test set should only be utilized for parameter tuning and model selection. Any use of the Test-2023 dataset that violates these rules is strictly prohibited, including but not limited to the use of the Test set for fine-tuning or training the model. |
|---|
| | | |
|---|
| | | - Multi-system fusion is allowed, but the systems with same structure and different parameters is not encouraged. |
|---|
| | | |
|---|
| | | - If the cpCER of the two systems on the Test dataset are the same, the system with lower computation complexity will be judged as the superior one. |
|---|
| | | |
|---|
| File was renamed from docs_m2met2/Track_setting_and_evaluation.md |
| | |
|---|
| | | # Track & Evaluation |
|---|
| | | ## Speaker-Attributed ASR (Main Track) |
|---|
| | | The speaker-attributed ASR task poses a unique challenge of transcribing speech from multiple speakers and assigning a speaker label to the transcription. Figure 2 illustrates the difference between the speaker-attributed ASR task and the multi-speaker ASR task. This track allows for the use of the AliMeeting, Aishell4, and Cn-Celeb datasets as constrained data sources during both training and evaluation. The AliMeeting dataset, which was used in the M2MeT challenge, includes Train, Eval, and Test sets. Additionally, a new Test-2023 set, consisting of approximately 10 hours of meeting data recorded in an identical acoustic setting as the AliMeeting corpus, will be released soon for challenge scoring and ranking. It's worth noting that the organizers will not provide the near-field audio, transcriptions, or oracle timestamps. Instead, segments containing multiple speakers will be provided on the Test-2023 set, which can be obtained using a simple voice activity detection (VAD) model. |
|---|
| | | ## Speaker-Attributed ASR |
|---|
| | | The speaker-attributed ASR task poses a unique challenge of transcribing speech from multiple speakers and assigning a speaker label to the transcription. Figure 2 illustrates the difference between the speaker-attributed ASR task and the multi-speaker ASR task. This track allows for the use of the AliMeeting, Aishell4, and Cn-Celeb datasets as constrained data sources during both training and evaluation. The AliMeeting dataset, which was used in the M2MeT challenge, includes Train, Eval, and Test sets. Additionally, a new Test-2023 set, consisting of approximately 10 hours of meeting data recorded in an identical acoustic setting as the AliMeeting corpus, will be released soon for challenge scoring and ranking. It's worth noting that the organizers will not provide the near-field audio, transcriptions, or oracle timestamps of the Test-2023 set. Instead, segments containing multiple speakers will be provided, which can be obtained using a simple voice activity detection (VAD) model. |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| File was renamed from docs_m2met2/_build/html/Baseline.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="Track_setting_and_evaluation.html">Track & Evaluation</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr-main-track">Speaker-Attributed ASR (Main Track)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr">Speaker-Attributed ASR</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#evaluation-metric">Evaluation metric</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#sub-track-arrangement">Sub-track arrangement</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | </section> |
|---|
| | | <section id="baseline-results"> |
|---|
| | | <h2>Baseline results<a class="headerlink" href="#baseline-results" title="Permalink to this heading">¶</a></h2> |
|---|
| | | <p>The results of the baseline system are shown in Table 3. The speaker profile adopts the oracle speaker embedding during training. However, due to the lack of oracle speaker label during evaluation, the speaker profile provided by an additional spectral clustering is used. Meanwhile, the results of using the oracle speaker profile on Eval and Test Set are also provided to show the impact of speaker profile accuracy. |
|---|
| | | <img alt="baseline result" src="_images/baseline_result.png" /></p> |
|---|
| | | <p>The results of the baseline system are shown in Table 3. The speaker profile adopts the oracle speaker embedding during training. However, due to the lack of oracle speaker label during evaluation, the speaker profile provided by an additional spectral clustering is used. Meanwhile, the results of using the oracle speaker profile on Eval and Test Set are also provided to show the impact of speaker profile accuracy.</p> |
|---|
| | | <p><img alt="baseline result" src="_images/baseline_result.png" /></p> |
|---|
| | | </section> |
|---|
| | | </section> |
|---|
| | | |
|---|
| File was renamed from docs_m2met2/_build/html/Contact.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="Track_setting_and_evaluation.html">Track & Evaluation</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr-main-track">Speaker-Attributed ASR (Main Track)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr">Speaker-Attributed ASR</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#evaluation-metric">Evaluation metric</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#sub-track-arrangement">Sub-track arrangement</a></li> |
|---|
| | | </ul> |
|---|
| File was renamed from docs_m2met2/_build/html/Dataset.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="Track_setting_and_evaluation.html">Track & Evaluation</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr-main-track">Speaker-Attributed ASR (Main Track)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr">Speaker-Attributed ASR</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#evaluation-metric">Evaluation metric</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#sub-track-arrangement">Sub-track arrangement</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | </section> |
|---|
| | | <section id="detail-of-alimeeting-corpus"> |
|---|
| | | <h2>Detail of AliMeeting corpus<a class="headerlink" href="#detail-of-alimeeting-corpus" title="Permalink to this heading">¶</a></h2> |
|---|
| | | <p>AliMeeting contains 118.75 hours of speech data in total. The dataset is divided into 104.75 hours for training (Train), 4 hours for evaluation (Eval) and 10 hours as test set (Test) for scoring and ranking. Specifically, the Train and Eval sets contain 212 and 8 sessions, respectively. Each session consists of a 15 to 30-minute discussion by a group of participants. The total number of participants in Train and Eval sets is 456 and 25, respectively, with balanced gender coverage.</p> |
|---|
| | | <p>AliMeeting contains 118.75 hours of speech data in total. The dataset is divided into 104.75 hours for training (Train), 4 hours for evaluation (Eval) and 10 hours as test set (Test) for scoring and ranking. Specifically, the Train, Eval and Test sets contain 212, 8 and 20 sessions, respectively. Each session consists of a 15 to 30-minute discussion by a group of participants. The total number of participants in Train, Eval and Test sets is 456, 25 and 60, respectively, with balanced gender coverage.</p> |
|---|
| | | <p>The dataset is collected in 13 meeting venues, which are categorized into three types: small, medium, and large rooms with sizes ranging from 8 m<span class="math notranslate nohighlight">\(^{2}\)</span> to 55 m<span class="math notranslate nohighlight">\(^{2}\)</span>. Different rooms give us a variety of acoustic properties and layouts. The detailed parameters of each meeting venue will be released together with the Train data. The type of wall material of the meeting venues covers cement, glass, etc. Other furnishings in meeting venues include sofa, TV, blackboard, fan, air conditioner, plants, etc. During recording, the participants of the meeting sit around the microphone array which is placed on the table and conduct a natural conversation. The microphone-speaker distance ranges from 0.3 m to 5.0 m. All participants are native Chinese speakers speaking Mandarin without strong accents. During the meeting, various kinds of indoor noise including but not limited to clicking, keyboard, door opening/closing, fan, bubble noise, etc., are made naturally. For both Train and Eval sets, the participants are required to remain in the same position during recording. There is no speaker overlap between the Train and Eval set. An example of the recording venue from the Train set is shown in Fig 1.</p> |
|---|
| | | <p><img alt="meeting room" src="_images/meeting_room.png" /></p> |
|---|
| | | <p>The number of participants within one meeting session ranges from 2 to 4. To ensure the coverage of different overlap ratios, we select various meeting topics during recording, including medical treatment, education, business, organization management, industrial production and other daily routine meetings. The average speech overlap ratio of Train, Eval and Test sets are 42.27%, 34.76% and 42.8%, respectively. More details of AliMeeting are shown in Table 1. A detailed overlap ratio distribution of meeting sessions with different numbers of speakers in the Train, Eval and Test set is shown in Table 2.</p> |
|---|
| File was renamed from docs_m2met2/_build/html/Introduction.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="Track_setting_and_evaluation.html">Track & Evaluation</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr-main-track">Speaker-Attributed ASR (Main Track)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr">Speaker-Attributed ASR</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#evaluation-metric">Evaluation metric</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#sub-track-arrangement">Sub-track arrangement</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | <section id="call-for-participation"> |
|---|
| | | <h2>Call for participation<a class="headerlink" href="#call-for-participation" title="Permalink to this heading">¶</a></h2> |
|---|
| | | <p>Automatic speech recognition (ASR) and speaker diarization have made significant strides in recent years, resulting in a surge of speech technology applications across various domains. However, meetings present unique challenges to speech technologies due to their complex acoustic conditions and diverse speaking styles, including overlapping speech, variable numbers of speakers, far-field signals in large conference rooms, and environmental noise and reverberation.</p> |
|---|
| | | <p>Over the years, several challenges have been organized to advance the development of meeting transcription, including the Rich Transcription evaluation and Computational Hearing in Multisource Environments (CHIME) challenges. The latest iteration of the CHIME challenge has a particular focus on distant automatic speech recognition (ASR) and developing systems that can generalize across various array topologies and application scenarios. However, while progress has been made in English meeting transcription, language differences remain a significant barrier to achieving comparable results in non-English languages, such as Mandarin.</p> |
|---|
| | | <p>The Multimodal Information Based Speech Processing (MISP) and Multi-Channel Multi-Party Meeting Transcription (M2MeT) challenges have been instrumental in advancing Mandarin meeting transcription. The MISP challenge seeks to address the problem of audio-visual distant multi-microphone signal processing in everyday home environments, while the M2MeT challenge focuses on tackling the speech overlap issue in offline meeting rooms.</p> |
|---|
| | | <p>The ICASSP2022 M2MeT challenge focuses on meeting scenarios, and it comprises two main tasks: speaker diarization and multi-speaker automatic speech recognition (ASR). The former involves identifying who spoke when in the meeting, while the latter aims to transcribe speech from multiple speakers simultaneously, which poses significant technical difficulties due to overlapping speech and acoustic interferences.</p> |
|---|
| | | <p>Building on the success of the previous M2MeT challenge, we are excited to propose the M2MeT2.0 challenge as an ASRU2023 challenge special session. In the original M2MeT challenge, the evaluation metric was speaker-independent, which meant that the transcription could be determined, but not the corresponding speaker. To address this limitation and further advance the current multi-talker ASR system towards practicality, the M2MeT2.0 challenge proposes the speaker-attributed ASR task with two sub-tracks: fixed and open training conditions. By attributing speech to specific speakers, this task aims to improve the accuracy and applicability of multi-talker ASR systems in real-world settings. The challenge provides detailed datasets, rules, evaluation methods, and baseline systems to facilitate reproducible research in this field. The speaker-attribute automatic speech recognition (ASR) task aims to tackle the practical and challenging problem of identifying âwho spoke what at whenâ. To facilitate reproducible research in this field, we offer a comprehensive overview of the dataset, rules, evaluation metrics, and baseline systems. Furthermore, we will release a carefully curated test set, comprising approximately 10 hours of audio, according to the timeline. The new test set is designed to enable researchers to validate and compare their modelsâ performance and advance the state of the art in this area.</p> |
|---|
| | | <p>Over the years, several challenges have been organized to advance the development of meeting transcription, including the Rich Transcription evaluation and Computational Hearing in Multisource Environments (CHIME) challenges. The latest iteration of the CHIME challenge has a particular focus on distant automatic speech recognition and developing systems that can generalize across various array topologies and application scenarios. However, while progress has been made in English meeting transcription, language differences remain a significant barrier to achieving comparable results in non-English languages, such as Mandarin. The Multimodal Information Based Speech Processing (MISP) and Multi-Channel Multi-Party Meeting Transcription (M2MeT) challenges have been instrumental in advancing Mandarin meeting transcription. The MISP challenge seeks to address the problem of audio-visual distant multi-microphone signal processing in everyday home environments, while the M2MeT challenge focuses on tackling the speech overlap issue in offline meeting rooms.</p> |
|---|
| | | <p>The ICASSP2022 M2MeT challenge focuses on meeting scenarios, and it comprises two main tasks: speaker diarization and multi-speaker automatic speech recognition. The former involves identifying who spoke when in the meeting, while the latter aims to transcribe speech from multiple speakers simultaneously, which poses significant technical difficulties due to overlapping speech and acoustic interferences.</p> |
|---|
| | | <p>Building on the success of the previous M2MeT challenge, we are excited to propose the M2MeT2.0 challenge as an ASRU2023 challenge special session. In the original M2MeT challenge, the evaluation metric was speaker-independent, which meant that the transcription could be determined, but not the corresponding speaker. To address this limitation and further advance the current multi-talker ASR system towards practicality, the M2MeT2.0 challenge proposes the speaker-attributed ASR task with two sub-tracks: fixed and open training conditions. The speaker-attribute automatic speech recognition (ASR) task aims to tackle the practical and challenging problem of identifying âwho spoke what at whenâ. To facilitate reproducible research in this field, we offer a comprehensive overview of the dataset, rules, evaluation metrics, and baseline systems. Furthermore, we will release a carefully curated test set, comprising approximately 10 hours of audio, according to the timeline. The new test set is designed to enable researchers to validate and compare their modelsâ performance and advance the state of the art in this area.</p> |
|---|
| | | </section> |
|---|
| | | <section id="timeline-aoe-time"> |
|---|
| | | <h2>Timeline(AOE Time)<a class="headerlink" href="#timeline-aoe-time" title="Permalink to this heading">¶</a></h2> |
|---|
| | | <ul class="simple"> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( May~5^{th}, 2023: \)</span> Registration deadline, the due date for participants to join the Challenge.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~9^{th}, 2023: \)</span> Test data release.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~13^{rd}, 2023: \)</span> Final submission deadline.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~19^{th}, 2023: \)</span> Evaluation result and ranking release.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( July~3^{rd}, 2023: \)</span> Deadline for paper submission.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( July~10^{th}, 2023: \)</span> Deadline for final paper submission.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( December~12^{nd}\ to\ 16^{th}, 2023: \)</span> ASRU Workshop</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( April~29, 2023: \)</span> Challenge and registration open.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( May~8, 2023: \)</span> Baseline release.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( May~15, 2023: \)</span> Registration deadline, the due date for participants to join the Challenge.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~9, 2023: \)</span> Test data release and leaderboard open.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~13, 2023: \)</span> Final submission deadline.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( June~19, 2023: \)</span> Evaluation result and ranking release.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( July~3, 2023: \)</span> Deadline for paper submission.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( July~10, 2023: \)</span> Deadline for final paper submission.</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( December~12\ to\ 16, 2023: \)</span> ASRU Workshop and challenge session</p></li> |
|---|
| | | </ul> |
|---|
| | | </section> |
|---|
| | | <section id="guidelines"> |
|---|
| | | <h2>Guidelines<a class="headerlink" href="#guidelines" title="Permalink to this heading">¶</a></h2> |
|---|
| | | <p>Possible improved version: Interested participants, whether from academia or industry, must register for the challenge by completing a Google form, which will be available here. The deadline for registration is May 5, 2023.</p> |
|---|
| | | <p>Interested participants, whether from academia or industry, must register for the challenge by completing the Google form below. The deadline for registration is May 15, 2023.</p> |
|---|
| | | <p><a class="reference external" href="https://docs.google.com/forms/d/e/1FAIpQLSf77T9vAl7Ym-u5g8gXu18SBofoWRaFShBo26Ym0-HDxHW9PQ/viewform?usp=sf_link">M2MET2.0 Registration</a></p> |
|---|
| | | <p>Within three working days, the challenge organizer will send email invitations to eligible teams to participate in the challenge. All qualified teams are required to adhere to the challenge rules, which will be published on the challenge page. Prior to the ranking release time, each participant must submit a system description document detailing their approach and methods. The organizer will select the top three submissions to be included in the ASRU2023 Proceedings.</p> |
|---|
| | | </section> |
|---|
| | | </section> |
|---|
| File was renamed from docs_m2met2/_build/html/Organizers.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="Track_setting_and_evaluation.html">Track & Evaluation</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr-main-track">Speaker-Attributed ASR (Main Track)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr">Speaker-Attributed ASR</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#evaluation-metric">Evaluation metric</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#sub-track-arrangement">Sub-track arrangement</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | <p><em><strong>Lei Xie, Professor, Northwestern Polytechnical University, China</strong></em></p> |
|---|
| | | <p>Email: <a class="reference external" href="mailto:lxie%40nwpu.edu.cn">lxie<span>@</span>nwpu<span>.</span>edu<span>.</span>cn</a></p> |
|---|
| | | <a class="reference internal image-reference" href="_images/lxie.jpeg"><img alt="lxie" src="_images/lxie.jpeg" style="width: 20%;" /></a> |
|---|
| | | <p>Lei Xie received the Ph.D. degree in computer science from Northwestern Polytechnical University, Xiâan, China, in 2004. From 2001 to 2002, he was with the Department of Electronics and Information Processing, Vrije Universiteit Brussel (VUB), Brussels, Belgium, as a Visiting Scientist. From 2004 to 2006, he was a Senior Research Associate with the Center for Media Technology, School of Creative Media, City University of Hong Kong, Hong Kong, China. From 2006 to 2007, he was a Postdoctoral Fellow with the Human-Computer Communications Laboratory (HCCL), The Chinese University of Hong Kong, Hong Kong, China. He is currently a Professor with School of Computer Science, Northwestern Polytechnical University, Xian, China and leads the Audio, Speech and Language Processing Group (ASLP@NPU). He has published over 200 papers in referred journals and conferences, such as IEEE/ACM Transactions on Audio, Speech and Language Processing, IEEE Transactions on Multimedia, Interspeech, ICASSP, ASRU, ACL and ACM Multimedia. He has achieved several best paper awards in flagship conferences. His current research interests include general topics in speech and language processing, multimedia, and human-computer interaction. Dr. Xie is currently an associate editor (AE) of IEEE/ACM Trans. on Audio, Speech and language Processing. He has actively served as Chairs in many conferences and technical committees. He serves as an IEEE Speech and Language Processing |
|---|
| | | Technical Committee Member.</p> |
|---|
| | | <p><em><strong>Kong Aik Lee, Senior Scientist at Institute for Infocomm Research, A*Star, Singapore</strong></em></p> |
|---|
| | | <p>Email: <a class="reference external" href="mailto:kongaik.lee%40ieee.org">kongaik<span>.</span>lee<span>@</span>ieee<span>.</span>org</a></p> |
|---|
| | | <a class="reference internal image-reference" href="_images/kong.png"><img alt="kong" src="_images/kong.png" style="width: 20%;" /></a> |
|---|
| | | <p>Kong Aik Lee started off him career as a researcher, then a team leader and a strategic planning manager, at the Institute Infocomm Research, A*STAR, Singapore, working on speaker and language recognition research. From 2018 to 2020, he spent two and a half years in NEC Corporation, Japan, focusing very much on voice biometrics and multi-modal biometrics products. He is proud to work with a great team on voice biometrics featured on NEC Bio-Idiom platform. He returned to Singapore in July 2020, and now leading the speech and audio analytics research at the Institute for Infocomm Research, as a Senior Scientist and PI. He also serve as an Editor for Elsevier Computer Speech and Language (since 2016), and was an Associate Editor for IEEE/ACM Transactions on Audio, Speech and Language Processing (2017 - 2021), and am an elected member of IEEE Speech and Language Technical Committee (2019 - 2021).</p> |
|---|
| | | <p><em><strong>Zhijie Yan, Principal Engineer at Alibaba, China</strong></em> |
|---|
| | | Email: <a class="reference external" href="mailto:zhijie.yzj%40alibaba-inc.com">zhijie<span>.</span>yzj<span>@</span>alibaba-inc<span>.</span>com</a></p> |
|---|
| | | <a class="reference internal image-reference" href="_images/zhijie.jpg"><img alt="zhijie" src="_images/zhijie.jpg" style="width: 20%;" /></a> |
|---|
| | | <p>Zhijie Yan holds a PhD from the University of Science and Technology of China, and is a senior member of the Institute of Electrical and Electronics Engineers (IEEE). He is also an expert reviewer of top academic conferences and journals in the speech field. His research fields include speech recognition, speech synthesis, voiceprints, and speech interaction. His research results are applied in speech services provided by Alibaba Group and Ant Financial. He was awarded the title of âOne of the Top 100 Grassroots Scientistsâ by the China Association for Science and Technology.</p> |
|---|
| | | <p><em><strong>Shiliang Zhang, Senior Engineer at Alibaba, China</strong></em> |
|---|
| | | Email: <a class="reference external" href="mailto:sly.zsl%40alibaba-inc.com">sly<span>.</span>zsl<span>@</span>alibaba-inc<span>.</span>com</a></p> |
|---|
| | | <a class="reference internal image-reference" href="_images/zsl.JPG"><img alt="zsl" src="_images/zsl.JPG" style="width: 20%;" /></a> |
|---|
| | | <p>Shiliang Zhang graduated with a Ph.D. from the University of Science and Technology of China in 2017. His research areas mainly include speech recognition, natural language understanding, and machine learning. Currently, he has published over 40 papers in mainstream academic journals and conferences in the fields of speech and machine learning, and has applied for dozens of patents. After obtaining his doctorate degree, he joined the Alibaba Intelligent Speech team. He is currently leading the direction of speech recognition and fundamental technology at DAMO Academyâs speech laboratory.</p> |
|---|
| | | <p><em><strong>Yanmin Qian, Professor, Shanghai Jiao Tong University, China</strong></em></p> |
|---|
| | | <p>Email: <a class="reference external" href="mailto:yanminqian%40sjtu.edu.cn">yanminqian<span>@</span>sjtu<span>.</span>edu<span>.</span>cn</a></p> |
|---|
| | | <a class="reference internal image-reference" href="_images/qian.jpeg"><img alt="qian" src="_images/qian.jpeg" style="width: 20%;" /></a> |
|---|
| | | <p>Yanmin Qian received the B.S. degree from the Department of Electronic and Information Engineering,Huazhong University of Science and Technology, Wuhan, China, in 2007, and the Ph.D. degree from the Department of Electronic Engineering, Tsinghua University, Beijing, China, in 2012. Since 2013, he has been with the Department of Computer Science and Engineering, Shanghai Jiao Tong University (SJTU), Shanghai, China, where he is currently an Associate Professor. From 2015 to 2016, he also worked as an Associate Research in the Speech Group, Cambridge University Engineering Department, Cambridge, U.K. He is a senior member of IEEE and a member of ISCA, and one of the founding members of Kaldi Speech Recognition Toolkit. He has published more than 110 papers on speech and language processing with 4000+ citations, including the top conference: ICASSP, INTERSPEECH and ASRU. His current research interests include the acoustic and language modeling in speech recognition, speaker and language recognition, key word spotting, and multimedia signal processing.</p> |
|---|
| | | <p><em><strong>Zhuo Chen, Applied Scientist in Microsoft, USA</strong></em></p> |
|---|
| | | <p>Email: <a class="reference external" href="mailto:zhuc%40microsoft.com">zhuc<span>@</span>microsoft<span>.</span>com</a></p> |
|---|
| | | <a class="reference internal image-reference" href="_images/chenzhuo.jpg"><img alt="chenzhuo" src="_images/chenzhuo.jpg" style="width: 20%;" /></a> |
|---|
| | | <p>Zhuo Chen received the Ph.D. degree from Columbia University, New York, NY, USA, in 2017. He is currently a Principal Applied Data Scientist with Microsoft. He has authored or coauthored more than 80 papers in peer-reviewed journals and conferences with around 6000 citations. He is a reviewer or technical committee member for more than ten journals and conferences. His research interests include automatic conversation recognition, speech separation, diarisation, and speaker information extraction. He actively participated in the academic events and challenges, and won several awards. Meanwhile, he contributed to open-sourced datasets, such as WSJ0-2mix, LibriCSS, and AISHELL-4, that have been main benchmark datasets for multi-speaker processing research. In 2020, he was the Team Leader in 2020 Jelinek workshop, leading more than 30 researchers and students to push the state of the art in conversation transcription.</p> |
|---|
| | | <p><em><strong>Jian Wu, Applied Scientist in Microsoft, USA</strong></em></p> |
|---|
| | | <p>Email: <a class="reference external" href="mailto:wujian%40microsoft.com">wujian<span>@</span>microsoft<span>.</span>com</a></p> |
|---|
| | | <a class="reference internal image-reference" href="_images/wujian.jpg"><img alt="wujian" src="_images/wujian.jpg" style="width: 20%;" /></a> |
|---|
| | | <p>Jian Wu received a master degree from Northwestern Polytechnical University, Xiâan, China, in 2020 and currently he is a Applied Scientist in Microsoft, USA. His research interests cover multi-channel signal processing, robust and multi-talker speech recognition, speech enhancement, dereverberation and separation. He has around 30 conference publications with a total citation over 1200. He participated in several challenges such as CHiME5, DNS 2020 and FFSVC 2020 and contributed to the open-sourced datasets including LibriCSS and AISHELL-4. He is also a reviewer for several journals and conferences such as ICASSP, SLT, TASLP and SPL.</p> |
|---|
| | | <p><em><strong>Hui Bu, CEO, AISHELL foundation, China</strong></em></p> |
|---|
| | | <p>Email: <a class="reference external" href="mailto:buhui%40aishelldata.com">buhui<span>@</span>aishelldata<span>.</span>com</a></p> |
|---|
| | | <a class="reference internal image-reference" href="_images/buhui.jpeg"><img alt="buhui" src="_images/buhui.jpeg" style="width: 20%;" /></a> |
|---|
| | | <p>Hui Bu received his master degree in the Artificial Intelligence Laboratory of Korea University in 2014. He is the founder and the CEO of AISHELL and AISHELL foundation. He participated in the release of AISHELL 1 & 2 & 3 & 4, DMASH and HI-MIA open source database project and is the co-founder of China Kaldi offline Technology Forum.</p> |
|---|
| | | </section> |
|---|
| | | |
|---|
| | | |
|---|
| File was renamed from docs_m2met2/_build/html/Rules.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="Track_setting_and_evaluation.html">Track & Evaluation</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr-main-track">Speaker-Attributed ASR (Main Track)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr">Speaker-Attributed ASR</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#evaluation-metric">Evaluation metric</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#sub-track-arrangement">Sub-track arrangement</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | <ul class="simple"> |
|---|
| | | <li><p>Data augmentation is allowed on the original training dataset, including, but not limited to, adding noise or reverberation, speed perturbation and tone change.</p></li> |
|---|
| | | <li><p>Participants are permitted to use the Eval set for model training, but it is not allowed to use the Test set for this purpose. Instead, the Test set should only be utilized for parameter tuning and model selection. Any use of the Test-2023 dataset that violates these rules is strictly prohibited, including but not limited to the use of the Test set for fine-tuning or training the model.</p></li> |
|---|
| | | <li><p>Multi-system fusion is allowed, but the systems with same structure and different parameters is not encouraged.</p></li> |
|---|
| | | <li><p>If the cpCER of the two systems on the Test dataset are the same, the system with lower computation complexity will be judged as the superior one.</p></li> |
|---|
| | | <li><p>If the forced alignment is used to obtain the frame-level classification label, the forced alignment model must be trained on the basis of the data allowed by the corresponding sub-track.</p></li> |
|---|
| | | <li><p>Shallow fusion is allowed to the end-to-end approaches, e.g., LAS, RNNT and Transformer, but the training data of the shallow fusion language model can only come from the transcripts of the allowed training dataset.</p></li> |
|---|
| File was renamed from docs_m2met2/_build/html/Track_setting_and_evaluation.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1 current"><a class="current reference internal" href="#">Track & Evaluation</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="#speaker-attributed-asr-main-track">Speaker-Attributed ASR (Main Track)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="#speaker-attributed-asr">Speaker-Attributed ASR</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="#evaluation-metric">Evaluation metric</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="#sub-track-arrangement">Sub-track arrangement</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | |
|---|
| | | <section id="track-evaluation"> |
|---|
| | | <h1>Track & Evaluation<a class="headerlink" href="#track-evaluation" title="Permalink to this heading">¶</a></h1> |
|---|
| | | <section id="speaker-attributed-asr-main-track"> |
|---|
| | | <h2>Speaker-Attributed ASR (Main Track)<a class="headerlink" href="#speaker-attributed-asr-main-track" title="Permalink to this heading">¶</a></h2> |
|---|
| | | <p>The speaker-attributed ASR task poses a unique challenge of transcribing speech from multiple speakers and assigning a speaker label to the transcription. Figure 2 illustrates the difference between the speaker-attributed ASR task and the multi-speaker ASR task. This track allows for the use of the AliMeeting, Aishell4, and Cn-Celeb datasets as constrained data sources during both training and evaluation. The AliMeeting dataset, which was used in the M2MeT challenge, includes Train, Eval, and Test sets. Additionally, a new Test-2023 set, consisting of approximately 10 hours of meeting data recorded in an identical acoustic setting as the AliMeeting corpus, will be released soon for challenge scoring and ranking. Itâs worth noting that the organizers will not provide the near-field audio, transcriptions, or oracle timestamps. Instead, segments containing multiple speakers will be provided on the Test-2023 set, which can be obtained using a simple voice activity detection (VAD) model.</p> |
|---|
| | | <section id="speaker-attributed-asr"> |
|---|
| | | <h2>Speaker-Attributed ASR<a class="headerlink" href="#speaker-attributed-asr" title="Permalink to this heading">¶</a></h2> |
|---|
| | | <p>The speaker-attributed ASR task poses a unique challenge of transcribing speech from multiple speakers and assigning a speaker label to the transcription. Figure 2 illustrates the difference between the speaker-attributed ASR task and the multi-speaker ASR task. This track allows for the use of the AliMeeting, Aishell4, and Cn-Celeb datasets as constrained data sources during both training and evaluation. The AliMeeting dataset, which was used in the M2MeT challenge, includes Train, Eval, and Test sets. Additionally, a new Test-2023 set, consisting of approximately 10 hours of meeting data recorded in an identical acoustic setting as the AliMeeting corpus, will be released soon for challenge scoring and ranking. Itâs worth noting that the organizers will not provide the near-field audio, transcriptions, or oracle timestamps of the Test-2023 set. Instead, segments containing multiple speakers will be provided, which can be obtained using a simple voice activity detection (VAD) model.</p> |
|---|
| | | <p><img alt="task difference" src="_images/task_diff.png" /></p> |
|---|
| | | </section> |
|---|
| | | <section id="evaluation-metric"> |
|---|
copy from docs_m2met2/Baseline.md
copy to docs/m2met2/_build/html/_sources/Baseline.md.txt
| File was renamed from docs_m2met2/_build/html/_sources/Dataset.md.txt |
| | |
|---|
| | | ## Overview of training data |
|---|
| | | In the fixed training condition, the training dataset is restricted to three publicly available corpora, namely, AliMeeting, AISHELL-4, and CN-Celeb. To evaluate the performance of the models trained on these datasets, we will release a new Test set called Test-2023 for scoring and ranking. We will describe the AliMeeting dataset and the Test-2023 set in detail. |
|---|
| | | ## Detail of AliMeeting corpus |
|---|
| | | AliMeeting contains 118.75 hours of speech data in total. The dataset is divided into 104.75 hours for training (Train), 4 hours for evaluation (Eval) and 10 hours as test set (Test) for scoring and ranking. Specifically, the Train and Eval sets contain 212 and 8 sessions, respectively. Each session consists of a 15 to 30-minute discussion by a group of participants. The total number of participants in Train and Eval sets is 456 and 25, respectively, with balanced gender coverage. |
|---|
| | | AliMeeting contains 118.75 hours of speech data in total. The dataset is divided into 104.75 hours for training (Train), 4 hours for evaluation (Eval) and 10 hours as test set (Test) for scoring and ranking. Specifically, the Train, Eval and Test sets contain 212, 8 and 20 sessions, respectively. Each session consists of a 15 to 30-minute discussion by a group of participants. The total number of participants in Train, Eval and Test sets is 456, 25 and 60, respectively, with balanced gender coverage. |
|---|
| | | |
|---|
| | | The dataset is collected in 13 meeting venues, which are categorized into three types: small, medium, and large rooms with sizes ranging from 8 m$^{2}$ to 55 m$^{2}$. Different rooms give us a variety of acoustic properties and layouts. The detailed parameters of each meeting venue will be released together with the Train data. The type of wall material of the meeting venues covers cement, glass, etc. Other furnishings in meeting venues include sofa, TV, blackboard, fan, air conditioner, plants, etc. During recording, the participants of the meeting sit around the microphone array which is placed on the table and conduct a natural conversation. The microphone-speaker distance ranges from 0.3 m to 5.0 m. All participants are native Chinese speakers speaking Mandarin without strong accents. During the meeting, various kinds of indoor noise including but not limited to clicking, keyboard, door opening/closing, fan, bubble noise, etc., are made naturally. For both Train and Eval sets, the participants are required to remain in the same position during recording. There is no speaker overlap between the Train and Eval set. An example of the recording venue from the Train set is shown in Fig 1. |
|---|
| | | |
|---|
copy from docs_m2met2/Introduction.md
copy to docs/m2met2/_build/html/_sources/Introduction.md.txt
| File was copied from docs_m2met2/Introduction.md |
| | |
|---|
| | | Building on the success of the previous M2MeT challenge, we are excited to propose the M2MeT2.0 challenge as an ASRU2023 challenge special session. In the original M2MeT challenge, the evaluation metric was speaker-independent, which meant that the transcription could be determined, but not the corresponding speaker. To address this limitation and further advance the current multi-talker ASR system towards practicality, the M2MeT2.0 challenge proposes the speaker-attributed ASR task with two sub-tracks: fixed and open training conditions. The speaker-attribute automatic speech recognition (ASR) task aims to tackle the practical and challenging problem of identifying "who spoke what at when". To facilitate reproducible research in this field, we offer a comprehensive overview of the dataset, rules, evaluation metrics, and baseline systems. Furthermore, we will release a carefully curated test set, comprising approximately 10 hours of audio, according to the timeline. The new test set is designed to enable researchers to validate and compare their models' performance and advance the state of the art in this area. |
|---|
| | | |
|---|
| | | ## Timeline(AOE Time) |
|---|
| | | |
|---|
| | | - $ May~5^{th}, 2023: $ Registration deadline, the due date for participants to join the Challenge. |
|---|
| | | - $ June~9^{th}, 2023: $ Test data release. |
|---|
| | | - $ June~13^{rd}, 2023: $ Final submission deadline. |
|---|
| | | - $ June~19^{th}, 2023: $ Evaluation result and ranking release. |
|---|
| | | - $ July~3^{rd}, 2023: $ Deadline for paper submission. |
|---|
| | | - $ July~10^{th}, 2023: $ Deadline for final paper submission. |
|---|
| | | - $ December~12^{nd}\ to\ 16^{th}, 2023: $ ASRU Workshop |
|---|
| | | - $ April~29, 2023: $ Challenge and registration open. |
|---|
| | | - $ May~8, 2023: $ Baseline release. |
|---|
| | | - $ May~15, 2023: $ Registration deadline, the due date for participants to join the Challenge. |
|---|
| | | - $ June~9, 2023: $ Test data release and leaderboard open. |
|---|
| | | - $ June~13, 2023: $ Final submission deadline. |
|---|
| | | - $ June~19, 2023: $ Evaluation result and ranking release. |
|---|
| | | - $ July~3, 2023: $ Deadline for paper submission. |
|---|
| | | - $ July~10, 2023: $ Deadline for final paper submission. |
|---|
| | | - $ December~12\ to\ 16, 2023: $ ASRU Workshop and challenge session |
|---|
| | | |
|---|
| | | ## Guidelines |
|---|
| | | |
|---|
| | | Interested participants, whether from academia or industry, must register for the challenge by completing a Google form, which will be available here. The deadline for registration is May 5, 2023. |
|---|
| | | Interested participants, whether from academia or industry, must register for the challenge by completing the Google form below. The deadline for registration is May 15, 2023. |
|---|
| | | |
|---|
| | | [M2MET2.0 Registration](https://docs.google.com/forms/d/e/1FAIpQLSf77T9vAl7Ym-u5g8gXu18SBofoWRaFShBo26Ym0-HDxHW9PQ/viewform?usp=sf_link) |
|---|
| | | |
|---|
| | | Within three working days, the challenge organizer will send email invitations to eligible teams to participate in the challenge. All qualified teams are required to adhere to the challenge rules, which will be published on the challenge page. Prior to the ranking release time, each participant must submit a system description document detailing their approach and methods. The organizer will select the top three submissions to be included in the ASRU2023 Proceedings. |
|---|
copy from docs_m2met2/Organizers.md
copy to docs/m2met2/_build/html/_sources/Organizers.md.txt
| File was renamed from docs_m2met2/_build/html/_sources/Rules.md.txt |
| | |
|---|
| | | - Data augmentation is allowed on the original training dataset, including, but not limited to, adding noise or reverberation, speed perturbation and tone change. |
|---|
| | | |
|---|
| | | - Participants are permitted to use the Eval set for model training, but it is not allowed to use the Test set for this purpose. Instead, the Test set should only be utilized for parameter tuning and model selection. Any use of the Test-2023 dataset that violates these rules is strictly prohibited, including but not limited to the use of the Test set for fine-tuning or training the model. |
|---|
| | | |
|---|
| | | - Multi-system fusion is allowed, but the systems with same structure and different parameters is not encouraged. |
|---|
| | | |
|---|
| | | - If the cpCER of the two systems on the Test dataset are the same, the system with lower computation complexity will be judged as the superior one. |
|---|
| | | |
|---|
copy from docs_m2met2/Track_setting_and_evaluation.md
copy to docs/m2met2/_build/html/_sources/Track_setting_and_evaluation.md.txt
| File was copied from docs_m2met2/Track_setting_and_evaluation.md |
| | |
|---|
| | | # Track & Evaluation |
|---|
| | | ## Speaker-Attributed ASR (Main Track) |
|---|
| | | The speaker-attributed ASR task poses a unique challenge of transcribing speech from multiple speakers and assigning a speaker label to the transcription. Figure 2 illustrates the difference between the speaker-attributed ASR task and the multi-speaker ASR task. This track allows for the use of the AliMeeting, Aishell4, and Cn-Celeb datasets as constrained data sources during both training and evaluation. The AliMeeting dataset, which was used in the M2MeT challenge, includes Train, Eval, and Test sets. Additionally, a new Test-2023 set, consisting of approximately 10 hours of meeting data recorded in an identical acoustic setting as the AliMeeting corpus, will be released soon for challenge scoring and ranking. It's worth noting that the organizers will not provide the near-field audio, transcriptions, or oracle timestamps. Instead, segments containing multiple speakers will be provided on the Test-2023 set, which can be obtained using a simple voice activity detection (VAD) model. |
|---|
| | | ## Speaker-Attributed ASR |
|---|
| | | The speaker-attributed ASR task poses a unique challenge of transcribing speech from multiple speakers and assigning a speaker label to the transcription. Figure 2 illustrates the difference between the speaker-attributed ASR task and the multi-speaker ASR task. This track allows for the use of the AliMeeting, Aishell4, and Cn-Celeb datasets as constrained data sources during both training and evaluation. The AliMeeting dataset, which was used in the M2MeT challenge, includes Train, Eval, and Test sets. Additionally, a new Test-2023 set, consisting of approximately 10 hours of meeting data recorded in an identical acoustic setting as the AliMeeting corpus, will be released soon for challenge scoring and ranking. It's worth noting that the organizers will not provide the near-field audio, transcriptions, or oracle timestamps of the Test-2023 set. Instead, segments containing multiple speakers will be provided, which can be obtained using a simple voice activity detection (VAD) model. |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| File was renamed from docs_m2met2/_build/html/_sources/index.rst.txt |
| | |
|---|
| | | ./Rules |
|---|
| | | ./Organizers |
|---|
| | | ./Contact |
|---|
| | | |
|---|
| | | Indices and tables |
|---|
| | | ================== |
|---|
| | | |
|---|
| | | * :ref:`genindex` |
|---|
| | | * :ref:`modindex` |
|---|
| | | * :ref:`search` |
|---|
| File was renamed from docs_m2met2/_build/html/genindex.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="Track_setting_and_evaluation.html">Track & Evaluation</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr-main-track">Speaker-Attributed ASR (Main Track)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr">Speaker-Attributed ASR</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#evaluation-metric">Evaluation metric</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#sub-track-arrangement">Sub-track arrangement</a></li> |
|---|
| | | </ul> |
|---|
| File was renamed from docs_m2met2/_build/html/index.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="Track_setting_and_evaluation.html">Track & Evaluation</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr-main-track">Speaker-Attributed ASR (Main Track)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr">Speaker-Attributed ASR</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#evaluation-metric">Evaluation metric</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#sub-track-arrangement">Sub-track arrangement</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="Contact.html">Contact</a></li> |
|---|
| | | </ul> |
|---|
| | | </div> |
|---|
| | | </section> |
|---|
| | | <section id="indices-and-tables"> |
|---|
| | | <h1>Indices and tables<a class="headerlink" href="#indices-and-tables" title="Permalink to this heading">¶</a></h1> |
|---|
| | | <ul class="simple"> |
|---|
| | | <li><p><a class="reference internal" href="genindex.html"><span class="std std-ref">Index</span></a></p></li> |
|---|
| | | <li><p><a class="reference internal" href="py-modindex.html"><span class="std std-ref">Module Index</span></a></p></li> |
|---|
| | | <li><p><a class="reference internal" href="search.html"><span class="std std-ref">Search Page</span></a></p></li> |
|---|
| | | </ul> |
|---|
| | | </section> |
|---|
| | | |
|---|
| | | |
|---|
| File was renamed from docs_m2met2/_build/html/search.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="Track_setting_and_evaluation.html">Track & Evaluation</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr-main-track">Speaker-Attributed ASR (Main Track)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#speaker-attributed-asr">Speaker-Attributed ASR</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#evaluation-metric">Evaluation metric</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="Track_setting_and_evaluation.html#sub-track-arrangement">Sub-track arrangement</a></li> |
|---|
| | | </ul> |
|---|
| New file |
| | |
|---|
| | | Search.setIndex({"docnames": ["Baseline", "Contact", "Dataset", "Introduction", "Organizers", "Rules", "Track_setting_and_evaluation", "index"], "filenames": ["Baseline.md", "Contact.md", "Dataset.md", "Introduction.md", "Organizers.md", "Rules.md", "Track_setting_and_evaluation.md", "index.rst"], "titles": ["Baseline", "Contact", "Datasets", "Introduction", "Organizers", "Rules", "Track & Evaluation", "ASRU 2023 MULTI-CHANNEL MULTI-PARTY MEETING TRANSCRIPTION CHALLENGE 2.0 (M2MeT2.0)"], "terms": {"we": [0, 2, 3, 7], "releas": [0, 2, 3, 6], "an": [0, 2, 3, 6], "e2": 0, "sa": 0, "asr": [0, 3, 7], "cite": 0, "kanda21b_interspeech": 0, "conduct": [0, 2], "funasr": 0, "time": [0, 6], "accord": [0, 3], "timelin": [0, 2], "The": [0, 2, 3, 5, 6], "model": [0, 2, 3, 5, 6], "architectur": 0, "i": [0, 2, 3, 5], "shown": [0, 2], "figur": [0, 6], "3": [0, 2, 3], "speakerencod": 0, "initi": 0, "pre": [0, 6], "train": [0, 3, 5, 7], "speaker": [0, 2, 3, 7], "verif": 0, "from": [0, 2, 3, 5, 6], "modelscop": [0, 6], "thi": [0, 3, 5, 6], "also": [0, 2, 6], "us": [0, 2, 5, 6], "extract": 0, "embed": 0, "profil": 0, "todo": 0, "fill": 0, "readm": 0, "md": 0, "system": [0, 3, 5, 6, 7], "ar": [0, 2, 3, 5, 6, 7], "tabl": [0, 2], "adopt": 0, "oracl": [0, 6], "dure": [0, 2, 6], "howev": [0, 3, 6], "due": [0, 3], "lack": 0, "label": [0, 5, 6], "evalu": [0, 2, 3, 7], "provid": [0, 2, 6, 7], "addit": [0, 6], "spectral": 0, "cluster": 0, "meanwhil": 0, "eval": [0, 2, 5, 6], "test": [0, 2, 3, 5, 6], "set": [0, 2, 3, 5, 6], "show": 0, "impact": 0, "accuraci": [0, 6], "If": [1, 5, 6], "you": 1, "have": [1, 3], "ani": [1, 5, 6], "question": 1, "about": 1, "m2met2": [1, 3], "0": [1, 2, 3], "challeng": [1, 3, 5, 6], "pleas": 1, "u": [1, 2], "email": [1, 3, 4], "m2met": [1, 3, 6, 7], "alimeet": [1, 6], "gmail": 1, "com": [1, 4], "wechat": 1, "group": [1, 2], "In": [2, 3, 5], "fix": [2, 3, 7], "condit": [2, 3, 7], "restrict": 2, "three": [2, 3, 6], "publicli": [2, 6], "avail": [2, 6], "corpora": 2, "name": 2, "aishel": [2, 4, 6], "4": [2, 6], "cn": [2, 4, 6], "celeb": [2, 6], "To": [2, 3, 7], "perform": [2, 3], "new": [2, 3, 6], "call": 2, "2023": [2, 3, 5, 6], "score": [2, 6], "rank": [2, 3, 6], "describ": 2, "contain": [2, 6], "118": 2, "75": 2, "hour": [2, 3, 6], "speech": [2, 3, 6, 7], "total": [2, 6], "divid": [2, 6], "104": 2, "10": [2, 3, 6], "specif": [2, 6], "212": 2, "8": [2, 3], "20": 2, "session": [2, 3, 6, 7], "respect": 2, "each": [2, 3, 6], "consist": [2, 6], "15": [2, 3], "30": 2, "minut": 2, "discuss": 2, "particip": [2, 5, 6], "number": [2, 3, 6], "456": 2, "25": 2, "60": 2, "balanc": 2, "gender": 2, "coverag": 2, "collect": 2, "13": [2, 3], "meet": [2, 3, 6], "venu": 2, "which": [2, 3, 6], "categor": 2, "type": 2, "small": 2, "medium": 2, "larg": [2, 3], "room": [2, 3], "size": 2, "rang": 2, "m": 2, "2": [2, 6], "55": 2, "differ": [2, 3, 6], "give": 2, "varieti": 2, "acoust": [2, 3, 6], "properti": 2, "layout": 2, "paramet": [2, 5], "togeth": 2, "wall": 2, "materi": 2, "cover": 2, "cement": 2, "glass": 2, "etc": 2, "other": 2, "furnish": 2, "includ": [2, 3, 5, 6], "sofa": 2, "tv": 2, "blackboard": 2, "fan": 2, "air": 2, "condition": 2, "plant": 2, "record": [2, 6], "sit": 2, "around": 2, "microphon": [2, 3], "arrai": [2, 3], "place": 2, "natur": 2, "convers": 2, "distanc": 2, "5": 2, "all": [2, 3, 5, 6], "nativ": 2, "chines": 2, "speak": [2, 3], "mandarin": [2, 3], "without": 2, "strong": 2, "accent": 2, "variou": [2, 3], "kind": 2, "indoor": 2, "nois": [2, 3, 5], "limit": [2, 3, 5], "click": 2, "keyboard": 2, "door": 2, "open": [2, 3, 7], "close": 2, "bubbl": 2, "made": [2, 3], "For": 2, "both": [2, 6], "requir": [2, 3, 6], "remain": [2, 3], "same": [2, 5], "posit": 2, "There": 2, "overlap": [2, 3], "between": [2, 6], "exampl": 2, "fig": 2, "1": 2, "within": [2, 3], "one": [2, 5], "ensur": 2, "ratio": 2, "select": [2, 3, 5, 6], "topic": 2, "medic": 2, "treatment": 2, "educ": 2, "busi": 2, "organ": [2, 3, 5, 6, 7], "manag": 2, "industri": [2, 3], "product": 2, "daili": 2, "routin": 2, "averag": 2, "42": 2, "27": 2, "34": 2, "76": 2, "more": 2, "A": [2, 4], "distribut": 2, "were": 2, "ident": [2, 6], "compris": [2, 3, 7], "therebi": 2, "share": 2, "similar": 2, "configur": 2, "field": [2, 3, 6], "signal": [2, 3], "headset": 2, "onli": [2, 5, 6], "": [2, 6], "own": 2, "transcrib": [2, 3, 6], "It": [2, 6], "worth": [2, 6], "note": [2, 6], "far": [2, 3], "audio": [2, 3, 6], "synchron": 2, "common": 2, "transcript": [2, 3, 5, 6], "prepar": 2, "textgrid": 2, "format": 2, "inform": [2, 3], "durat": 2, "id": 2, "segment": [2, 6], "timestamp": [2, 6], "mention": 2, "abov": 2, "can": [2, 3, 5, 6], "download": 2, "openslr": 2, "via": 2, "follow": [2, 5], "link": 2, "particularli": 2, "baselin": [2, 3, 7], "conveni": 2, "script": 2, "automat": [3, 7], "recognit": [3, 7], "diariz": 3, "signific": 3, "stride": 3, "recent": 3, "year": 3, "result": 3, "surg": 3, "technologi": 3, "applic": 3, "across": 3, "domain": 3, "present": 3, "uniqu": [3, 6], "complex": [3, 5], "divers": 3, "style": 3, "variabl": 3, "confer": 3, "environment": 3, "reverber": [3, 5], "over": 3, "sever": 3, "been": 3, "advanc": [3, 7], "develop": [3, 6], "rich": 3, "comput": [3, 5], "hear": 3, "multisourc": 3, "environ": 3, "chime": 3, "latest": 3, "iter": 3, "ha": 3, "particular": 3, "focu": 3, "distant": 3, "gener": 3, "topologi": 3, "scenario": 3, "while": 3, "progress": 3, "english": 3, "languag": [3, 5], "barrier": 3, "achiev": 3, "compar": 3, "non": 3, "multimod": 3, "base": 3, "process": [3, 6], "misp": 3, "multi": [3, 6], "channel": 3, "parti": [3, 6], "instrument": 3, "seek": 3, "address": 3, "problem": 3, "visual": 3, "everydai": 3, "home": 3, "focus": 3, "tackl": 3, "issu": 3, "offlin": 3, "icassp2022": 3, "two": [3, 5, 7], "main": 3, "task": [3, 6, 7], "former": 3, "involv": [3, 6], "identifi": 3, "who": 3, "spoke": 3, "when": 3, "latter": 3, "aim": 3, "multipl": [3, 6], "simultan": 3, "pose": [3, 6], "technic": 3, "difficulti": 3, "interfer": 3, "build": [3, 6, 7], "success": [3, 7], "previou": 3, "excit": 3, "propos": [3, 7], "asru2023": [3, 7], "special": [3, 5, 7], "origin": [3, 5], "metric": [3, 7], "wa": [3, 6], "independ": 3, "meant": 3, "could": 3, "determin": 3, "correspond": [3, 5], "further": 3, "current": [3, 7], "talker": [3, 7], "toward": 3, "practic": 3, "attribut": [3, 7], "sub": [3, 5, 7], "track": [3, 5, 7], "what": 3, "facilit": [3, 7], "reproduc": [3, 7], "research": [3, 4, 7], "offer": 3, "comprehens": [3, 7], "overview": [3, 7], "dataset": [3, 5, 6, 7], "rule": [3, 7], "furthermor": 3, "carefulli": 3, "curat": 3, "approxim": [3, 6], "design": 3, "enabl": 3, "valid": 3, "state": [3, 6, 7], "art": [3, 7], "area": 3, "april": 3, "29": 3, "registr": 3, "mai": 3, "deadlin": 3, "date": 3, "join": 3, "june": 3, "9": 3, "data": [3, 5, 6], "leaderboard": 3, "final": [3, 5, 6], "submiss": 3, "19": 3, "juli": 3, "paper": [3, 6], "decemb": 3, "12": 3, "16": 3, "asru": 3, "workshop": 3, "interest": 3, "whether": 3, "academia": 3, "must": [3, 5, 6], "regist": 3, "complet": 3, "googl": 3, "form": 3, "below": 3, "work": 3, "dai": 3, "send": 3, "invit": 3, "elig": [3, 5], "team": 3, "qualifi": 3, "adher": [3, 5], "publish": 3, "page": 3, "prior": 3, "submit": 3, "descript": [3, 6], "document": 3, "detail": [3, 6], "approach": [3, 5], "method": 3, "top": 3, "proceed": 3, "lei": 4, "xie": 4, "professor": 4, "northwestern": 4, "polytechn": 4, "univers": 4, "china": 4, "lxie": 4, "nwpu": 4, "edu": 4, "kong": 4, "aik": 4, "lee": 4, "senior": 4, "scientist": 4, "institut": 4, "infocomm": 4, "star": 4, "singapor": 4, "kongaik": 4, "ieee": 4, "org": 4, "zhiji": 4, "yan": 4, "princip": 4, "engin": 4, "alibaba": 4, "yzj": 4, "inc": 4, "shiliang": 4, "zhang": 4, "sly": 4, "zsl": 4, "yanmin": 4, "qian": 4, "shanghai": 4, "jiao": 4, "tong": 4, "yanminqian": 4, "sjtu": 4, "zhuo": 4, "chen": 4, "appli": 4, "microsoft": 4, "usa": 4, "zhuc": 4, "jian": 4, "wu": 4, "wujian": 4, "hui": 4, "bu": 4, "ceo": 4, "foundat": 4, "buhui": 4, "aishelldata": 4, "should": 5, "augment": 5, "allow": [5, 6], "ad": 5, "speed": 5, "perturb": 5, "tone": 5, "chang": 5, "permit": 5, "purpos": 5, "instead": [5, 6], "util": [5, 6], "tune": 5, "violat": 5, "strictli": [5, 6], "prohibit": [5, 6], "fine": 5, "cpcer": [5, 6], "lower": 5, "judg": 5, "superior": 5, "forc": 5, "align": 5, "obtain": [5, 6], "frame": 5, "level": 5, "classif": 5, "basi": 5, "shallow": 5, "fusion": 5, "end": 5, "e": [5, 6], "g": 5, "la": 5, "rnnt": 5, "transform": [5, 6], "come": 5, "right": 5, "interpret": 5, "belong": 5, "case": 5, "circumst": 5, "coordin": 5, "assign": 6, "illustr": 6, "aishell4": 6, "constrain": 6, "sourc": 6, "addition": 6, "corpu": 6, "soon": 6, "simpl": 6, "voic": 6, "activ": 6, "detect": 6, "vad": 6, "concaten": 6, "minimum": 6, "permut": 6, "charact": 6, "error": 6, "rate": 6, "calcul": 6, "step": 6, "firstli": 6, "refer": 6, "hypothesi": 6, "chronolog": 6, "order": 6, "secondli": 6, "cer": 6, "repeat": 6, "possibl": 6, "lowest": 6, "tthe": 6, "insert": 6, "Ins": 6, "substitut": 6, "delet": 6, "del": 6, "output": 6, "text": 6, "frac": 6, "mathcal": 6, "n_": 6, "100": 6, "where": 6, "usag": 6, "third": 6, "hug": 6, "face": 6, "list": 6, "clearli": 6, "privat": 6, "manual": 6, "simul": 6, "thei": 6, "mandatori": 6, "clear": 6, "scheme": 6, "delight": 7, "introduct": 7, "contact": 7}, "objects": {}, "objtypes": {}, "objnames": {}, "titleterms": {"baselin": 0, "overview": [0, 2], "quick": 0, "start": 0, "result": 0, "contact": 1, "dataset": 2, "train": [2, 6], "data": 2, "detail": 2, "alimeet": 2, "corpu": 2, "get": 2, "introduct": 3, "call": 3, "particip": 3, "timelin": 3, "aoe": 3, "time": 3, "guidelin": 3, "organ": 4, "rule": 5, "track": 6, "evalu": 6, "speaker": 6, "attribut": 6, "asr": 6, "metric": 6, "sub": 6, "arrang": 6, "i": 6, "fix": 6, "condit": 6, "ii": 6, "open": 6, "asru": 7, "2023": 7, "multi": 7, "channel": 7, "parti": 7, "meet": 7, "transcript": 7, "challeng": 7, "2": 7, "0": 7, "m2met2": 7, "content": 7}, "envversion": {"sphinx.domains.c": 2, "sphinx.domains.changeset": 1, "sphinx.domains.citation": 1, "sphinx.domains.cpp": 8, "sphinx.domains.index": 1, "sphinx.domains.javascript": 2, "sphinx.domains.math": 2, "sphinx.domains.python": 3, "sphinx.domains.rst": 2, "sphinx.domains.std": 2, "sphinx": 57}, "alltitles": {"Baseline": [[0, "baseline"]], "Overview": [[0, "overview"]], "Quick start": [[0, "quick-start"]], "Baseline results": [[0, "baseline-results"]], "Contact": [[1, "contact"]], "Datasets": [[2, "datasets"]], "Overview of training data": [[2, "overview-of-training-data"]], "Detail of AliMeeting corpus": [[2, "detail-of-alimeeting-corpus"]], "Get the data": [[2, "get-the-data"]], "Introduction": [[3, "introduction"]], "Call for participation": [[3, "call-for-participation"]], "Timeline(AOE Time)": [[3, "timeline-aoe-time"]], "Guidelines": [[3, "guidelines"]], "Organizers": [[4, "organizers"]], "Rules": [[5, "rules"]], "Track & Evaluation": [[6, "track-evaluation"]], "Speaker-Attributed ASR": [[6, "speaker-attributed-asr"]], "Evaluation metric": [[6, "evaluation-metric"]], "Sub-track arrangement": [[6, "sub-track-arrangement"]], "Sub-track I (Fixed Training Condition):": [[6, "sub-track-i-fixed-training-condition"]], "Sub-track II (Open Training Condition):": [[6, "sub-track-ii-open-training-condition"]], "ASRU 2023 MULTI-CHANNEL MULTI-PARTY MEETING TRANSCRIPTION CHALLENGE 2.0 (M2MeT2.0)": [[7, "asru-2023-multi-channel-multi-party-meeting-transcription-challenge-2-0-m2met2-0"]], "Contents:": [[7, null]]}, "indexentries": {}}) |
|---|
copy from docs_m2met2/_build/html/_sources/index.rst.txt
copy to docs/m2met2/index.rst
| File was copied from docs_m2met2/_build/html/_sources/index.rst.txt |
| | |
|---|
| | | ./Rules |
|---|
| | | ./Organizers |
|---|
| | | ./Contact |
|---|
| | | |
|---|
| | | Indices and tables |
|---|
| | | ================== |
|---|
| | | |
|---|
| | | * :ref:`genindex` |
|---|
| | | * :ref:`modindex` |
|---|
| | | * :ref:`search` |
|---|
| File was renamed from docs_m2met2_cn/_build/html/_sources/index.rst.txt |
| | |
|---|
| | | ./è§å |
|---|
| | | ./ç»å§ä¼ |
|---|
| | | ./èç³»æ¹å¼ |
|---|
| | | |
|---|
| | | Indices and tables |
|---|
| | | ================== |
|---|
| | | |
|---|
| | | * :ref:`genindex` |
|---|
| | | * :ref:`modindex` |
|---|
| | | * :ref:`search` |
|---|
| File was renamed from docs_m2met2_cn/_build/html/_sources/Êý¾Ý¼¯.md.txt |
| | |
|---|
| | | å¨éå®æ°æ®éæ¡ä»¶ä¸ï¼è®ç»æ°æ®éä»
éäºä¸ä¸ªå
¬å¼çè¯æåºï¼å³AliMeetingãAISHELL-4åCN-Celebã为äºè¯ä¼°åèµè
æ交ç模åçæ§è½ï¼æ们å°åå¸ä¸ä¸ªæ°çæµè¯éï¼Test-2023ï¼ç¨äºæååæåãä¸é¢æ们å°è¯¦ç»æè¿°AliMeetingæ°æ®éåTest-2023æµè¯éã |
|---|
| | | |
|---|
| | | ## Alimeetingæ°æ®éä»ç» |
|---|
| | | AliMeetingæ»å
±å
å«118.75å°æ¶çè¯é³æ°æ®ï¼å
æ¬104.75å°æ¶çè®ç»éï¼Trainï¼ã4å°æ¶çéªè¯éï¼Evalï¼å10å°æ¶çæµè¯éï¼Testï¼ãTrainéåEvaléåå«å
å«212åºå8åºä¼è®®ï¼å
¶ä¸æ¯åºä¼è®®ç±å¤ä¸ªè¯´è¯äººè¿è¡15å°30åéç讨论ãTrainåEvaléä¸åä¸ä¼è®®çæ»äººæ°åå«ä¸º456人å25人ï¼å¹¶ä¸åä¼çç·å¥³æ¯ä¾äººæ°åè¡¡ã |
|---|
| | | AliMeetingæ»å
±å
å«118.75å°æ¶çè¯é³æ°æ®ï¼å
æ¬104.75å°æ¶çè®ç»éï¼Trainï¼ã4å°æ¶çéªè¯éï¼Evalï¼å10å°æ¶çæµè¯éï¼Testï¼ãTrainéï¼EvaléåTestéåå«å
å«212åºå8åºä¼è®®ï¼å
¶ä¸æ¯åºä¼è®®ç±å¤ä¸ªè¯´è¯äººè¿è¡15å°30åéç讨论ãTrainï¼EvalåTestéä¸åä¸ä¼è®®çæ»äººæ°åå«ä¸º456人å25人ï¼å¹¶ä¸åä¼çç·å¥³æ¯ä¾äººæ°åè¡¡ã |
|---|
| | | |
|---|
| | | 该æ°æ®éæ¶éäº13个ä¸åçä¼è®®å®¤ï¼æç
§å¤§å°è§æ ¼å为å°åãä¸åå大åä¸ç§ï¼æ¿é´é¢ç§¯ä»8å°55å¹³æ¹ç±³ä¸çãä¸åæ¿é´å
·æä¸åçå¸å±å声å¦ç¹æ§ï¼æ¯ä¸ªæ¿é´ç详ç»åæ°ä¹å°åéç»åä¸è
ãä¼è®®åºå°çå¢ä½ææç±»åå
æ¬æ°´æ³¥ãç»ççãä¼è®®åºå°ç家å
·å
æ¬æ²åãçµè§ãé»æ¿ãé£æã空è°ãæ¤ç©çãå¨å½å¶è¿ç¨ä¸ï¼éº¦å
é£éµåæ¾ç½®äºæ¡ä¸ï¼å¤ä¸ªè¯´è¯äººå´åå¨æ¡è¾¹è¿è¡èªç¶å¯¹è¯ã麦å
é£éµå离说è¯äººè·ç¦»çº¦0.3å°5.0ç±³ä¹é´ãææ说è¯äººçæ¯è¯åæ¯æ±è¯ï¼å¹¶ä¸è¯´çé½æ¯æ®éè¯ï¼æ²¡ææµéçå£é³ãå¨ä¼è®®å½å¶æé´å¯è½ä¼äº§çåç§å®¤å
çåªé³ï¼å
æ¬é®ç声ãå¼é¨/å
³é¨å£°ãé£æ声ãæ°æ³¡å£°çãææ说è¯äººå¨ä¼è®®çå½å¶æé´åä¿æç¸åä½ç½®ï¼ä¸åçèµ°å¨ãè®ç»éåéªè¯éç说è¯äººæ²¡æéå¤ãå¾1å±ç¤ºäºä¸ä¸ªä¼è®®å®¤çå¸å±ä»¥å麦å
é£çææç»æã |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| | | æ¯åºä¼è®®ç说è¯äººæ°éä»2å°4人ä¸çãåæ¶ä¸ºäºè¦çåç§å
容çä¼è®®åºæ¯ï¼æ们éæ©äºå¤ç§ä¼è®®ä¸»é¢ï¼å
æ¬å»çãæè²ãåä¸ãç»ç»ç®¡çãå·¥ä¸ç产çä¸åå
容çä¾ä¼ãTrainéï¼EvaléåTestéçå¹³åè¯é³éå çåå«ä¸º42.27\%å34.76\%ãAliMeeting Trainéï¼EvaléåTestéç详ç»ä¿¡æ¯è§è¡¨1ã表2æ¾ç¤ºäºTrainé,EvaléåTestéä¸ä¸ååè¨è
人æ°ä¼è®®çè¯é³éå çåä¼è®®æ°éã |
|---|
| | | æ¯åºä¼è®®ç说è¯äººæ°éä»2å°4人ä¸çãåæ¶ä¸ºäºè¦çåç§å
容çä¼è®®åºæ¯ï¼æ们éæ©äºå¤ç§ä¼è®®ä¸»é¢ï¼å
æ¬å»çãæè²ãåä¸ãç»ç»ç®¡çãå·¥ä¸ç产çä¸åå
容çä¾ä¼ãTrainéï¼EvaléåTestéçå¹³åè¯é³éå çåå«ä¸º42.27\%ï¼34.76\%å42.8\%ãAliMeeting Trainéï¼EvaléåTestéç详ç»ä¿¡æ¯è§è¡¨1ã表2æ¾ç¤ºäºTrainé,EvaléåTestéä¸ä¸ååè¨è
人æ°ä¼è®®çè¯é³éå çåä¼è®®æ°éã |
|---|
| | | |
|---|
| | |  |
|---|
| | | Test-2023æµè¯éç±20åºä¼è®®ç»æï¼è¿äºä¼è®®æ¯å¨ä¸AliMeetingæ°æ®éç¸åç声å¦ç¯å¢ä¸å½å¶çãTest-2023æµè¯éä¸çæ¯ä¸ªä¼è®®ç¯èç±2å°4个åä¸è
ç»æ并ä¸ä¸AliMeetingæµè¯éçé
ç½®ç¸ä¼¼ã |
|---|
| File was renamed from docs_m2met2_cn/_build/html/_sources/¼ò½é.md.txt |
| | |
|---|
| | | |
|---|
| | | ## æ¶é´å®æ(AOEæ¶é´) |
|---|
| | | |
|---|
| | | - $ 2023.5.5: $ åèµè
注åæªæ¢ |
|---|
| | | - $ 2023.4.29: $ å¼æ¾æ³¨å |
|---|
| | | - $ 2023.5.8: $ åºçº¿åå¸ |
|---|
| | | - $ 2023.5.15: $ 注åæªæ¢ |
|---|
| | | - $ 2023.6.9: $ æµè¯éæ°æ®åå¸ |
|---|
| | | - $ 2023.6.13: $ æç»ç»ææ交æªæ¢ |
|---|
| | | - $ 2023.6.19: $ è¯ä¼°ç»æåæååå¸ |
|---|
| | | - $ 2023.7.3: $ 论ææ交æªæ¢ |
|---|
| | | - $ 2023.7.10: $ æç»ç论ææ交æªæ¢ |
|---|
| | | - $ 2023.12.12: $ ASRU Workshop |
|---|
| | | - $ 2023.12.12: $ ASRU Workshop & challenge session |
|---|
| | | |
|---|
| | | ## ç«èµæ¥å |
|---|
| | | |
|---|
| | | æ¥èªå¦æ¯çåå·¥ä¸ççææååèµè
ååºå¨2023å¹´5æ5æ¥åä¹åå¡«åä¸æ¹çè°·æ表åï¼ |
|---|
| | | æ¥èªå¦æ¯çåå·¥ä¸ççææååèµè
ååºå¨2023å¹´5æ15æ¥åä¹åå¡«åä¸æ¹çè°·æ表åï¼ |
|---|
| | | |
|---|
| | | [M2MET2.0æ¥å](https://docs.google.com/forms/d/e/1FAIpQLSf77T9vAl7Ym-u5g8gXu18SBofoWRaFShBo26Ym0-HDxHW9PQ/viewform?usp=sf_link) |
|---|
| | | |
|---|
| | | 主åæ¹å°å¨3个工ä½æ¥å
éè¿çµåé®ä»¶éç¥ç¬¦åæ¡ä»¶çåèµå¢éï¼å¢éå¿
é¡»éµå®å°å¨ææç½ç«ä¸åå¸çææè§åãå¨æååå¸ä¹åï¼æ¯ä¸ªåèµè
å¿
é¡»æ交ä¸ä»½ç³»ç»æè¿°æ件ï¼è¯¦ç»è¯´æ使ç¨çæ¹æ³å模åã主åæ¹å°éæ©åä¸å纳å
¥ASRU2023论æéã |
|---|
| File was renamed from docs_m2met2_cn/_build/html/_sources/¹æÔò.md.txt |
| | |
|---|
| | | - å
许å¨åå§è®ç»æ°æ®éä¸è¿è¡æ°æ®å¢å¼ºï¼å
æ¬ä½ä¸éäºæ·»å åªå£°ææ··åãé度æ°å¨åé³è°ååã |
|---|
| | | |
|---|
| | | - å
许åèµè
使ç¨Evaléè¿è¡æ¨¡åè®ç»ï¼ä½Testéä»
è½ç¨äºè°åå模åéæ©ï¼ä¸¥ç¦ä»¥ä»»ä½å½¢å¼ä½¿ç¨Test-2023æ°æ®éï¼å
æ¬ä½ä¸éäºä½¿ç¨æµè¯æ°æ®éå¾®è°æè®ç»æ¨¡åã |
|---|
| | | |
|---|
| | | - å
许å¤ç³»ç»èåï¼ä½ä¸é¼å±ä½¿ç¨å
·æç¸åç»æä»
åæ°ä¸åçåç³»ç»èåã |
|---|
| | | |
|---|
| | | - å¦æ两个系ç»çæµè¯cpCERç¸åï¼å计ç®å¤æ度è¾ä½çç³»ç»å°è¢«è®¤å®ä¸ºæ´ä¼ã |
|---|
| | | |
|---|
| File was renamed from docs_m2met2_cn/_build/html/_sources/ÈüµÀÉèÖÃÓëÆÀ¹À.md.txt |
| | |
|---|
| | | # èµé设置ä¸è¯ä¼° |
|---|
| | | ## 说è¯äººç¸å
³çè¯é³è¯å« (主èµé) |
|---|
| | | 说è¯äººç¸å
³çASRä»»å¡éè¦ä»éå çè¯é³ä¸è¯å«æ¯ä¸ªè¯´è¯äººçè¯é³ï¼å¹¶ä¸ºè¯å«å
容åé
ä¸ä¸ªè¯´è¯äººæ ç¾ãå¾2å±ç¤ºäºè¯´è¯äººç¸å
³è¯é³è¯å«ä»»å¡åå¤è¯´è¯äººè¯é³è¯å«ä»»å¡ç主è¦åºå«ãå¨æ¬æ¬¡ç«èµä¸AliMeetingãAishell4åCn-Celebæ°æ®éå¯ä½ä¸ºåéæ°æ®æºãå¨M2MeTææèµä¸ä½¿ç¨çAliMeetingæ°æ®éå
å«è®ç»ãè¯ä¼°åæµè¯éï¼å¨M2MET2.0å¯ä»¥å¨è®ç»åè¯ä¼°ä¸ä½¿ç¨ãæ¤å¤ï¼ä¸ä¸ªå
å«çº¦10å°æ¶ä¼è®®æ°æ®çæ°çTest-2023éå°æ ¹æ®èµç¨å®æåå¸å¹¶ç¨äºææèµçè¯ååæåãå¼å¾æ³¨æçæ¯ï¼ç»ç»è
å°ä¸æä¾è³æºçè¿åºé³é¢ã转å½ä»¥åçå®æ¶é´æ³ã主åæ¹å°ä¸åæä¾æ¯ä¸ªè¯´è¯äººççå®æ¶é´æ³ï¼èæ¯å¨Test-2023éä¸æä¾å
å«å¤ä¸ªè¯´è¯äººçç段ãè¿äºç段å¯ä»¥éè¿ä¸ä¸ªç®åçvad模åè·å¾ã |
|---|
| | | ## 说è¯äººç¸å
³çè¯é³è¯å« |
|---|
| | | 说è¯äººç¸å
³çASRä»»å¡éè¦ä»éå çè¯é³ä¸è¯å«æ¯ä¸ªè¯´è¯äººçè¯é³ï¼å¹¶ä¸ºè¯å«å
容åé
ä¸ä¸ªè¯´è¯äººæ ç¾ãå¾2å±ç¤ºäºè¯´è¯äººç¸å
³è¯é³è¯å«ä»»å¡åå¤è¯´è¯äººè¯é³è¯å«ä»»å¡ç主è¦åºå«ãå¨æ¬æ¬¡ç«èµä¸AliMeetingãAishell4åCn-Celebæ°æ®éå¯ä½ä¸ºåéæ°æ®æºãå¨M2MeTææèµä¸ä½¿ç¨çAliMeetingæ°æ®éå
å«è®ç»ãè¯ä¼°åæµè¯éï¼å¨M2MET2.0å¯ä»¥å¨è®ç»åè¯ä¼°ä¸ä½¿ç¨ãæ¤å¤ï¼ä¸ä¸ªå
å«çº¦10å°æ¶ä¼è®®æ°æ®çæ°çTest-2023éå°æ ¹æ®èµç¨å®æåå¸å¹¶ç¨äºææèµçè¯ååæåãå¼å¾æ³¨æçæ¯ï¼å¯¹äºTest-2023æµè¯éï¼ä¸»åæ¹å°ä¸åæä¾è³æºçè¿åºé³é¢ã转å½ä»¥åçå®æ¶é´æ³ãèæ¯æä¾å¯ä»¥éè¿ä¸ä¸ªç®åçVAD模åå¾å°çå
å«å¤ä¸ªè¯´è¯äººçç段ã |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| | |
|---|
| | | å
¶ä¸ $\mathcal N_{\text{Ins}}$ , $\mathcal N_{\text{Sub}}$ , $\mathcal N_{\text{Del}}$ æ¯ä¸ç§é误çå符æ°, $\mathcal N_{\text{Total}}$ æ¯å符æ»æ°. |
|---|
| | | ## åèµé设置 |
|---|
| | | ### åèµéä¸ (éå®è®ç»æ°æ®): |
|---|
| | | åèµè
å¨ç³»ç»æ建è¿ç¨ä¸ä»
è½ä½¿ç¨AliMeetingãAISHELL-4åCN Celebï¼ä¸¥ç¦ä½¿ç¨é¢å¤æ°æ®ãåèµè
å¯ä»¥ä»»ä½ç¬¬ä¸æ¹å¼æºçé¢è®ç»æ¨¡åï¼å¦[Hugging Face](https://huggingface.co/models)以å[ModelScope](https://www.modelscope.cn/models)ä¸æä¾ç模åãåèµè
éè¦å¨æç»çç³»ç»æè¿°ææ¡£ä¸è¯¦ç»ååºä½¿ç¨çé¢è®ç»æ¨¡åå称以åé¾æ¥ã |
|---|
| | | åèµè
å¨ç³»ç»æ建è¿ç¨ä¸ä»
è½ä½¿ç¨AliMeetingãAISHELL-4åCN-Celebï¼ä¸¥ç¦ä½¿ç¨é¢å¤æ°æ®ãåèµè
å¯ä»¥ä»»ä½ç¬¬ä¸æ¹å¼æºçé¢è®ç»æ¨¡åï¼å¦[Hugging Face](https://huggingface.co/models)以å[ModelScope](https://www.modelscope.cn/models)ä¸æä¾ç模åãåèµè
éè¦å¨æç»çç³»ç»æè¿°ææ¡£ä¸è¯¦ç»ååºä½¿ç¨çé¢è®ç»æ¨¡åå称以åé¾æ¥ã |
|---|
| | | ### åèµéäº (å¼æ¾è®ç»æ°æ®): |
|---|
| | | é¤äºéå®æ°æ®å¤ï¼åä¸è
å¯ä»¥ä½¿ç¨ä»»ä½å
¬å¼å¯ç¨ãç§äººå½å¶å模æ仿ççæ°æ®éãä½æ¯ï¼åä¸è
å¿
é¡»æ¸
æ¥å°ååºä½¿ç¨çæ°æ®ãåæ ·ï¼åèµè
ä¹å¯ä»¥ä½¿ç¨ä»»ä½ç¬¬ä¸æ¹å¼æºçé¢è®ç»æ¨¡åï¼ä½å¿
é¡»å¨æåçç³»ç»æè¿°æ件ä¸æç¡®çååºæ使ç¨çæ°æ®å模åé¾æ¥ï¼å¦æ使ç¨æ¨¡æ仿çæ°æ®ï¼è¯·è¯¦ç»æè¿°æ°æ®æ¨¡æçæ¹æ¡ã |
|---|
| File was renamed from docs_m2met2_cn/_build/html/genindex.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html">èµé设置ä¸è¯ä¼°</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å« (主èµé)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å«</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id3">è¯ä¼°æ¹æ³</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id4">åèµé设置</a></li> |
|---|
| | | </ul> |
|---|
| File was renamed from docs_m2met2_cn/_build/html/index.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html">èµé设置ä¸è¯ä¼°</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å« (主èµé)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å«</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id3">è¯ä¼°æ¹æ³</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id4">åèµé设置</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">èç³»æ¹å¼</a></li> |
|---|
| | | </ul> |
|---|
| | | </div> |
|---|
| | | </section> |
|---|
| | | <section id="indices-and-tables"> |
|---|
| | | <h1>Indices and tables<a class="headerlink" href="#indices-and-tables" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h1> |
|---|
| | | <ul class="simple"> |
|---|
| | | <li><p><a class="reference internal" href="genindex.html"><span class="std std-ref">ç´¢å¼</span></a></p></li> |
|---|
| | | <li><p><a class="reference internal" href="py-modindex.html"><span class="std std-ref">模åç´¢å¼</span></a></p></li> |
|---|
| | | <li><p><a class="reference internal" href="search.html"><span class="std std-ref">æ索页é¢</span></a></p></li> |
|---|
| | | </ul> |
|---|
| | | </section> |
|---|
| | | |
|---|
| | | |
|---|
| File was renamed from docs_m2met2_cn/_build/html/search.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html">èµé设置ä¸è¯ä¼°</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å« (主èµé)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å«</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id3">è¯ä¼°æ¹æ³</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id4">åèµé设置</a></li> |
|---|
| | | </ul> |
|---|
| New file |
| | |
|---|
| | | Search.setIndex({"docnames": ["index", "\u57fa\u7ebf", "\u6570\u636e\u96c6", "\u7b80\u4ecb", "\u7ec4\u59d4\u4f1a", "\u8054\u7cfb\u65b9\u5f0f", "\u89c4\u5219", "\u8d5b\u9053\u8bbe\u7f6e\u4e0e\u8bc4\u4f30"], "filenames": ["index.rst", "\u57fa\u7ebf.md", "\u6570\u636e\u96c6.md", "\u7b80\u4ecb.md", "\u7ec4\u59d4\u4f1a.md", "\u8054\u7cfb\u65b9\u5f0f.md", "\u89c4\u5219.md", "\u8d5b\u9053\u8bbe\u7f6e\u4e0e\u8bc4\u4f30.md"], "titles": ["ASRU 2023 \u591a\u901a\u9053\u591a\u65b9\u4f1a\u8bae\u8f6c\u5f55\u6311\u6218 2.0", "\u57fa\u7ebf", "\u6570\u636e\u96c6", "\u7b80\u4ecb", "\u7ec4\u59d4\u4f1a", "\u8054\u7cfb\u65b9\u5f0f", "\u7ade\u8d5b\u89c4\u5219", "\u8d5b\u9053\u8bbe\u7f6e\u4e0e\u8bc4\u4f30"], "terms": {"m2met": [0, 3, 5, 7], "asru2023": [0, 3], "m2met2": [0, 3, 5, 7], "funasr": 1, "sa": 1, "asr": [1, 3, 7], "speakerencod": 1, "modelscop": [1, 7], "todo": 1, "fill": 1, "with": 1, "the": 1, "readm": 1, "md": 1, "of": 1, "baselin": [1, 2], "aishel": [2, 7], "cn": [2, 4, 7], "celeb": [2, 7], "test": [2, 6, 7], "2023": [2, 3, 6, 7], "118": 2, "75": 2, "104": 2, "train": 2, "eval": [2, 6], "10": [2, 3, 7], "212": 2, "15": [2, 3], "30": 2, "456": 2, "25": 2, "13": [2, 3], "55": 2, "42": 2, "27": 2, "34": 2, "76": 2, "20": 2, "textgrid": 2, "id": 2, "openslr": 2, "automat": 3, "speech": 3, "recognit": 3, "speaker": 3, "diariz": 3, "rich": 3, "transcript": 3, "evalu": 3, "chime": 3, "comput": 3, "hear": 3, "in": 3, "multisourc": 3, "environ": 3, "misp": 3, "multimod": 3, "inform": 3, "base": 3, "process": 3, "multi": 3, "channel": 3, "parti": 3, "meet": 3, "assp2022": 3, "29": 3, "19": 3, "12": 3, "asru": 3, "workshop": 3, "challeng": 3, "session": 3, "lxie": 4, "nwpu": 4, "edu": 4, "kong": 4, "aik": 4, "lee": 4, "star": 4, "kongaik": 4, "ieee": 4, "org": 4, "zhiji": 4, "yzj": 4, "alibaba": 4, "inc": 4, "com": [4, 5], "sli": 4, "zsl": 4, "yanminqian": 4, "sjtu": 4, "zhuc": 4, "microsoft": 4, "wujian": 4, "ceo": 4, "buhui": 4, "aishelldata": 4, "alimeet": [5, 7], "gmail": 5, "cpcer": [6, 7], "las": 6, "rnnt": 6, "transform": 6, "aishell4": 7, "vad": 7, "cer": 7, "ins": 7, "sub": 7, "del": 7, "text": 7, "frac": 7, "mathcal": 7, "n_": 7, "total": 7, "time": 7, "100": 7, "hug": 7, "face": 7}, "objects": {}, "objtypes": {}, "objnames": {}, "titleterms": {"asru": 0, "2023": 0, "alimeet": 2, "aoe": 3}, "envversion": {"sphinx.domains.c": 2, "sphinx.domains.changeset": 1, "sphinx.domains.citation": 1, "sphinx.domains.cpp": 8, "sphinx.domains.index": 1, "sphinx.domains.javascript": 2, "sphinx.domains.math": 2, "sphinx.domains.python": 3, "sphinx.domains.rst": 2, "sphinx.domains.std": 2, "sphinx": 57}, "alltitles": {"ASRU 2023 \u591a\u901a\u9053\u591a\u65b9\u4f1a\u8bae\u8f6c\u5f55\u6311\u6218 2.0": [[0, "asru-2023-2-0"]], "\u76ee\u5f55:": [[0, null]], "\u57fa\u7ebf": [[1, "id1"]], "\u57fa\u7ebf\u6982\u8ff0": [[1, "id2"]], "\u5feb\u901f\u5f00\u59cb": [[1, "id3"]], "\u57fa\u7ebf\u7ed3\u679c": [[1, "id4"]], "\u6570\u636e\u96c6": [[2, "id1"]], "\u6570\u636e\u96c6\u6982\u8ff0": [[2, "id2"]], "Alimeeting\u6570\u636e\u96c6\u4ecb\u7ecd": [[2, "alimeeting"]], "\u83b7\u53d6\u6570\u636e": [[2, "id3"]], "\u7b80\u4ecb": [[3, "id1"]], "\u7ade\u8d5b\u4ecb\u7ecd": [[3, "id2"]], "\u65f6\u95f4\u5b89\u6392(AOE\u65f6\u95f4)": [[3, "aoe"]], "\u7ade\u8d5b\u62a5\u540d": [[3, "id3"]], "\u7ec4\u59d4\u4f1a": [[4, "id1"]], "\u8054\u7cfb\u65b9\u5f0f": [[5, "id1"]], "\u7ade\u8d5b\u89c4\u5219": [[6, "id1"]], "\u8d5b\u9053\u8bbe\u7f6e\u4e0e\u8bc4\u4f30": [[7, "id1"]], "\u8bf4\u8bdd\u4eba\u76f8\u5173\u7684\u8bed\u97f3\u8bc6\u522b": [[7, "id2"]], "\u8bc4\u4f30\u65b9\u6cd5": [[7, "id3"]], "\u5b50\u8d5b\u9053\u8bbe\u7f6e": [[7, "id4"]], "\u5b50\u8d5b\u9053\u4e00 (\u9650\u5b9a\u8bad\u7ec3\u6570\u636e):": [[7, "id5"]], "\u5b50\u8d5b\u9053\u4e8c (\u5f00\u653e\u8bad\u7ec3\u6570\u636e):": [[7, "id6"]]}, "indexentries": {}}) |
|---|
| File was renamed from docs_m2met2_cn/_build/html/»ùÏß.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html">èµé设置ä¸è¯ä¼°</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å« (主èµé)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å«</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id3">è¯ä¼°æ¹æ³</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id4">åèµé设置</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%A7%84%E5%88%99.html">ç«èµè§å</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E7%BB%84%E5%A7%94%E4%BC%9A.html">ç»å§ä¼</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">Contact</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">èç³»æ¹å¼</a></li> |
|---|
| | | </ul> |
|---|
| | | |
|---|
| | | |
|---|
| File was renamed from docs_m2met2_cn/_build/html/Êý¾Ý¼¯.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html">èµé设置ä¸è¯ä¼°</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å« (主èµé)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å«</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id3">è¯ä¼°æ¹æ³</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id4">åèµé设置</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%A7%84%E5%88%99.html">ç«èµè§å</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E7%BB%84%E5%A7%94%E4%BC%9A.html">ç»å§ä¼</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">Contact</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">èç³»æ¹å¼</a></li> |
|---|
| | | </ul> |
|---|
| | | |
|---|
| | | |
|---|
| | |
|---|
| | | </section> |
|---|
| | | <section id="alimeeting"> |
|---|
| | | <h2>Alimeetingæ°æ®éä»ç»<a class="headerlink" href="#alimeeting" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h2> |
|---|
| | | <p>AliMeetingæ»å
±å
å«118.75å°æ¶çè¯é³æ°æ®ï¼å
æ¬104.75å°æ¶çè®ç»éï¼Trainï¼ã4å°æ¶çéªè¯éï¼Evalï¼å10å°æ¶çæµè¯éï¼Testï¼ãTrainéåEvaléåå«å
å«212åºå8åºä¼è®®ï¼å
¶ä¸æ¯åºä¼è®®ç±å¤ä¸ªè¯´è¯äººè¿è¡15å°30åéç讨论ãTrainåEvaléä¸åä¸ä¼è®®çæ»äººæ°åå«ä¸º456人å25人ï¼å¹¶ä¸åä¼çç·å¥³æ¯ä¾äººæ°åè¡¡ã</p> |
|---|
| | | <p>AliMeetingæ»å
±å
å«118.75å°æ¶çè¯é³æ°æ®ï¼å
æ¬104.75å°æ¶çè®ç»éï¼Trainï¼ã4å°æ¶çéªè¯éï¼Evalï¼å10å°æ¶çæµè¯éï¼Testï¼ãTrainéï¼EvaléåTestéåå«å
å«212åºå8åºä¼è®®ï¼å
¶ä¸æ¯åºä¼è®®ç±å¤ä¸ªè¯´è¯äººè¿è¡15å°30åéç讨论ãTrainï¼EvalåTestéä¸åä¸ä¼è®®çæ»äººæ°åå«ä¸º456人å25人ï¼å¹¶ä¸åä¼çç·å¥³æ¯ä¾äººæ°åè¡¡ã</p> |
|---|
| | | <p>该æ°æ®éæ¶éäº13个ä¸åçä¼è®®å®¤ï¼æç
§å¤§å°è§æ ¼å为å°åãä¸åå大åä¸ç§ï¼æ¿é´é¢ç§¯ä»8å°55å¹³æ¹ç±³ä¸çãä¸åæ¿é´å
·æä¸åçå¸å±å声å¦ç¹æ§ï¼æ¯ä¸ªæ¿é´ç详ç»åæ°ä¹å°åéç»åä¸è
ãä¼è®®åºå°çå¢ä½ææç±»åå
æ¬æ°´æ³¥ãç»ççãä¼è®®åºå°ç家å
·å
æ¬æ²åãçµè§ãé»æ¿ãé£æã空è°ãæ¤ç©çãå¨å½å¶è¿ç¨ä¸ï¼éº¦å
é£éµåæ¾ç½®äºæ¡ä¸ï¼å¤ä¸ªè¯´è¯äººå´åå¨æ¡è¾¹è¿è¡èªç¶å¯¹è¯ã麦å
é£éµå离说è¯äººè·ç¦»çº¦0.3å°5.0ç±³ä¹é´ãææ说è¯äººçæ¯è¯åæ¯æ±è¯ï¼å¹¶ä¸è¯´çé½æ¯æ®éè¯ï¼æ²¡ææµéçå£é³ãå¨ä¼è®®å½å¶æé´å¯è½ä¼äº§çåç§å®¤å
çåªé³ï¼å
æ¬é®ç声ãå¼é¨/å
³é¨å£°ãé£æ声ãæ°æ³¡å£°çãææ说è¯äººå¨ä¼è®®çå½å¶æé´åä¿æç¸åä½ç½®ï¼ä¸åçèµ°å¨ãè®ç»éåéªè¯éç说è¯äººæ²¡æéå¤ãå¾1å±ç¤ºäºä¸ä¸ªä¼è®®å®¤çå¸å±ä»¥å麦å
é£çææç»æã</p> |
|---|
| | | <p><img alt="meeting room" src="_images/meeting_room.png" /></p> |
|---|
| | | <p>æ¯åºä¼è®®ç说è¯äººæ°éä»2å°4人ä¸çãåæ¶ä¸ºäºè¦çåç§å
容çä¼è®®åºæ¯ï¼æ们éæ©äºå¤ç§ä¼è®®ä¸»é¢ï¼å
æ¬å»çãæè²ãåä¸ãç»ç»ç®¡çãå·¥ä¸ç产çä¸åå
容çä¾ä¼ãTrainéï¼EvaléåTestéçå¹³åè¯é³éå çåå«ä¸º42.27%å34.76%ãAliMeeting Trainéï¼EvaléåTestéç详ç»ä¿¡æ¯è§è¡¨1ã表2æ¾ç¤ºäºTrainé,EvaléåTestéä¸ä¸ååè¨è
人æ°ä¼è®®çè¯é³éå çåä¼è®®æ°éã</p> |
|---|
| | | <p>æ¯åºä¼è®®ç说è¯äººæ°éä»2å°4人ä¸çãåæ¶ä¸ºäºè¦çåç§å
容çä¼è®®åºæ¯ï¼æ们éæ©äºå¤ç§ä¼è®®ä¸»é¢ï¼å
æ¬å»çãæè²ãåä¸ãç»ç»ç®¡çãå·¥ä¸ç产çä¸åå
容çä¾ä¼ãTrainéï¼EvaléåTestéçå¹³åè¯é³éå çåå«ä¸º42.27%ï¼34.76%å42.8%ãAliMeeting Trainéï¼EvaléåTestéç详ç»ä¿¡æ¯è§è¡¨1ã表2æ¾ç¤ºäºTrainé,EvaléåTestéä¸ä¸ååè¨è
人æ°ä¼è®®çè¯é³éå çåä¼è®®æ°éã</p> |
|---|
| | | <p><img alt="dataset detail" src="_images/dataset_detail.png" /> |
|---|
| | | Test-2023æµè¯éç±20åºä¼è®®ç»æï¼è¿äºä¼è®®æ¯å¨ä¸AliMeetingæ°æ®éç¸åç声å¦ç¯å¢ä¸å½å¶çãTest-2023æµè¯éä¸çæ¯ä¸ªä¼è®®ç¯èç±2å°4个åä¸è
ç»æ并ä¸ä¸AliMeetingæµè¯éçé
ç½®ç¸ä¼¼ã</p> |
|---|
| | | <p>æ们è¿ä½¿ç¨è³æºéº¦å
é£è®°å½äºæ¯ä¸ªè¯´è¯äººçè¿åºé³é¢ä¿¡å·ï¼å¹¶ç¡®ä¿åªè½¬å½å¯¹åºè¯´è¯äººèªå·±çè¯é³ãéè¦æ³¨æçæ¯ï¼éº¦å
é£éµåè®°å½çè¿åºé³é¢åè³æºéº¦å
é£è®°å½çè¿åºé³é¢å¨æ¶é´ä¸æ¯åæ¥çãæ¯åºä¼è®®çææææ¬å以TextGridæ ¼å¼åå¨ï¼å
容å
æ¬ä¼è®®çæ¶é¿ã说è¯äººä¿¡æ¯ï¼è¯´è¯äººæ°éã说è¯äººIDãæ§å«çï¼ãæ¯ä¸ªè¯´è¯äººçç段æ»æ°ãæ¯ä¸ªç段çæ¶é´æ³å转å½å
容ã</p> |
|---|
| File was renamed from docs_m2met2_cn/_build/html/¼ò½é.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html">èµé设置ä¸è¯ä¼°</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å« (主èµé)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å«</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id3">è¯ä¼°æ¹æ³</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id4">åèµé设置</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%A7%84%E5%88%99.html">ç«èµè§å</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E7%BB%84%E5%A7%94%E4%BC%9A.html">ç»å§ä¼</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">Contact</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">èç³»æ¹å¼</a></li> |
|---|
| | | </ul> |
|---|
| | | |
|---|
| | | |
|---|
| | |
|---|
| | | <section id="aoe"> |
|---|
| | | <h2>æ¶é´å®æ(AOEæ¶é´)<a class="headerlink" href="#aoe" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h2> |
|---|
| | | <ul class="simple"> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.5.5: \)</span> åèµè
注åæªæ¢</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.4.29: \)</span> å¼æ¾æ³¨å</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.5.8: \)</span> åºçº¿åå¸</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.5.15: \)</span> 注åæªæ¢</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.6.9: \)</span> æµè¯éæ°æ®åå¸</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.6.13: \)</span> æç»ç»ææ交æªæ¢</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.6.19: \)</span> è¯ä¼°ç»æåæååå¸</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.7.3: \)</span> 论ææ交æªæ¢</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.7.10: \)</span> æç»ç论ææ交æªæ¢</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.12.12: \)</span> ASRU Workshop</p></li> |
|---|
| | | <li><p><span class="math notranslate nohighlight">\( 2023.12.12: \)</span> ASRU Workshop & challenge session</p></li> |
|---|
| | | </ul> |
|---|
| | | </section> |
|---|
| | | <section id="id3"> |
|---|
| | | <h2>ç«èµæ¥å<a class="headerlink" href="#id3" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h2> |
|---|
| | | <p>æ¥èªå¦æ¯çåå·¥ä¸ççææååèµè
ååºå¨2023å¹´5æ5æ¥åä¹åå¡«åä¸æ¹çè°·æ表åï¼</p> |
|---|
| | | <p>æ¥èªå¦æ¯çåå·¥ä¸ççææååèµè
ååºå¨2023å¹´5æ15æ¥åä¹åå¡«åä¸æ¹çè°·æ表åï¼</p> |
|---|
| | | <p><a class="reference external" href="https://docs.google.com/forms/d/e/1FAIpQLSf77T9vAl7Ym-u5g8gXu18SBofoWRaFShBo26Ym0-HDxHW9PQ/viewform?usp=sf_link">M2MET2.0æ¥å</a></p> |
|---|
| | | <p>主åæ¹å°å¨3个工ä½æ¥å
éè¿çµåé®ä»¶éç¥ç¬¦åæ¡ä»¶çåèµå¢éï¼å¢éå¿
é¡»éµå®å°å¨ææç½ç«ä¸åå¸çææè§åãå¨æååå¸ä¹åï¼æ¯ä¸ªåèµè
å¿
é¡»æ交ä¸ä»½ç³»ç»æè¿°æ件ï¼è¯¦ç»è¯´æ使ç¨çæ¹æ³å模åã主åæ¹å°éæ©åä¸å纳å
¥ASRU2023论æéã</p> |
|---|
| | | </section> |
|---|
| | | </section> |
|---|
| File was renamed from docs_m2met2_cn/_build/html/×éί»á.html |
| | |
|---|
| | | <script src="_static/translations.js"></script> |
|---|
| | | <link rel="index" title="ç´¢å¼" href="genindex.html" /> |
|---|
| | | <link rel="search" title="æç´¢" href="search.html" /> |
|---|
| | | <link rel="next" title="Contact" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html" /> |
|---|
| | | <link rel="next" title="èç³»æ¹å¼" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html" /> |
|---|
| | | <link rel="prev" title="ç«èµè§å" href="%E8%A7%84%E5%88%99.html" /> |
|---|
| | | |
|---|
| | | |
|---|
| | |
|---|
| | | <a href="genindex.html" title="æ»ç´¢å¼" |
|---|
| | | accesskey="I">ç´¢å¼</a></li> |
|---|
| | | <li class="right" > |
|---|
| | | <a href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html" title="Contact" |
|---|
| | | <a href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html" title="èç³»æ¹å¼" |
|---|
| | | accesskey="N">ä¸ä¸é¡µ</a> |</li> |
|---|
| | | <li class="right" > |
|---|
| | | <a href="%E8%A7%84%E5%88%99.html" title="ç«èµè§å" |
|---|
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html">èµé设置ä¸è¯ä¼°</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å« (主èµé)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å«</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id3">è¯ä¼°æ¹æ³</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id4">åèµé设置</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%A7%84%E5%88%99.html">ç«èµè§å</a></li> |
|---|
| | | <li class="toctree-l1 current"><a class="current reference internal" href="#">ç»å§ä¼</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">Contact</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">èç³»æ¹å¼</a></li> |
|---|
| | | </ul> |
|---|
| | | |
|---|
| | | |
|---|
| | |
|---|
| | | </div> |
|---|
| | | |
|---|
| | | <div class="pull-right"> |
|---|
| | | <a class="btn btn-default" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html" title="ä¸ä¸ç« (use the right arrow)">Contact</a> |
|---|
| | | <a class="btn btn-default" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html" title="ä¸ä¸ç« (use the right arrow)">èç³»æ¹å¼</a> |
|---|
| | | </div> |
|---|
| | | </div> |
|---|
| | | <div class="clearer"></div> |
|---|
| | |
|---|
| | | <a href="genindex.html" title="æ»ç´¢å¼" |
|---|
| | | >ç´¢å¼</a></li> |
|---|
| | | <li class="right" > |
|---|
| | | <a href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html" title="Contact" |
|---|
| | | <a href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html" title="èç³»æ¹å¼" |
|---|
| | | >ä¸ä¸é¡µ</a> |</li> |
|---|
| | | <li class="right" > |
|---|
| | | <a href="%E8%A7%84%E5%88%99.html" title="ç«èµè§å" |
|---|
| File was renamed from docs_m2met2_cn/_build/html/ÁªÏµ·½Ê½.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html">èµé设置ä¸è¯ä¼°</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å« (主èµé)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å«</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id3">è¯ä¼°æ¹æ³</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id4">åèµé设置</a></li> |
|---|
| | | </ul> |
|---|
| File was renamed from docs_m2met2_cn/_build/html/¹æÔò.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html">èµé设置ä¸è¯ä¼°</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å« (主èµé)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id2">说è¯äººç¸å
³çè¯é³è¯å«</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id3">è¯ä¼°æ¹æ³</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="%E8%B5%9B%E9%81%93%E8%AE%BE%E7%BD%AE%E4%B8%8E%E8%AF%84%E4%BC%B0.html#id4">åèµé设置</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1 current"><a class="current reference internal" href="#">ç«èµè§å</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E7%BB%84%E5%A7%94%E4%BC%9A.html">ç»å§ä¼</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">Contact</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">èç³»æ¹å¼</a></li> |
|---|
| | | </ul> |
|---|
| | | |
|---|
| | | |
|---|
| | |
|---|
| | | <ul class="simple"> |
|---|
| | | <li><p>å
许å¨åå§è®ç»æ°æ®éä¸è¿è¡æ°æ®å¢å¼ºï¼å
æ¬ä½ä¸éäºæ·»å åªå£°ææ··åãé度æ°å¨åé³è°ååã</p></li> |
|---|
| | | <li><p>å
许åèµè
使ç¨Evaléè¿è¡æ¨¡åè®ç»ï¼ä½Testéä»
è½ç¨äºè°åå模åéæ©ï¼ä¸¥ç¦ä»¥ä»»ä½å½¢å¼ä½¿ç¨Test-2023æ°æ®éï¼å
æ¬ä½ä¸éäºä½¿ç¨æµè¯æ°æ®éå¾®è°æè®ç»æ¨¡åã</p></li> |
|---|
| | | <li><p>å
许å¤ç³»ç»èåï¼ä½ä¸é¼å±ä½¿ç¨å
·æç¸åç»æä»
åæ°ä¸åçåç³»ç»èåã</p></li> |
|---|
| | | <li><p>å¦æ两个系ç»çæµè¯cpCERç¸åï¼å计ç®å¤æ度è¾ä½çç³»ç»å°è¢«è®¤å®ä¸ºæ´ä¼ã</p></li> |
|---|
| | | <li><p>å¦æ使ç¨å¼ºå¶å¯¹é½æ¨¡åè·å¾äºé帧åç±»æ ç¾ï¼åå¿
须使ç¨ç¸åºåèµéå
许çæ°æ®å¯¹å¼ºå¶å¯¹é½æ¨¡åè¿è¡è®ç»ã</p></li> |
|---|
| | | <li><p>端å°ç«¯æ¹æ³ä¸å
许使ç¨æµ
å±èåè¯è¨æ¨¡åï¼æ¨¡åå¯ä»¥éæ©LASãRNNTåTransformerçï¼ä½æµ
å±èåè¯è¨æ¨¡åçè®ç»æ°æ®åªè½æ¥èªäºå
许çè®ç»æ°æ®éç转å½ææ¬ã</p></li> |
|---|
| File was renamed from docs_m2met2_cn/_build/html/ÈüµÀÉèÖÃÓëÆÀ¹À.html |
| | |
|---|
| | | </ul> |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1 current"><a class="current reference internal" href="#">èµé设置ä¸è¯ä¼°</a><ul> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="#id2">说è¯äººç¸å
³çè¯é³è¯å« (主èµé)</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="#id2">说è¯äººç¸å
³çè¯é³è¯å«</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="#id3">è¯ä¼°æ¹æ³</a></li> |
|---|
| | | <li class="toctree-l2"><a class="reference internal" href="#id4">åèµé设置</a></li> |
|---|
| | | </ul> |
|---|
| | |
|---|
| | | </li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%A7%84%E5%88%99.html">ç«èµè§å</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E7%BB%84%E5%A7%94%E4%BC%9A.html">ç»å§ä¼</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">Contact</a></li> |
|---|
| | | <li class="toctree-l1"><a class="reference internal" href="%E8%81%94%E7%B3%BB%E6%96%B9%E5%BC%8F.html">èç³»æ¹å¼</a></li> |
|---|
| | | </ul> |
|---|
| | | |
|---|
| | | |
|---|
| | |
|---|
| | | <section id="id1"> |
|---|
| | | <h1>èµé设置ä¸è¯ä¼°<a class="headerlink" href="#id1" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h1> |
|---|
| | | <section id="id2"> |
|---|
| | | <h2>说è¯äººç¸å
³çè¯é³è¯å« (主èµé)<a class="headerlink" href="#id2" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h2> |
|---|
| | | <p>说è¯äººç¸å
³çASRä»»å¡éè¦ä»éå çè¯é³ä¸è¯å«æ¯ä¸ªè¯´è¯äººçè¯é³ï¼å¹¶ä¸ºè¯å«å
容åé
ä¸ä¸ªè¯´è¯äººæ ç¾ãå¾2å±ç¤ºäºè¯´è¯äººç¸å
³è¯é³è¯å«ä»»å¡åå¤è¯´è¯äººè¯é³è¯å«ä»»å¡ç主è¦åºå«ãå¨æ¬æ¬¡ç«èµä¸AliMeetingãAishell4åCn-Celebæ°æ®éå¯ä½ä¸ºåéæ°æ®æºãå¨M2MeTææèµä¸ä½¿ç¨çAliMeetingæ°æ®éå
å«è®ç»ãè¯ä¼°åæµè¯éï¼å¨M2MET2.0å¯ä»¥å¨è®ç»åè¯ä¼°ä¸ä½¿ç¨ãæ¤å¤ï¼ä¸ä¸ªå
å«çº¦10å°æ¶ä¼è®®æ°æ®çæ°çTest-2023éå°æ ¹æ®èµç¨å®æåå¸å¹¶ç¨äºææèµçè¯ååæåãå¼å¾æ³¨æçæ¯ï¼ç»ç»è
å°ä¸æä¾è³æºçè¿åºé³é¢ã转å½ä»¥åçå®æ¶é´æ³ã主åæ¹å°ä¸åæä¾æ¯ä¸ªè¯´è¯äººççå®æ¶é´æ³ï¼èæ¯å¨Test-2023éä¸æä¾å
å«å¤ä¸ªè¯´è¯äººçç段ãè¿äºç段å¯ä»¥éè¿ä¸ä¸ªç®åçvad模åè·å¾ã</p> |
|---|
| | | <h2>说è¯äººç¸å
³çè¯é³è¯å«<a class="headerlink" href="#id2" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h2> |
|---|
| | | <p>说è¯äººç¸å
³çASRä»»å¡éè¦ä»éå çè¯é³ä¸è¯å«æ¯ä¸ªè¯´è¯äººçè¯é³ï¼å¹¶ä¸ºè¯å«å
容åé
ä¸ä¸ªè¯´è¯äººæ ç¾ãå¾2å±ç¤ºäºè¯´è¯äººç¸å
³è¯é³è¯å«ä»»å¡åå¤è¯´è¯äººè¯é³è¯å«ä»»å¡ç主è¦åºå«ãå¨æ¬æ¬¡ç«èµä¸AliMeetingãAishell4åCn-Celebæ°æ®éå¯ä½ä¸ºåéæ°æ®æºãå¨M2MeTææèµä¸ä½¿ç¨çAliMeetingæ°æ®éå
å«è®ç»ãè¯ä¼°åæµè¯éï¼å¨M2MET2.0å¯ä»¥å¨è®ç»åè¯ä¼°ä¸ä½¿ç¨ãæ¤å¤ï¼ä¸ä¸ªå
å«çº¦10å°æ¶ä¼è®®æ°æ®çæ°çTest-2023éå°æ ¹æ®èµç¨å®æåå¸å¹¶ç¨äºææèµçè¯ååæåãå¼å¾æ³¨æçæ¯ï¼å¯¹äºTest-2023æµè¯éï¼ä¸»åæ¹å°ä¸åæä¾è³æºçè¿åºé³é¢ã转å½ä»¥åçå®æ¶é´æ³ãèæ¯æä¾å¯ä»¥éè¿ä¸ä¸ªç®åçVAD模åå¾å°çå
å«å¤ä¸ªè¯´è¯äººçç段ã</p> |
|---|
| | | <p><img alt="task difference" src="_images/task_diff.png" /></p> |
|---|
| | | </section> |
|---|
| | | <section id="id3"> |
|---|
| | |
|---|
| | | <h2>åèµé设置<a class="headerlink" href="#id4" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h2> |
|---|
| | | <section id="id5"> |
|---|
| | | <h3>åèµéä¸ (éå®è®ç»æ°æ®):<a class="headerlink" href="#id5" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h3> |
|---|
| | | <p>åèµè
å¨ç³»ç»æ建è¿ç¨ä¸ä»
è½ä½¿ç¨AliMeetingãAISHELL-4åCN Celebï¼ä¸¥ç¦ä½¿ç¨é¢å¤æ°æ®ãåèµè
å¯ä»¥ä»»ä½ç¬¬ä¸æ¹å¼æºçé¢è®ç»æ¨¡åï¼å¦<a class="reference external" href="https://huggingface.co/models">Hugging Face</a>以å<a class="reference external" href="https://www.modelscope.cn/models">ModelScope</a>ä¸æä¾ç模åãåèµè
éè¦å¨æç»çç³»ç»æè¿°ææ¡£ä¸è¯¦ç»ååºä½¿ç¨çé¢è®ç»æ¨¡åå称以åé¾æ¥ã</p> |
|---|
| | | <p>åèµè
å¨ç³»ç»æ建è¿ç¨ä¸ä»
è½ä½¿ç¨AliMeetingãAISHELL-4åCN-Celebï¼ä¸¥ç¦ä½¿ç¨é¢å¤æ°æ®ãåèµè
å¯ä»¥ä»»ä½ç¬¬ä¸æ¹å¼æºçé¢è®ç»æ¨¡åï¼å¦<a class="reference external" href="https://huggingface.co/models">Hugging Face</a>以å<a class="reference external" href="https://www.modelscope.cn/models">ModelScope</a>ä¸æä¾ç模åãåèµè
éè¦å¨æç»çç³»ç»æè¿°ææ¡£ä¸è¯¦ç»ååºä½¿ç¨çé¢è®ç»æ¨¡åå称以åé¾æ¥ã</p> |
|---|
| | | </section> |
|---|
| | | <section id="id6"> |
|---|
| | | <h3>åèµéäº (å¼æ¾è®ç»æ°æ®):<a class="headerlink" href="#id6" title="æ¤æ é¢çæ°¸ä¹
é¾æ¥">¶</a></h3> |
|---|
| File was renamed from docs_m2met2_cn/index.rst |
| | |
|---|
| | | ./è§å |
|---|
| | | ./ç»å§ä¼ |
|---|
| | | ./èç³»æ¹å¼ |
|---|
| | | |
|---|
| | | Indices and tables |
|---|
| | | ================== |
|---|
| | | |
|---|
| | | * :ref:`genindex` |
|---|
| | | * :ref:`modindex` |
|---|
| | | * :ref:`search` |
|---|
| File was renamed from docs_m2met2_cn/Êý¾Ý¼¯.md |
| | |
|---|
| | | å¨éå®æ°æ®éæ¡ä»¶ä¸ï¼è®ç»æ°æ®éä»
éäºä¸ä¸ªå
¬å¼çè¯æåºï¼å³AliMeetingãAISHELL-4åCN-Celebã为äºè¯ä¼°åèµè
æ交ç模åçæ§è½ï¼æ们å°åå¸ä¸ä¸ªæ°çæµè¯éï¼Test-2023ï¼ç¨äºæååæåãä¸é¢æ们å°è¯¦ç»æè¿°AliMeetingæ°æ®éåTest-2023æµè¯éã |
|---|
| | | |
|---|
| | | ## Alimeetingæ°æ®éä»ç» |
|---|
| | | AliMeetingæ»å
±å
å«118.75å°æ¶çè¯é³æ°æ®ï¼å
æ¬104.75å°æ¶çè®ç»éï¼Trainï¼ã4å°æ¶çéªè¯éï¼Evalï¼å10å°æ¶çæµè¯éï¼Testï¼ãTrainéåEvaléåå«å
å«212åºå8åºä¼è®®ï¼å
¶ä¸æ¯åºä¼è®®ç±å¤ä¸ªè¯´è¯äººè¿è¡15å°30åéç讨论ãTrainåEvaléä¸åä¸ä¼è®®çæ»äººæ°åå«ä¸º456人å25人ï¼å¹¶ä¸åä¼çç·å¥³æ¯ä¾äººæ°åè¡¡ã |
|---|
| | | AliMeetingæ»å
±å
å«118.75å°æ¶çè¯é³æ°æ®ï¼å
æ¬104.75å°æ¶çè®ç»éï¼Trainï¼ã4å°æ¶çéªè¯éï¼Evalï¼å10å°æ¶çæµè¯éï¼Testï¼ãTrainéï¼EvaléåTestéåå«å
å«212åºå8åºä¼è®®ï¼å
¶ä¸æ¯åºä¼è®®ç±å¤ä¸ªè¯´è¯äººè¿è¡15å°30åéç讨论ãTrainï¼EvalåTestéä¸åä¸ä¼è®®çæ»äººæ°åå«ä¸º456人å25人ï¼å¹¶ä¸åä¼çç·å¥³æ¯ä¾äººæ°åè¡¡ã |
|---|
| | | |
|---|
| | | 该æ°æ®éæ¶éäº13个ä¸åçä¼è®®å®¤ï¼æç
§å¤§å°è§æ ¼å为å°åãä¸åå大åä¸ç§ï¼æ¿é´é¢ç§¯ä»8å°55å¹³æ¹ç±³ä¸çãä¸åæ¿é´å
·æä¸åçå¸å±å声å¦ç¹æ§ï¼æ¯ä¸ªæ¿é´ç详ç»åæ°ä¹å°åéç»åä¸è
ãä¼è®®åºå°çå¢ä½ææç±»åå
æ¬æ°´æ³¥ãç»ççãä¼è®®åºå°ç家å
·å
æ¬æ²åãçµè§ãé»æ¿ãé£æã空è°ãæ¤ç©çãå¨å½å¶è¿ç¨ä¸ï¼éº¦å
é£éµåæ¾ç½®äºæ¡ä¸ï¼å¤ä¸ªè¯´è¯äººå´åå¨æ¡è¾¹è¿è¡èªç¶å¯¹è¯ã麦å
é£éµå离说è¯äººè·ç¦»çº¦0.3å°5.0ç±³ä¹é´ãææ说è¯äººçæ¯è¯åæ¯æ±è¯ï¼å¹¶ä¸è¯´çé½æ¯æ®éè¯ï¼æ²¡ææµéçå£é³ãå¨ä¼è®®å½å¶æé´å¯è½ä¼äº§çåç§å®¤å
çåªé³ï¼å
æ¬é®ç声ãå¼é¨/å
³é¨å£°ãé£æ声ãæ°æ³¡å£°çãææ说è¯äººå¨ä¼è®®çå½å¶æé´åä¿æç¸åä½ç½®ï¼ä¸åçèµ°å¨ãè®ç»éåéªè¯éç说è¯äººæ²¡æéå¤ãå¾1å±ç¤ºäºä¸ä¸ªä¼è®®å®¤çå¸å±ä»¥å麦å
é£çææç»æã |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| | | æ¯åºä¼è®®ç说è¯äººæ°éä»2å°4人ä¸çãåæ¶ä¸ºäºè¦çåç§å
容çä¼è®®åºæ¯ï¼æ们éæ©äºå¤ç§ä¼è®®ä¸»é¢ï¼å
æ¬å»çãæè²ãåä¸ãç»ç»ç®¡çãå·¥ä¸ç产çä¸åå
容çä¾ä¼ãTrainéï¼EvaléåTestéçå¹³åè¯é³éå çåå«ä¸º42.27\%å34.76\%ãAliMeeting Trainéï¼EvaléåTestéç详ç»ä¿¡æ¯è§è¡¨1ã表2æ¾ç¤ºäºTrainé,EvaléåTestéä¸ä¸ååè¨è
人æ°ä¼è®®çè¯é³éå çåä¼è®®æ°éã |
|---|
| | | æ¯åºä¼è®®ç说è¯äººæ°éä»2å°4人ä¸çãåæ¶ä¸ºäºè¦çåç§å
容çä¼è®®åºæ¯ï¼æ们éæ©äºå¤ç§ä¼è®®ä¸»é¢ï¼å
æ¬å»çãæè²ãåä¸ãç»ç»ç®¡çãå·¥ä¸ç产çä¸åå
容çä¾ä¼ãTrainéï¼EvaléåTestéçå¹³åè¯é³éå çåå«ä¸º42.27\%ï¼34.76\%å42.8\%ãAliMeeting Trainéï¼EvaléåTestéç详ç»ä¿¡æ¯è§è¡¨1ã表2æ¾ç¤ºäºTrainé,EvaléåTestéä¸ä¸ååè¨è
人æ°ä¼è®®çè¯é³éå çåä¼è®®æ°éã |
|---|
| | | |
|---|
| | |  |
|---|
| | | Test-2023æµè¯éç±20åºä¼è®®ç»æï¼è¿äºä¼è®®æ¯å¨ä¸AliMeetingæ°æ®éç¸åç声å¦ç¯å¢ä¸å½å¶çãTest-2023æµè¯éä¸çæ¯ä¸ªä¼è®®ç¯èç±2å°4个åä¸è
ç»æ并ä¸ä¸AliMeetingæµè¯éçé
ç½®ç¸ä¼¼ã |
|---|
| File was renamed from docs_m2met2_cn/¼ò½é.md |
| | |
|---|
| | | |
|---|
| | | ## æ¶é´å®æ(AOEæ¶é´) |
|---|
| | | |
|---|
| | | - $ 2023.5.5: $ åèµè
注åæªæ¢ |
|---|
| | | - $ 2023.4.29: $ å¼æ¾æ³¨å |
|---|
| | | - $ 2023.5.8: $ åºçº¿åå¸ |
|---|
| | | - $ 2023.5.15: $ 注åæªæ¢ |
|---|
| | | - $ 2023.6.9: $ æµè¯éæ°æ®åå¸ |
|---|
| | | - $ 2023.6.13: $ æç»ç»ææ交æªæ¢ |
|---|
| | | - $ 2023.6.19: $ è¯ä¼°ç»æåæååå¸ |
|---|
| | | - $ 2023.7.3: $ 论ææ交æªæ¢ |
|---|
| | | - $ 2023.7.10: $ æç»ç论ææ交æªæ¢ |
|---|
| | | - $ 2023.12.12: $ ASRU Workshop |
|---|
| | | - $ 2023.12.12: $ ASRU Workshop & challenge session |
|---|
| | | |
|---|
| | | ## ç«èµæ¥å |
|---|
| | | |
|---|
| | | æ¥èªå¦æ¯çåå·¥ä¸ççææååèµè
ååºå¨2023å¹´5æ5æ¥åä¹åå¡«åä¸æ¹çè°·æ表åï¼ |
|---|
| | | æ¥èªå¦æ¯çåå·¥ä¸ççææååèµè
ååºå¨2023å¹´5æ15æ¥åä¹åå¡«åä¸æ¹çè°·æ表åï¼ |
|---|
| | | |
|---|
| | | [M2MET2.0æ¥å](https://docs.google.com/forms/d/e/1FAIpQLSf77T9vAl7Ym-u5g8gXu18SBofoWRaFShBo26Ym0-HDxHW9PQ/viewform?usp=sf_link) |
|---|
| | | |
|---|
| | | 主åæ¹å°å¨3个工ä½æ¥å
éè¿çµåé®ä»¶éç¥ç¬¦åæ¡ä»¶çåèµå¢éï¼å¢éå¿
é¡»éµå®å°å¨ææç½ç«ä¸åå¸çææè§åãå¨æååå¸ä¹åï¼æ¯ä¸ªåèµè
å¿
é¡»æ交ä¸ä»½ç³»ç»æè¿°æ件ï¼è¯¦ç»è¯´æ使ç¨çæ¹æ³å模åã主åæ¹å°éæ©åä¸å纳å
¥ASRU2023论æéã |
|---|
| File was renamed from docs_m2met2_cn/¹æÔò.md |
| | |
|---|
| | | - å
许å¨åå§è®ç»æ°æ®éä¸è¿è¡æ°æ®å¢å¼ºï¼å
æ¬ä½ä¸éäºæ·»å åªå£°ææ··åãé度æ°å¨åé³è°ååã |
|---|
| | | |
|---|
| | | - å
许åèµè
使ç¨Evaléè¿è¡æ¨¡åè®ç»ï¼ä½Testéä»
è½ç¨äºè°åå模åéæ©ï¼ä¸¥ç¦ä»¥ä»»ä½å½¢å¼ä½¿ç¨Test-2023æ°æ®éï¼å
æ¬ä½ä¸éäºä½¿ç¨æµè¯æ°æ®éå¾®è°æè®ç»æ¨¡åã |
|---|
| | | |
|---|
| | | - å
许å¤ç³»ç»èåï¼ä½ä¸é¼å±ä½¿ç¨å
·æç¸åç»æä»
åæ°ä¸åçåç³»ç»èåã |
|---|
| | | |
|---|
| | | - å¦æ两个系ç»çæµè¯cpCERç¸åï¼å计ç®å¤æ度è¾ä½çç³»ç»å°è¢«è®¤å®ä¸ºæ´ä¼ã |
|---|
| | | |
|---|
| File was renamed from docs_m2met2_cn/ÈüµÀÉèÖÃÓëÆÀ¹À.md |
| | |
|---|
| | | # èµé设置ä¸è¯ä¼° |
|---|
| | | ## 说è¯äººç¸å
³çè¯é³è¯å« (主èµé) |
|---|
| | | 说è¯äººç¸å
³çASRä»»å¡éè¦ä»éå çè¯é³ä¸è¯å«æ¯ä¸ªè¯´è¯äººçè¯é³ï¼å¹¶ä¸ºè¯å«å
容åé
ä¸ä¸ªè¯´è¯äººæ ç¾ãå¾2å±ç¤ºäºè¯´è¯äººç¸å
³è¯é³è¯å«ä»»å¡åå¤è¯´è¯äººè¯é³è¯å«ä»»å¡ç主è¦åºå«ãå¨æ¬æ¬¡ç«èµä¸AliMeetingãAishell4åCn-Celebæ°æ®éå¯ä½ä¸ºåéæ°æ®æºãå¨M2MeTææèµä¸ä½¿ç¨çAliMeetingæ°æ®éå
å«è®ç»ãè¯ä¼°åæµè¯éï¼å¨M2MET2.0å¯ä»¥å¨è®ç»åè¯ä¼°ä¸ä½¿ç¨ãæ¤å¤ï¼ä¸ä¸ªå
å«çº¦10å°æ¶ä¼è®®æ°æ®çæ°çTest-2023éå°æ ¹æ®èµç¨å®æåå¸å¹¶ç¨äºææèµçè¯ååæåãå¼å¾æ³¨æçæ¯ï¼ç»ç»è
å°ä¸æä¾è³æºçè¿åºé³é¢ã转å½ä»¥åçå®æ¶é´æ³ã主åæ¹å°ä¸åæä¾æ¯ä¸ªè¯´è¯äººççå®æ¶é´æ³ï¼èæ¯å¨Test-2023éä¸æä¾å
å«å¤ä¸ªè¯´è¯äººçç段ãè¿äºç段å¯ä»¥éè¿ä¸ä¸ªç®åçvad模åè·å¾ã |
|---|
| | | ## 说è¯äººç¸å
³çè¯é³è¯å« |
|---|
| | | 说è¯äººç¸å
³çASRä»»å¡éè¦ä»éå çè¯é³ä¸è¯å«æ¯ä¸ªè¯´è¯äººçè¯é³ï¼å¹¶ä¸ºè¯å«å
容åé
ä¸ä¸ªè¯´è¯äººæ ç¾ãå¾2å±ç¤ºäºè¯´è¯äººç¸å
³è¯é³è¯å«ä»»å¡åå¤è¯´è¯äººè¯é³è¯å«ä»»å¡ç主è¦åºå«ãå¨æ¬æ¬¡ç«èµä¸AliMeetingãAishell4åCn-Celebæ°æ®éå¯ä½ä¸ºåéæ°æ®æºãå¨M2MeTææèµä¸ä½¿ç¨çAliMeetingæ°æ®éå
å«è®ç»ãè¯ä¼°åæµè¯éï¼å¨M2MET2.0å¯ä»¥å¨è®ç»åè¯ä¼°ä¸ä½¿ç¨ãæ¤å¤ï¼ä¸ä¸ªå
å«çº¦10å°æ¶ä¼è®®æ°æ®çæ°çTest-2023éå°æ ¹æ®èµç¨å®æåå¸å¹¶ç¨äºææèµçè¯ååæåãå¼å¾æ³¨æçæ¯ï¼å¯¹äºTest-2023æµè¯éï¼ä¸»åæ¹å°ä¸åæä¾è³æºçè¿åºé³é¢ã转å½ä»¥åçå®æ¶é´æ³ãèæ¯æä¾å¯ä»¥éè¿ä¸ä¸ªç®åçVAD模åå¾å°çå
å«å¤ä¸ªè¯´è¯äººçç段ã |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| | |
|---|
| | | å
¶ä¸ $\mathcal N_{\text{Ins}}$ , $\mathcal N_{\text{Sub}}$ , $\mathcal N_{\text{Del}}$ æ¯ä¸ç§é误çå符æ°, $\mathcal N_{\text{Total}}$ æ¯å符æ»æ°. |
|---|
| | | ## åèµé设置 |
|---|
| | | ### åèµéä¸ (éå®è®ç»æ°æ®): |
|---|
| | | åèµè
å¨ç³»ç»æ建è¿ç¨ä¸ä»
è½ä½¿ç¨AliMeetingãAISHELL-4åCN Celebï¼ä¸¥ç¦ä½¿ç¨é¢å¤æ°æ®ãåèµè
å¯ä»¥ä»»ä½ç¬¬ä¸æ¹å¼æºçé¢è®ç»æ¨¡åï¼å¦[Hugging Face](https://huggingface.co/models)以å[ModelScope](https://www.modelscope.cn/models)ä¸æä¾ç模åãåèµè
éè¦å¨æç»çç³»ç»æè¿°ææ¡£ä¸è¯¦ç»ååºä½¿ç¨çé¢è®ç»æ¨¡åå称以åé¾æ¥ã |
|---|
| | | åèµè
å¨ç³»ç»æ建è¿ç¨ä¸ä»
è½ä½¿ç¨AliMeetingãAISHELL-4åCN-Celebï¼ä¸¥ç¦ä½¿ç¨é¢å¤æ°æ®ãåèµè
å¯ä»¥ä»»ä½ç¬¬ä¸æ¹å¼æºçé¢è®ç»æ¨¡åï¼å¦[Hugging Face](https://huggingface.co/models)以å[ModelScope](https://www.modelscope.cn/models)ä¸æä¾ç模åãåèµè
éè¦å¨æç»çç³»ç»æè¿°ææ¡£ä¸è¯¦ç»ååºä½¿ç¨çé¢è®ç»æ¨¡åå称以åé¾æ¥ã |
|---|
| | | ### åèµéäº (å¼æ¾è®ç»æ°æ®): |
|---|
| | | é¤äºéå®æ°æ®å¤ï¼åä¸è
å¯ä»¥ä½¿ç¨ä»»ä½å
¬å¼å¯ç¨ãç§äººå½å¶å模æ仿ççæ°æ®éãä½æ¯ï¼åä¸è
å¿
é¡»æ¸
æ¥å°ååºä½¿ç¨çæ°æ®ãåæ ·ï¼åèµè
ä¹å¯ä»¥ä½¿ç¨ä»»ä½ç¬¬ä¸æ¹å¼æºçé¢è®ç»æ¨¡åï¼ä½å¿
é¡»å¨æåçç³»ç»æè¿°æ件ä¸æç¡®çååºæ使ç¨çæ°æ®å模åé¾æ¥ï¼å¦æ使ç¨æ¨¡æ仿çæ°æ®ï¼è¯·è¯¦ç»æè¿°æ°æ®æ¨¡æçæ¹æ¡ã |
|---|
| | |
|---|
| | | #### [RNN-T-online model]() |
|---|
| | | Undo |
|---|
| | | |
|---|
| | | #### [MFCCA Model](https://www.modelscope.cn/models/NPU-ASLP/speech_mfcca_asr-zh-cn-16k-alimeeting-vocab4950/summary) |
|---|
| | | For more model detailes, please refer to [docs](https://www.modelscope.cn/models/NPU-ASLP/speech_mfcca_asr-zh-cn-16k-alimeeting-vocab4950/summary) |
|---|
| | | ```python |
|---|
| | | from modelscope.pipelines import pipeline |
|---|
| | | from modelscope.utils.constant import Tasks |
|---|
| | | |
|---|
| | | inference_pipeline = pipeline( |
|---|
| | | task=Tasks.auto_speech_recognition, |
|---|
| | | model='NPU-ASLP/speech_mfcca_asr-zh-cn-16k-alimeeting-vocab4950', |
|---|
| | | model_revision='v3.0.0' |
|---|
| | | ) |
|---|
| | | |
|---|
| | | rec_result = inference_pipeline(audio_in='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav') |
|---|
| | | print(rec_result) |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | #### API-reference |
|---|
| | | ##### Define pipeline |
|---|
| | | - `task`: `Tasks.auto_speech_recognition` |
|---|
| | |
|---|
| | | - `njob`: only used for CPU inference (`gpu_inference`=`false`), `64` (Default), the number of jobs for CPU decoding |
|---|
| | | - `checkpoint_dir`: only used for infer finetuned models, the path dir of finetuned models |
|---|
| | | - `checkpoint_name`: only used for infer finetuned models, `valid.cer_ctc.ave.pb` (Default), which checkpoint is used to infer |
|---|
| | | - `decoding_mode`: `normal` (Default), decoding mode for UniASR model(fastãnormalãoffline) |
|---|
| | | - `hotword_txt`: `None` (Default), hotword file for contextual paraformer model(the hotword file name ends with .txt") |
|---|
| | | |
|---|
| | | - Decode with multi GPUs: |
|---|
| | | ```shell |
|---|
| | |
|---|
| | | model=args.model, |
|---|
| | | output_dir=args.output_dir, |
|---|
| | | batch_size=args.batch_size, |
|---|
| | | param_dict={"decoding_model": args.decoding_mode, "hotword": args.hotword_txt} |
|---|
| | | ) |
|---|
| | | inference_pipeline(audio_in=args.audio_in) |
|---|
| | | |
|---|
| | |
|---|
| | | parser.add_argument('--model', type=str, default="damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch") |
|---|
| | | parser.add_argument('--audio_in', type=str, default="./data/test/wav.scp") |
|---|
| | | parser.add_argument('--output_dir', type=str, default="./results/") |
|---|
| | | parser.add_argument('--decoding_mode', type=str, default="normal") |
|---|
| | | parser.add_argument('--hotword_txt', type=str, default=None) |
|---|
| | | parser.add_argument('--batch_size', type=int, default=64) |
|---|
| | | parser.add_argument('--gpuid', type=str, default="0") |
|---|
| | | args = parser.parse_args() |
|---|
| New file |
| | |
|---|
| | | ../../TEMPLATE/README.md |
|---|
| | |
|---|
| | | import os |
|---|
| | | import shutil |
|---|
| | | from multiprocessing import Pool |
|---|
| | | |
|---|
| | | import argparse |
|---|
| | | from modelscope.pipelines import pipeline |
|---|
| | | from modelscope.utils.constant import Tasks |
|---|
| | | |
|---|
| | | from funasr.utils.compute_wer import compute_wer |
|---|
| | | |
|---|
| | | def modelscope_infer_core(output_dir, split_dir, njob, idx): |
|---|
| | | output_dir_job = os.path.join(output_dir, "output.{}".format(idx)) |
|---|
| | | gpu_id = (int(idx) - 1) // njob |
|---|
| | | if "CUDA_VISIBLE_DEVICES" in os.environ.keys(): |
|---|
| | | gpu_list = os.environ['CUDA_VISIBLE_DEVICES'].split(",") |
|---|
| | | os.environ['CUDA_VISIBLE_DEVICES'] = str(gpu_list[gpu_id]) |
|---|
| | | else: |
|---|
| | | os.environ['CUDA_VISIBLE_DEVICES'] = str(gpu_id) |
|---|
| | | inference_pipline = pipeline( |
|---|
| | | def modelscope_infer(args): |
|---|
| | | os.environ['CUDA_VISIBLE_DEVICES'] = str(args.gpuid) |
|---|
| | | inference_pipeline = pipeline( |
|---|
| | | task=Tasks.auto_speech_recognition, |
|---|
| | | model='NPU-ASLP/speech_mfcca_asr-zh-cn-16k-alimeeting-vocab4950', |
|---|
| | | model_revision='v3.0.0', |
|---|
| | | output_dir=output_dir_job, |
|---|
| | | batch_size=1, |
|---|
| | | model=args.model, |
|---|
| | | model_revision=args.model_revision, |
|---|
| | | output_dir=args.output_dir, |
|---|
| | | batch_size=args.batch_size, |
|---|
| | | ) |
|---|
| | | audio_in = os.path.join(split_dir, "wav.{}.scp".format(idx)) |
|---|
| | | inference_pipline(audio_in=audio_in) |
|---|
| | | |
|---|
| | | |
|---|
| | | def modelscope_infer(params): |
|---|
| | | # prepare for multi-GPU decoding |
|---|
| | | ngpu = params["ngpu"] |
|---|
| | | njob = params["njob"] |
|---|
| | | output_dir = params["output_dir"] |
|---|
| | | if os.path.exists(output_dir): |
|---|
| | | shutil.rmtree(output_dir) |
|---|
| | | os.mkdir(output_dir) |
|---|
| | | split_dir = os.path.join(output_dir, "split") |
|---|
| | | os.mkdir(split_dir) |
|---|
| | | nj = ngpu * njob |
|---|
| | | wav_scp_file = os.path.join(params["data_dir"], "wav.scp") |
|---|
| | | with open(wav_scp_file) as f: |
|---|
| | | lines = f.readlines() |
|---|
| | | num_lines = len(lines) |
|---|
| | | num_job_lines = num_lines // nj |
|---|
| | | start = 0 |
|---|
| | | for i in range(nj): |
|---|
| | | end = start + num_job_lines |
|---|
| | | file = os.path.join(split_dir, "wav.{}.scp".format(str(i + 1))) |
|---|
| | | with open(file, "w") as f: |
|---|
| | | if i == nj - 1: |
|---|
| | | f.writelines(lines[start:]) |
|---|
| | | else: |
|---|
| | | f.writelines(lines[start:end]) |
|---|
| | | start = end |
|---|
| | | p = Pool(nj) |
|---|
| | | for i in range(nj): |
|---|
| | | p.apply_async(modelscope_infer_core, |
|---|
| | | args=(output_dir, split_dir, njob, str(i + 1))) |
|---|
| | | p.close() |
|---|
| | | p.join() |
|---|
| | | |
|---|
| | | # combine decoding results |
|---|
| | | best_recog_path = os.path.join(output_dir, "1best_recog") |
|---|
| | | os.mkdir(best_recog_path) |
|---|
| | | files = ["text", "token", "score"] |
|---|
| | | for file in files: |
|---|
| | | with open(os.path.join(best_recog_path, file), "w") as f: |
|---|
| | | for i in range(nj): |
|---|
| | | job_file = os.path.join(output_dir, "output.{}/1best_recog".format(str(i + 1)), file) |
|---|
| | | with open(job_file) as f_job: |
|---|
| | | lines = f_job.readlines() |
|---|
| | | f.writelines(lines) |
|---|
| | | |
|---|
| | | # If text exists, compute CER |
|---|
| | | text_in = os.path.join(params["data_dir"], "text") |
|---|
| | | if os.path.exists(text_in): |
|---|
| | | text_proc_file = os.path.join(best_recog_path, "token") |
|---|
| | | text_proc_file2 = os.path.join(best_recog_path, "token_nosep") |
|---|
| | | with open(text_proc_file, 'r') as hyp_reader: |
|---|
| | | with open(text_proc_file2, 'w') as hyp_writer: |
|---|
| | | for line in hyp_reader: |
|---|
| | | new_context = line.strip().replace("src","").replace(" "," ").replace(" "," ").strip() |
|---|
| | | hyp_writer.write(new_context+'\n') |
|---|
| | | text_in2 = os.path.join(best_recog_path, "ref_text_nosep") |
|---|
| | | with open(text_in, 'r') as ref_reader: |
|---|
| | | with open(text_in2, 'w') as ref_writer: |
|---|
| | | for line in ref_reader: |
|---|
| | | new_context = line.strip().replace("src","").replace(" "," ").replace(" "," ").strip() |
|---|
| | | ref_writer.write(new_context+'\n') |
|---|
| | | |
|---|
| | | |
|---|
| | | compute_wer(text_in, text_proc_file, os.path.join(best_recog_path, "text.sp.cer")) |
|---|
| | | compute_wer(text_in2, text_proc_file2, os.path.join(best_recog_path, "text.nosp.cer")) |
|---|
| | | |
|---|
| | | inference_pipeline(audio_in=args.audio_in) |
|---|
| | | |
|---|
| | | if __name__ == "__main__": |
|---|
| | | params = {} |
|---|
| | | params["data_dir"] = "./example_data/validation" |
|---|
| | | params["output_dir"] = "./output_dir" |
|---|
| | | params["ngpu"] = 1 |
|---|
| | | params["njob"] = 1 |
|---|
| | | modelscope_infer(params) |
|---|
| | | parser = argparse.ArgumentParser() |
|---|
| | | parser.add_argument('--model', type=str, default="NPU-ASLP/speech_mfcca_asr-zh-cn-16k-alimeeting-vocab4950") |
|---|
| | | parser.add_argument('--model_revision', type=str, default="v3.0.0") |
|---|
| | | parser.add_argument('--audio_in', type=str, default="./data/test/wav.scp") |
|---|
| | | parser.add_argument('--output_dir', type=str, default="./results/") |
|---|
| | | parser.add_argument('--batch_size', type=int, default=1) |
|---|
| | | parser.add_argument('--gpuid', type=str, default="0") |
|---|
| | | args = parser.parse_args() |
|---|
| | | modelscope_infer(args) |
|---|
| New file |
| | |
|---|
| | | #!/usr/bin/env bash |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | set -u |
|---|
| | | set -o pipefail |
|---|
| | | |
|---|
| | | stage=1 |
|---|
| | | stop_stage=3 |
|---|
| | | model="NPU-ASLP/speech_mfcca_asr-zh-cn-16k-alimeeting-vocab4950" |
|---|
| | | data_dir="./data/test" |
|---|
| | | output_dir="./results_pl_gpu" |
|---|
| | | batch_size=1 |
|---|
| | | gpu_inference=true # whether to perform gpu decoding |
|---|
| | | gpuid_list="3,4" # set gpus, e.g., gpuid_list="0,1" |
|---|
| | | njob=4 # the number of jobs for CPU decoding, if gpu_inference=false, use CPU decoding, please set njob |
|---|
| | | |
|---|
| | | . utils/parse_options.sh || exit 1; |
|---|
| | | |
|---|
| | | if ${gpu_inference} == "true"; then |
|---|
| | | nj=$(echo $gpuid_list | awk -F "," '{print NF}') |
|---|
| | | else |
|---|
| | | nj=$njob |
|---|
| | | batch_size=1 |
|---|
| | | gpuid_list="" |
|---|
| | | for JOB in $(seq ${nj}); do |
|---|
| | | gpuid_list=$gpuid_list"-1," |
|---|
| | | done |
|---|
| | | fi |
|---|
| | | |
|---|
| | | mkdir -p $output_dir/split |
|---|
| | | split_scps="" |
|---|
| | | for JOB in $(seq ${nj}); do |
|---|
| | | split_scps="$split_scps $output_dir/split/wav.$JOB.scp" |
|---|
| | | done |
|---|
| | | perl utils/split_scp.pl ${data_dir}/wav.scp ${split_scps} |
|---|
| | | |
|---|
| | | if [ $stage -le 1 ] && [ $stop_stage -ge 1 ];then |
|---|
| | | echo "Decoding ..." |
|---|
| | | gpuid_list_array=(${gpuid_list//,/ }) |
|---|
| | | ./utils/run.pl JOB=1:${nj} ${output_dir}/log/infer.JOB.log \ |
|---|
| | | python infer.py \ |
|---|
| | | --model ${model} \ |
|---|
| | | --audio_in ${output_dir}/split/wav.JOB.scp \ |
|---|
| | | --output_dir ${output_dir}/output.JOB \ |
|---|
| | | --batch_size ${batch_size} \ |
|---|
| | | --gpuid ${gpuid_list_array[JOB-1]} |
|---|
| | | |
|---|
| | | mkdir -p ${output_dir}/1best_recog |
|---|
| | | for f in token score text; do |
|---|
| | | if [ -f "${output_dir}/output.1/1best_recog/${f}" ]; then |
|---|
| | | for i in $(seq "${nj}"); do |
|---|
| | | cat "${output_dir}/output.${i}/1best_recog/${f}" |
|---|
| | | done | sort -k1 >"${output_dir}/1best_recog/${f}" |
|---|
| | | fi |
|---|
| | | done |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ $stage -le 2 ] && [ $stop_stage -ge 2 ];then |
|---|
| | | echo "Computing WER ..." |
|---|
| | | cp ${output_dir}/1best_recog/token ${output_dir}/1best_recog/text.proc |
|---|
| | | cp ${data_dir}/text ${output_dir}/1best_recog/text.ref |
|---|
| | | sed -e 's/src//g' ${output_dir}/1best_recog/text.proc | sed -e 's/ \+/ /g' > ${output_dir}/1best_recog/text_nosp.proc |
|---|
| | | sed -e 's/src//g' ${output_dir}/1best_recog/text.ref | sed -e 's/ \+/ /g' > ${output_dir}/1best_recog/text_nosp.ref |
|---|
| | | |
|---|
| | | python utils/compute_wer.py ${output_dir}/1best_recog/text.ref ${output_dir}/1best_recog/text.proc ${output_dir}/1best_recog/text.sp.cer |
|---|
| | | tail -n 3 ${output_dir}/1best_recog/text.sp.cer |
|---|
| | | python utils/compute_wer.py ${output_dir}/1best_recog/text_nosp.ref ${output_dir}/1best_recog/text_nosp.proc ${output_dir}/1best_recog/text.nosp.cer |
|---|
| | | tail -n 3 ${output_dir}/1best_recog/text.nosp.cer |
|---|
| | | fi |
|---|
| | | |
|---|
| New file |
| | |
|---|
| | | ../../../../egs/aishell/transformer/utils |
|---|
| New file |
| | |
|---|
| | | from modelscope.pipelines import pipeline |
|---|
| | | from modelscope.utils.constant import Tasks |
|---|
| | | |
|---|
| | | param_dict = dict() |
|---|
| | | param_dict['hotword'] = "https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/hotword.txt" |
|---|
| | | inference_pipeline = pipeline( |
|---|
| | | task=Tasks.auto_speech_recognition, |
|---|
| | | model="damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404", |
|---|
| | | param_dict=param_dict) |
|---|
| | | |
|---|
| | | rec_result = inference_pipeline(audio_in='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_hotword.wav') |
|---|
| | | print(rec_result) |
|---|
| New file |
| | |
|---|
| | | ../../TEMPLATE/infer.py |
|---|
| New file |
| | |
|---|
| | | #!/usr/bin/env bash |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | set -u |
|---|
| | | set -o pipefail |
|---|
| | | |
|---|
| | | stage=1 |
|---|
| | | stop_stage=2 |
|---|
| | | model="damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404" |
|---|
| | | data_dir="./data/test" |
|---|
| | | output_dir="./results" |
|---|
| | | batch_size=64 |
|---|
| | | gpu_inference=true # whether to perform gpu decoding |
|---|
| | | gpuid_list="0,1" # set gpus, e.g., gpuid_list="0,1" |
|---|
| | | njob=64 # the number of jobs for CPU decoding, if gpu_inference=false, use CPU decoding, please set njob |
|---|
| | | checkpoint_dir= |
|---|
| | | checkpoint_name="valid.cer_ctc.ave.pb" |
|---|
| | | hotword_txt=None |
|---|
| | | |
|---|
| | | . utils/parse_options.sh || exit 1; |
|---|
| | | |
|---|
| | | if ${gpu_inference} == "true"; then |
|---|
| | | nj=$(echo $gpuid_list | awk -F "," '{print NF}') |
|---|
| | | else |
|---|
| | | nj=$njob |
|---|
| | | batch_size=1 |
|---|
| | | gpuid_list="" |
|---|
| | | for JOB in $(seq ${nj}); do |
|---|
| | | gpuid_list=$gpuid_list"-1," |
|---|
| | | done |
|---|
| | | fi |
|---|
| | | |
|---|
| | | mkdir -p $output_dir/split |
|---|
| | | split_scps="" |
|---|
| | | for JOB in $(seq ${nj}); do |
|---|
| | | split_scps="$split_scps $output_dir/split/wav.$JOB.scp" |
|---|
| | | done |
|---|
| | | perl utils/split_scp.pl ${data_dir}/wav.scp ${split_scps} |
|---|
| | | |
|---|
| | | if [ -n "${checkpoint_dir}" ]; then |
|---|
| | | python utils/prepare_checkpoint.py ${model} ${checkpoint_dir} ${checkpoint_name} |
|---|
| | | model=${checkpoint_dir}/${model} |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ $stage -le 1 ] && [ $stop_stage -ge 1 ];then |
|---|
| | | echo "Decoding ..." |
|---|
| | | gpuid_list_array=(${gpuid_list//,/ }) |
|---|
| | | for JOB in $(seq ${nj}); do |
|---|
| | | { |
|---|
| | | id=$((JOB-1)) |
|---|
| | | gpuid=${gpuid_list_array[$id]} |
|---|
| | | mkdir -p ${output_dir}/output.$JOB |
|---|
| | | python infer.py \ |
|---|
| | | --model ${model} \ |
|---|
| | | --audio_in ${output_dir}/split/wav.$JOB.scp \ |
|---|
| | | --output_dir ${output_dir}/output.$JOB \ |
|---|
| | | --batch_size ${batch_size} \ |
|---|
| | | --gpuid ${gpuid} \ |
|---|
| | | --hotword_txt ${hotword_txt} |
|---|
| | | }& |
|---|
| | | done |
|---|
| | | wait |
|---|
| | | |
|---|
| | | mkdir -p ${output_dir}/1best_recog |
|---|
| | | for f in token score text; do |
|---|
| | | if [ -f "${output_dir}/output.1/1best_recog/${f}" ]; then |
|---|
| | | for i in $(seq "${nj}"); do |
|---|
| | | cat "${output_dir}/output.${i}/1best_recog/${f}" |
|---|
| | | done | sort -k1 >"${output_dir}/1best_recog/${f}" |
|---|
| | | fi |
|---|
| | | done |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ $stage -le 2 ] && [ $stop_stage -ge 2 ];then |
|---|
| | | echo "Computing WER ..." |
|---|
| | | cp ${output_dir}/1best_recog/text ${output_dir}/1best_recog/text.proc |
|---|
| | | cp ${data_dir}/text ${output_dir}/1best_recog/text.ref |
|---|
| | | python utils/compute_wer.py ${output_dir}/1best_recog/text.ref ${output_dir}/1best_recog/text.proc ${output_dir}/1best_recog/text.cer |
|---|
| | | tail -n 3 ${output_dir}/1best_recog/text.cer |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ $stage -le 3 ] && [ $stop_stage -ge 3 ];then |
|---|
| | | echo "SpeechIO TIOBE textnorm" |
|---|
| | | echo "$0 --> Normalizing REF text ..." |
|---|
| | | ./utils/textnorm_zh.py \ |
|---|
| | | --has_key --to_upper \ |
|---|
| | | ${data_dir}/text \ |
|---|
| | | ${output_dir}/1best_recog/ref.txt |
|---|
| | | |
|---|
| | | echo "$0 --> Normalizing HYP text ..." |
|---|
| | | ./utils/textnorm_zh.py \ |
|---|
| | | --has_key --to_upper \ |
|---|
| | | ${output_dir}/1best_recog/text.proc \ |
|---|
| | | ${output_dir}/1best_recog/rec.txt |
|---|
| | | grep -v $'\t$' ${output_dir}/1best_recog/rec.txt > ${output_dir}/1best_recog/rec_non_empty.txt |
|---|
| | | |
|---|
| | | echo "$0 --> computing WER/CER and alignment ..." |
|---|
| | | ./utils/error_rate_zh \ |
|---|
| | | --tokenizer char \ |
|---|
| | | --ref ${output_dir}/1best_recog/ref.txt \ |
|---|
| | | --hyp ${output_dir}/1best_recog/rec_non_empty.txt \ |
|---|
| | | ${output_dir}/1best_recog/DETAILS.txt | tee ${output_dir}/1best_recog/RESULTS.txt |
|---|
| | | rm -rf ${output_dir}/1best_recog/rec.txt ${output_dir}/1best_recog/rec_non_empty.txt |
|---|
| | | fi |
|---|
| | | |
|---|
| New file |
| | |
|---|
| | | ../../../../egs/aishell/transformer/utils |
|---|
| New file |
| | |
|---|
| | | from modelscope.pipelines import pipeline |
|---|
| | | from modelscope.utils.constant import Tasks |
|---|
| | | |
|---|
| | | inference_pipeline = pipeline( |
|---|
| | | task=Tasks.auto_speech_recognition, |
|---|
| | | model='damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch') |
|---|
| | | |
|---|
| | | rec_result = inference_pipeline(audio_in='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav') |
|---|
| | | print(rec_result) |
|---|
| New file |
| | |
|---|
| | | ../../TEMPLATE/infer.py |
|---|
| | |
|---|
| | | batch_size=64 |
|---|
| | | gpu_inference=true # whether to perform gpu decoding |
|---|
| | | gpuid_list="0,1" # set gpus, e.g., gpuid_list="0,1" |
|---|
| | | njob=4 # the number of jobs for CPU decoding, if gpu_inference=false, use CPU decoding, please set njob |
|---|
| | | njob=64 # the number of jobs for CPU decoding, if gpu_inference=false, use CPU decoding, please set njob |
|---|
| | | checkpoint_dir= |
|---|
| | | checkpoint_name="valid.cer_ctc.ave.pb" |
|---|
| | | |
|---|
| | | . utils/parse_options.sh || exit 1; |
|---|
| | | |
|---|
| | |
|---|
| | | done |
|---|
| | | perl utils/split_scp.pl ${data_dir}/wav.scp ${split_scps} |
|---|
| | | |
|---|
| | | if [ -n "${checkpoint_dir}" ]; then |
|---|
| | | python utils/prepare_checkpoint.py ${model} ${checkpoint_dir} ${checkpoint_name} |
|---|
| | | model=${checkpoint_dir}/${model} |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ $stage -le 1 ] && [ $stop_stage -ge 1 ];then |
|---|
| | | echo "Decoding ..." |
|---|
| | | gpuid_list_array=(${gpuid_list//,/ }) |
|---|
| New file |
| | |
|---|
| | | from modelscope.pipelines import pipeline |
|---|
| | | from modelscope.utils.constant import Tasks |
|---|
| | | |
|---|
| | | decoding_mode="normal" #fast, normal, offline |
|---|
| | | inference_pipeline = pipeline( |
|---|
| | | task=Tasks.auto_speech_recognition, |
|---|
| | | model='damo/speech_UniASR_asr_2pass-minnan-16k-common-vocab3825', |
|---|
| | | param_dict={"decoding_model": decoding_mode} |
|---|
| | | ) |
|---|
| | | |
|---|
| | | rec_result = inference_pipeline(audio_in='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav') |
|---|
| | | print(rec_result) |
|---|
| New file |
| | |
|---|
| | | ../../TEMPLATE/infer.py |
|---|
| New file |
| | |
|---|
| | | #!/usr/bin/env bash |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | set -u |
|---|
| | | set -o pipefail |
|---|
| | | |
|---|
| | | stage=1 |
|---|
| | | stop_stage=2 |
|---|
| | | model="damo/speech_UniASR_asr_2pass-minnan-16k-common-vocab3825" |
|---|
| | | data_dir="./data/test" |
|---|
| | | output_dir="./results" |
|---|
| | | batch_size=1 |
|---|
| | | gpu_inference=true # whether to perform gpu decoding |
|---|
| | | gpuid_list="0,1" # set gpus, e.g., gpuid_list="0,1" |
|---|
| | | njob=64 # the number of jobs for CPU decoding, if gpu_inference=false, use CPU decoding, please set njob |
|---|
| | | checkpoint_dir= |
|---|
| | | checkpoint_name="valid.cer_ctc.ave.pb" |
|---|
| | | decoding_mode="normal" |
|---|
| | | |
|---|
| | | . utils/parse_options.sh || exit 1; |
|---|
| | | |
|---|
| | | if ${gpu_inference} == "true"; then |
|---|
| | | nj=$(echo $gpuid_list | awk -F "," '{print NF}') |
|---|
| | | else |
|---|
| | | nj=$njob |
|---|
| | | batch_size=1 |
|---|
| | | gpuid_list="" |
|---|
| | | for JOB in $(seq ${nj}); do |
|---|
| | | gpuid_list=$gpuid_list"-1," |
|---|
| | | done |
|---|
| | | fi |
|---|
| | | |
|---|
| | | mkdir -p $output_dir/split |
|---|
| | | split_scps="" |
|---|
| | | for JOB in $(seq ${nj}); do |
|---|
| | | split_scps="$split_scps $output_dir/split/wav.$JOB.scp" |
|---|
| | | done |
|---|
| | | perl utils/split_scp.pl ${data_dir}/wav.scp ${split_scps} |
|---|
| | | |
|---|
| | | if [ -n "${checkpoint_dir}" ]; then |
|---|
| | | python utils/prepare_checkpoint.py ${model} ${checkpoint_dir} ${checkpoint_name} |
|---|
| | | model=${checkpoint_dir}/${model} |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ $stage -le 1 ] && [ $stop_stage -ge 1 ];then |
|---|
| | | echo "Decoding ..." |
|---|
| | | gpuid_list_array=(${gpuid_list//,/ }) |
|---|
| | | for JOB in $(seq ${nj}); do |
|---|
| | | { |
|---|
| | | id=$((JOB-1)) |
|---|
| | | gpuid=${gpuid_list_array[$id]} |
|---|
| | | mkdir -p ${output_dir}/output.$JOB |
|---|
| | | python infer.py \ |
|---|
| | | --model ${model} \ |
|---|
| | | --audio_in ${output_dir}/split/wav.$JOB.scp \ |
|---|
| | | --output_dir ${output_dir}/output.$JOB \ |
|---|
| | | --batch_size ${batch_size} \ |
|---|
| | | --gpuid ${gpuid} \ |
|---|
| | | --decoding_mode ${decoding_mode} |
|---|
| | | }& |
|---|
| | | done |
|---|
| | | wait |
|---|
| | | |
|---|
| | | mkdir -p ${output_dir}/1best_recog |
|---|
| | | for f in token score text; do |
|---|
| | | if [ -f "${output_dir}/output.1/1best_recog/${f}" ]; then |
|---|
| | | for i in $(seq "${nj}"); do |
|---|
| | | cat "${output_dir}/output.${i}/1best_recog/${f}" |
|---|
| | | done | sort -k1 >"${output_dir}/1best_recog/${f}" |
|---|
| | | fi |
|---|
| | | done |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ $stage -le 2 ] && [ $stop_stage -ge 2 ];then |
|---|
| | | echo "Computing WER ..." |
|---|
| | | cp ${output_dir}/1best_recog/text ${output_dir}/1best_recog/text.proc |
|---|
| | | cp ${data_dir}/text ${output_dir}/1best_recog/text.ref |
|---|
| | | python utils/compute_wer.py ${output_dir}/1best_recog/text.ref ${output_dir}/1best_recog/text.proc ${output_dir}/1best_recog/text.cer |
|---|
| | | tail -n 3 ${output_dir}/1best_recog/text.cer |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ $stage -le 3 ] && [ $stop_stage -ge 3 ];then |
|---|
| | | echo "SpeechIO TIOBE textnorm" |
|---|
| | | echo "$0 --> Normalizing REF text ..." |
|---|
| | | ./utils/textnorm_zh.py \ |
|---|
| | | --has_key --to_upper \ |
|---|
| | | ${data_dir}/text \ |
|---|
| | | ${output_dir}/1best_recog/ref.txt |
|---|
| | | |
|---|
| | | echo "$0 --> Normalizing HYP text ..." |
|---|
| | | ./utils/textnorm_zh.py \ |
|---|
| | | --has_key --to_upper \ |
|---|
| | | ${output_dir}/1best_recog/text.proc \ |
|---|
| | | ${output_dir}/1best_recog/rec.txt |
|---|
| | | grep -v $'\t$' ${output_dir}/1best_recog/rec.txt > ${output_dir}/1best_recog/rec_non_empty.txt |
|---|
| | | |
|---|
| | | echo "$0 --> computing WER/CER and alignment ..." |
|---|
| | | ./utils/error_rate_zh \ |
|---|
| | | --tokenizer char \ |
|---|
| | | --ref ${output_dir}/1best_recog/ref.txt \ |
|---|
| | | --hyp ${output_dir}/1best_recog/rec_non_empty.txt \ |
|---|
| | | ${output_dir}/1best_recog/DETAILS.txt | tee ${output_dir}/1best_recog/RESULTS.txt |
|---|
| | | rm -rf ${output_dir}/1best_recog/rec.txt ${output_dir}/1best_recog/rec_non_empty.txt |
|---|
| | | fi |
|---|
| | | |
|---|
| New file |
| | |
|---|
| | | ../../../../egs/aishell/transformer/utils |
|---|
| | |
|---|
| | | return word_list |
|---|
| | | |
|---|
| | | def seg_tokenize(txt, seg_dict): |
|---|
| | | pattern = re.compile(r'^[\u4E00-\u9FA50-9]+$') |
|---|
| | | out_txt = "" |
|---|
| | | for word in txt: |
|---|
| | | word = word.lower() |
|---|
| | | if word in seg_dict: |
|---|
| | | out_txt += seg_dict[word] + " " |
|---|
| | | else: |
|---|
| | | if pattern.match(word): |
|---|
| | | for char in word: |
|---|
| | | if char in seg_dict: |
|---|
| | | out_txt += seg_dict[char] + " " |
|---|
| | | else: |
|---|
| | | out_txt += "<unk>" + " " |
|---|
| | | else: |
|---|
| | | out_txt += "<unk>" + " " |
|---|
| | | return out_txt.strip().split() |
|---|
| | | |
|---|
| | |
|---|
| | | i += len(longest_word) |
|---|
| | | return word_list |
|---|
| | | |
|---|
| | | |
|---|
| | | def seg_tokenize(txt, seg_dict): |
|---|
| | | pattern = re.compile(r'^[\u4E00-\u9FA50-9]+$') |
|---|
| | | out_txt = "" |
|---|
| | | for word in txt: |
|---|
| | | word = word.lower() |
|---|
| | | if word in seg_dict: |
|---|
| | | out_txt += seg_dict[word] + " " |
|---|
| | | else: |
|---|
| | | if pattern.match(word): |
|---|
| | | for char in word: |
|---|
| | | if char in seg_dict: |
|---|
| | | out_txt += seg_dict[char] + " " |
|---|
| | | else: |
|---|
| | | out_txt += "<unk>" + " " |
|---|
| | | else: |
|---|
| | | out_txt += "<unk>" + " " |
|---|
| | | return out_txt.strip().split() |
|---|
| | | |
|---|



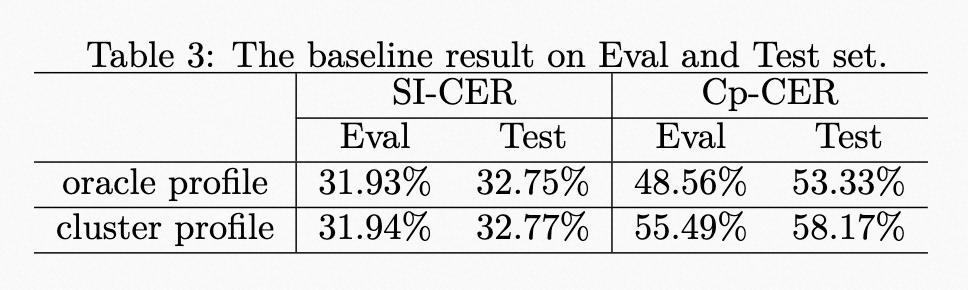





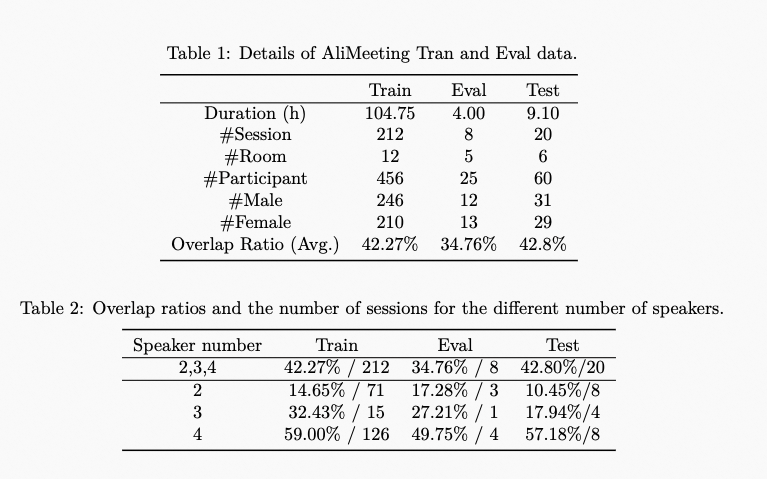











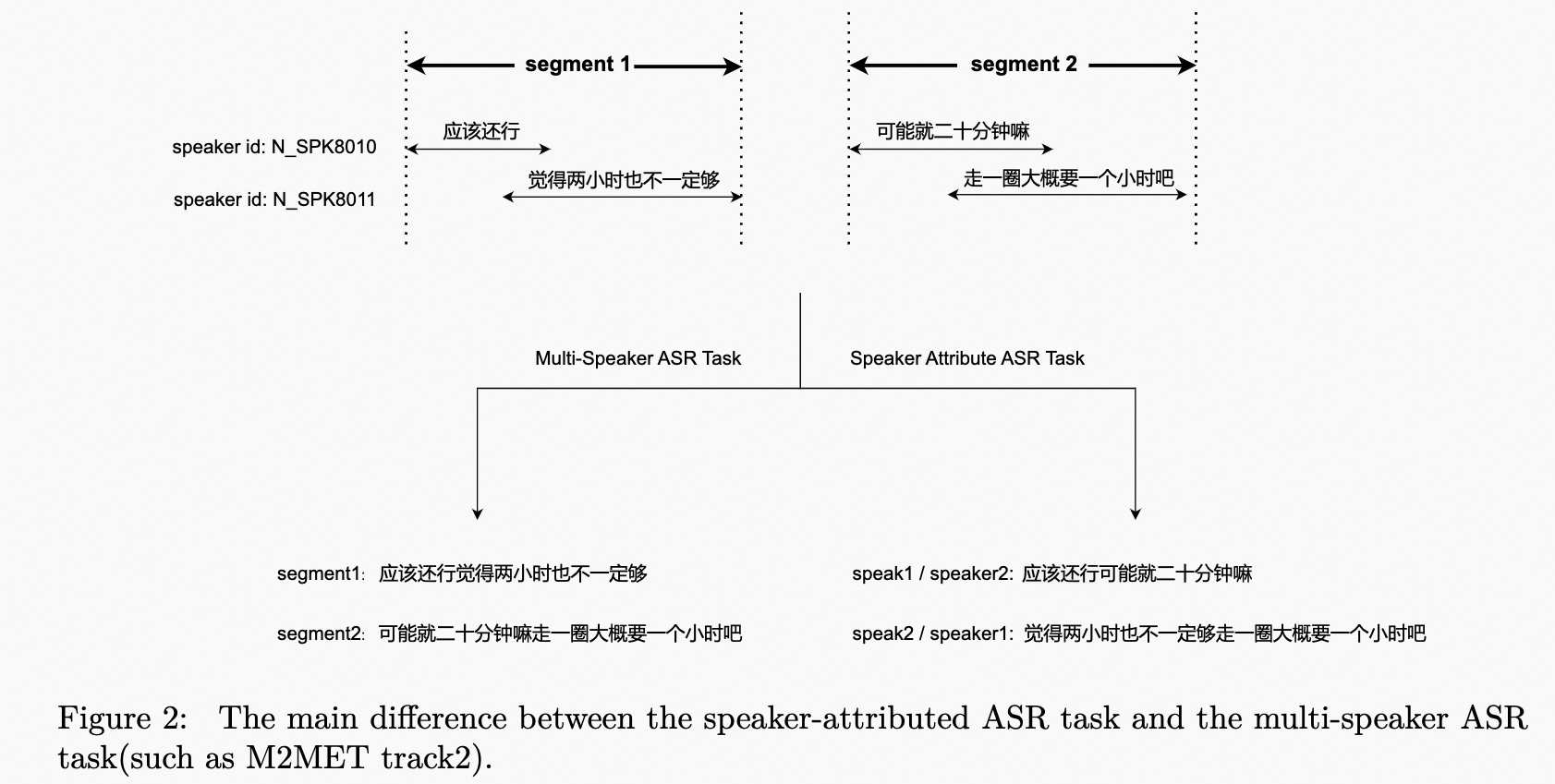













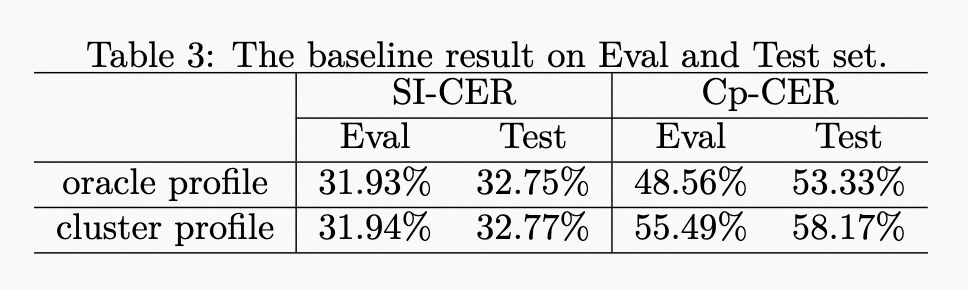





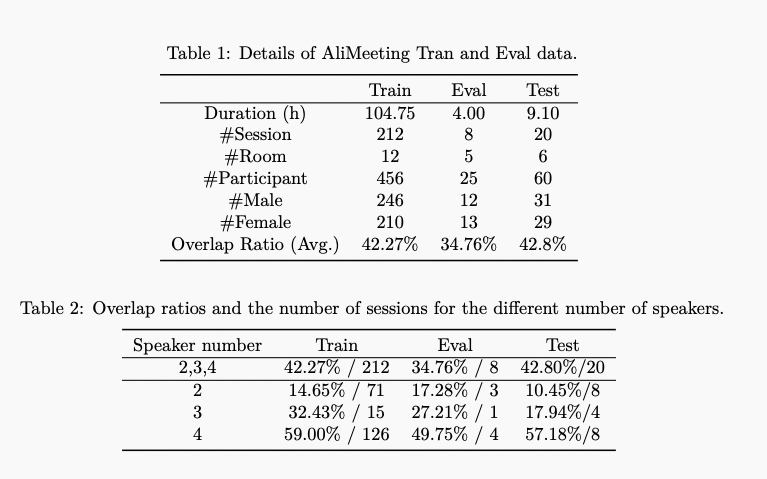



































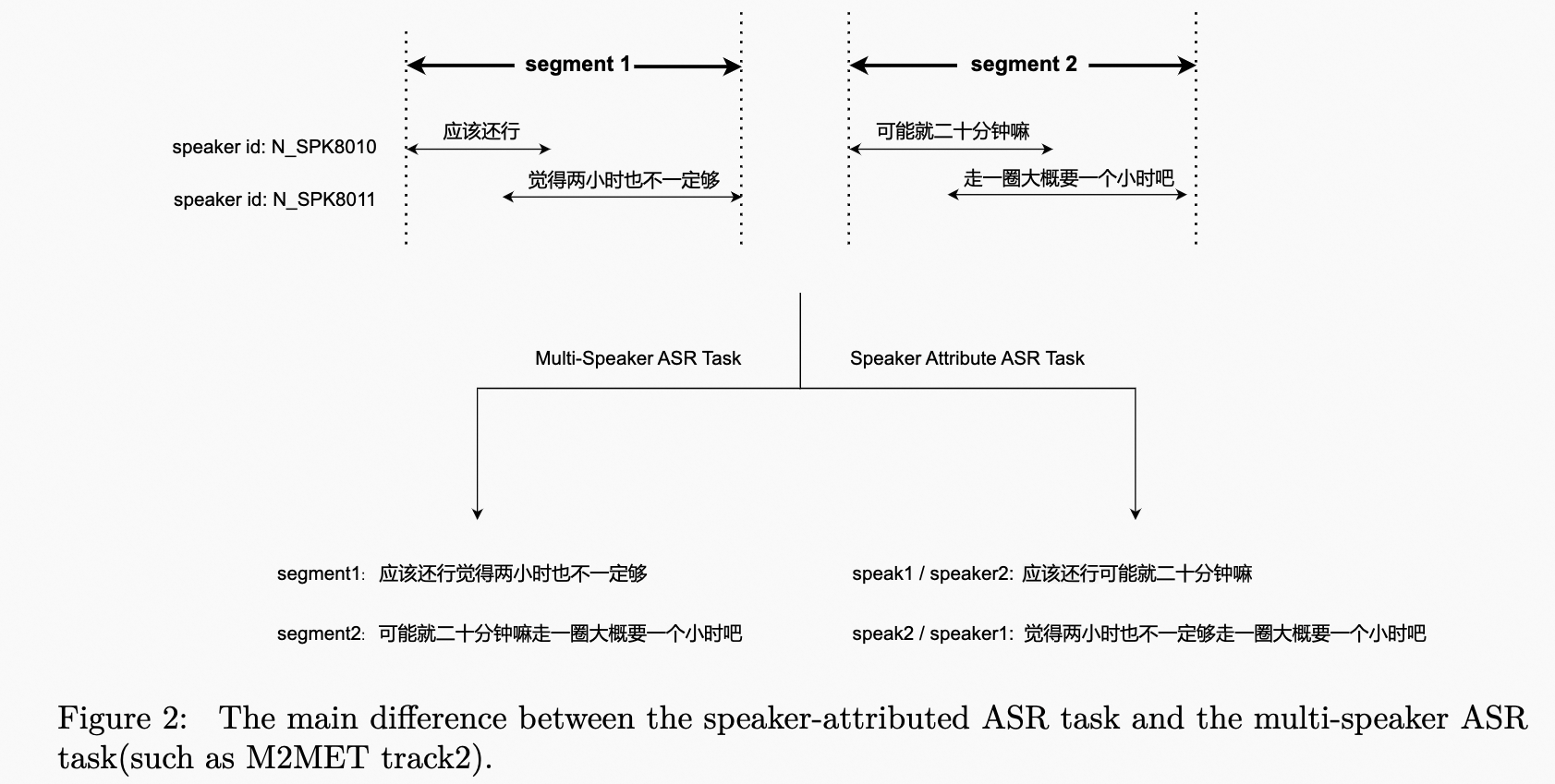
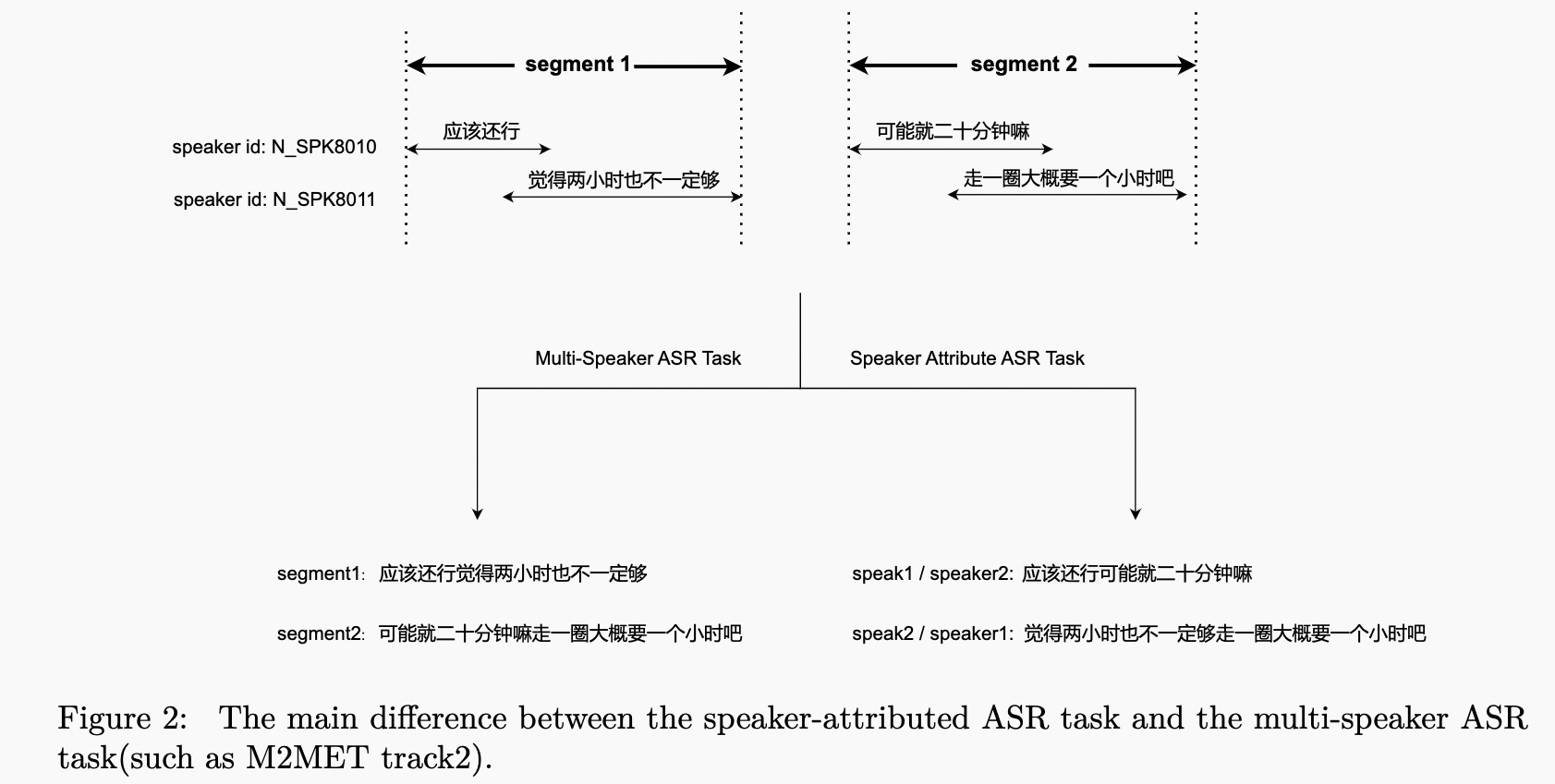













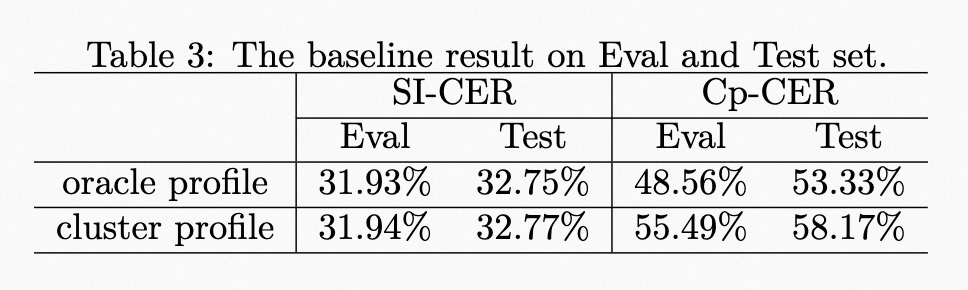







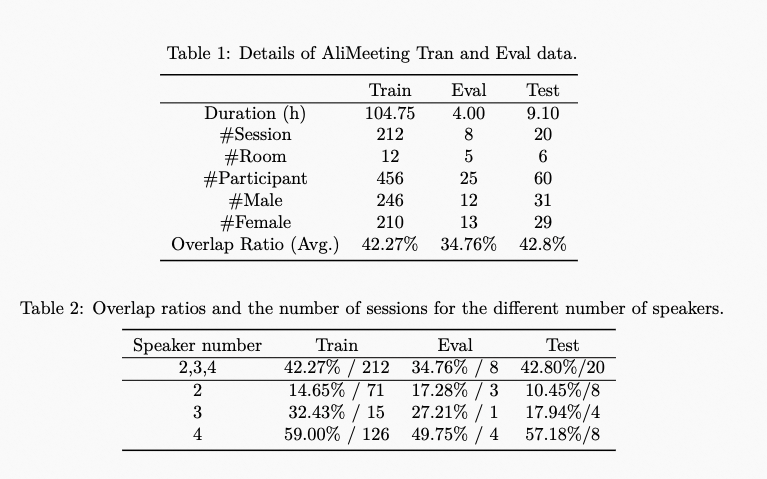











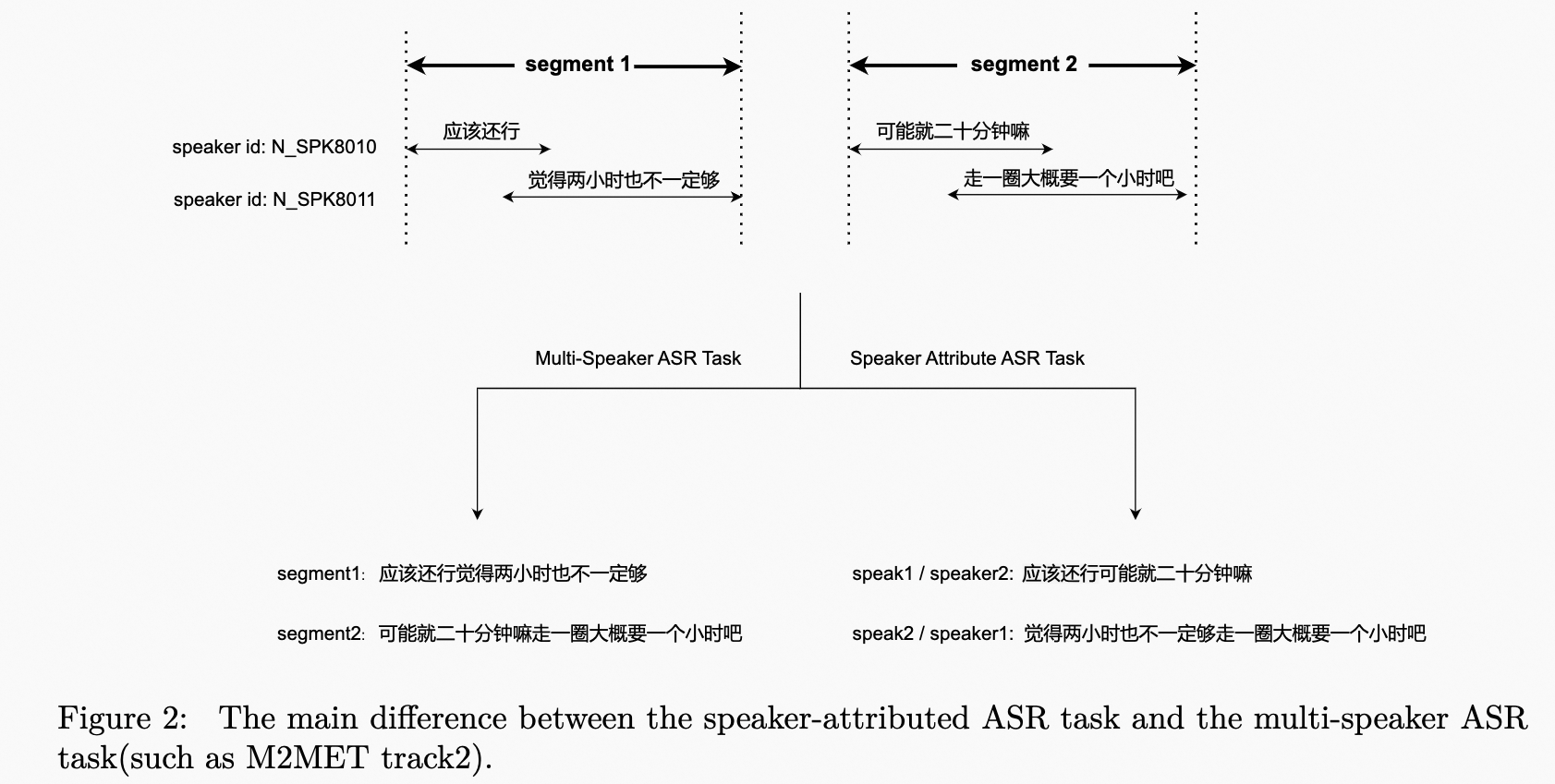






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}