add m2met2 docs cn version
| | |
|---|
| | | - uses: ammaraskar/sphinx-action@master |
|---|
| | | with: |
|---|
| | | docs-folder: "docs_m2met2/" |
|---|
| | | pre-build-command: "pip install jinja2 sphinx_rtd_theme myst_parser" |
|---|
| | | pre-build-command: "pip install jinja2 sphinx_rtd_theme myst-parser" |
|---|
| | | |
|---|
| | | - name: deploy copy |
|---|
| | | if: github.ref == 'refs/heads/main' || github.ref == 'refs/heads/dev_wjm' || github.ref == 'refs/heads/dev_lyh' |
|---|
| | |
|---|
| | | # Baseline |
|---|
| | | ## Overview |
|---|
| | | We provide an end-to-end sa-asr baseline conducted on [FunASR](https://github.com/alibaba-damo-academy/FunASR) as a receipe. The model architecture is shown in Figure 3. The SpeakerEncoder is initialized with a pre-trained [speaker verification model](https://modelscope.cn/models/damo/speech_xvector_sv-zh-cn-cnceleb-16k-spk3465-pytorch/summary) from [ModelScope](https://modelscope.cn/home). This speaker verification model is also be used to extract the speaker embedding in the speaker profile. |
|---|
| | | We provide an end-to-end sa-asr baseline conducted on [FunASR](https://github.com/alibaba-damo-academy/FunASR) as a receipe. The model architecture is shown in Figure 2. The SpeakerEncoder is initialized with a pre-trained [speaker verification model](https://modelscope.cn/models/damo/speech_xvector_sv-zh-cn-cnceleb-16k-spk3465-pytorch/summary) from [ModelScope](https://modelscope.cn/home). This speaker verification model is also be used to extract the speaker embedding in the speaker profile. |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| | |
|---|
| | | |
|---|
| | | ## Guidelines |
|---|
| | | |
|---|
| | | Potential participants from both academia and industry should send an email to **m2met.alimeeting@gmail.com** to register to the challenge before or by May 5 with the following requirements: |
|---|
| | | Potential participants from both academia and industry should send an email to **m2met.alimeeting@gmail.com** to register to the challenge before or by May 5, 2023 with the following requirements: |
|---|
| | | |
|---|
| | | |
|---|
| | | - Email subject: [ASRU2023 M2MeT2.0 Challenge Registration] â Team Name - Participating |
|---|
| | |
|---|
| | | ================================================================================== |
|---|
| | | Building on the success of the M2MeT challenge, we are pleased to announce the M2MeT2.0 challenge as an ASRU2023 Signal Processing Grand Challenge. |
|---|
| | | To further advance the current multi-talker ASR system to practicality, the M2MeT2.0 challenge proposes the speaker-attribute ASR task with two sub-tracks performing in fixed and open training conditions. |
|---|
| | | We provide a detailed introduction of the dataset, rules, evaluation methods, and baseline systems to further promote reproducible research in this field. |
|---|
| | | We provide a detailed introduction of the dataset, rules, baseline systems, and evaluation methods to further promote reproducible research in this field. |
|---|
| | | |
|---|
| | | .. toctree:: |
|---|
| | | :maxdepth: 1 |
|---|
| New file |
| | |
|---|
| | | # Minimal makefile for Sphinx documentation |
|---|
| | | # |
|---|
| | | |
|---|
| | | # You can set these variables from the command line, and also |
|---|
| | | # from the environment for the first two. |
|---|
| | | SPHINXOPTS ?= |
|---|
| | | SPHINXBUILD ?= sphinx-build |
|---|
| | | SOURCEDIR = . |
|---|
| | | BUILDDIR = _build |
|---|
| | | |
|---|
| | | # Put it first so that "make" without argument is like "make help". |
|---|
| | | help: |
|---|
| | | @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O) |
|---|
| | | |
|---|
| | | .PHONY: help Makefile |
|---|
| | | |
|---|
| | | # Catch-all target: route all unknown targets to Sphinx using the new |
|---|
| | | # "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS). |
|---|
| | | %: Makefile |
|---|
| | | @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O) |
|---|
| New file |
| | |
|---|
| | | # Configuration file for the Sphinx documentation builder. |
|---|
| | | # |
|---|
| | | # For the full list of built-in configuration values, see the documentation: |
|---|
| | | # https://www.sphinx-doc.org/en/master/usage/configuration.html |
|---|
| | | |
|---|
| | | # -- Project information ----------------------------------------------------- |
|---|
| | | # https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information |
|---|
| | | |
|---|
| | | project = 'm2met2' |
|---|
| | | copyright = '2023, Speech Lab, Alibaba Group; Audio, Speech and Language Processing Group, Northwestern Polytechnical University' |
|---|
| | | author = 'Speech Lab, Alibaba Group; Audio, Speech and Language Processing Group, Northwestern Polytechnical University' |
|---|
| | | |
|---|
| | | # -- General configuration --------------------------------------------------- |
|---|
| | | # https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration |
|---|
| | | extensions = [ |
|---|
| | | 'myst_parser', |
|---|
| | | 'sphinx_rtd_theme', |
|---|
| | | ] |
|---|
| | | |
|---|
| | | myst_enable_extensions = [ |
|---|
| | | "colon_fence", |
|---|
| | | "deflist", |
|---|
| | | "dollarmath", |
|---|
| | | ] |
|---|
| | | |
|---|
| | | myst_heading_anchors = 2 |
|---|
| | | myst_highlight_code_blocks=True |
|---|
| | | myst_update_mathjax=False |
|---|
| | | templates_path = ['_templates'] |
|---|
| | | exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store'] |
|---|
| | | |
|---|
| | | language = 'zh_CN' |
|---|
| | | |
|---|
| | | # -- Options for HTML output ------------------------------------------------- |
|---|
| | | # https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output |
|---|
| | | |
|---|
| | | html_theme = 'sphinx_rtd_theme' |
|---|
| | | html_static_path = ['_static'] |
|---|
| | | |
|---|
| New file |
| | |
|---|
| | | .. m2met2 documentation master file, created by |
|---|
| | | sphinx-quickstart on Wed Apr 12 17:49:45 2023. |
|---|
| | | You can adapt this file completely to your liking, but it should at least |
|---|
| | | contain the root `toctree` directive. |
|---|
| | | |
|---|
| | | ASRU 2023 å¤ééå¤æ¹ä¼è®®è½¬å½ææ 2.0 |
|---|
| | | ================================================================================== |
|---|
| | | å¨ä¸ä¸å±M2METæå举åçåºç¡ä¸ï¼æ们å°å¨ASRU2023ä¸ç»§ç»ä¸¾åM2MET2.0ææèµã |
|---|
| | | 为äºå°ç°å¨çå¤è¯´è¯äººè¯é³è¯å«ç³»ç»æ¨åå®ç¨åï¼M2MET2.0ææèµå°å¨è¯´è¯äººç¸å
³ç人ç©ä¸è¯ä¼°ï¼å¹¶ä¸åæ¶è®¾ç«éå®æ°æ®ä¸ä¸éå®æ°æ®ä¸¤ä¸ªåèµéã |
|---|
| | | æ们对æ°æ®éãè§åãåºçº¿ç³»ç»åè¯ä¼°æ¹æ³è¿è¡äºè¯¦ç»ä»ç»ï¼ä»¥è¿ä¸æ¥ä¿è¿å¤è¯´è¯äººè¯é³è¯å«é¢åç 究çåå±ã |
|---|
| | | |
|---|
| | | .. toctree:: |
|---|
| | | :maxdepth: 1 |
|---|
| | | :caption: ç®å½: |
|---|
| | | |
|---|
| | | ./ç®ä» |
|---|
| | | ./æ°æ®é |
|---|
| | | ./èµé设置ä¸è¯ä¼° |
|---|
| | | ./åºçº¿ |
|---|
| | | ./è§å |
|---|
| | | ./ç»å§ä¼ |
|---|
| | | |
|---|
| | | Indices and tables |
|---|
| | | ================== |
|---|
| | | |
|---|
| | | * :ref:`genindex` |
|---|
| | | * :ref:`modindex` |
|---|
| | | * :ref:`search` |
|---|
| New file |
| | |
|---|
| | | @ECHO OFF
|
|---|
| | |
|
|---|
| | | pushd %~dp0
|
|---|
| | |
|
|---|
| | | REM Command file for Sphinx documentation
|
|---|
| | |
|
|---|
| | | if "%SPHINXBUILD%" == "" (
|
|---|
| | | set SPHINXBUILD=sphinx-build
|
|---|
| | | )
|
|---|
| | | set SOURCEDIR=.
|
|---|
| | | set BUILDDIR=_build
|
|---|
| | |
|
|---|
| | | %SPHINXBUILD% >NUL 2>NUL
|
|---|
| | | if errorlevel 9009 (
|
|---|
| | | echo.
|
|---|
| | | echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
|
|---|
| | | echo.installed, then set the SPHINXBUILD environment variable to point
|
|---|
| | | echo.to the full path of the 'sphinx-build' executable. Alternatively you
|
|---|
| | | echo.may add the Sphinx directory to PATH.
|
|---|
| | | echo.
|
|---|
| | | echo.If you don't have Sphinx installed, grab it from
|
|---|
| | | echo.https://www.sphinx-doc.org/
|
|---|
| | | exit /b 1
|
|---|
| | | )
|
|---|
| | |
|
|---|
| | | if "%1" == "" goto help
|
|---|
| | |
|
|---|
| | | %SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
|---|
| | | goto end
|
|---|
| | |
|
|---|
| | | :help
|
|---|
| | | %SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
|---|
| | |
|
|---|
| | | :end
|
|---|
| | | popd
|
|---|
| New file |
| | |
|---|
| | | # åºçº¿ |
|---|
| | | ## åºçº¿æ¦è¿° |
|---|
| | | æ们æä¾ä¸ä¸ªå¨[FunASR](https://github.com/alibaba-damo-academy/FunASR)ä¸å®ç°ç端å°ç«¯SA-ASRç³»ç»ä½ä¸ºåºçº¿ã该模åçç»æå¦å¾3æ示ãSpeakerEncoderç¨[ModelScope](https://modelscope.cn/home)ä¸é¢å
è®ç»å¥½ç[说è¯äººç¡®è®¤æ¨¡å](https://modelscope.cn/models/damo/speech_xvector_sv-zh-cn-cnceleb-16k-spk3465-pytorch/summary)ä½ä¸ºåå§åãè¿ä¸ªè¯´è¯äººç¡®è®¤æ¨¡åä¹è¢«ç¨æ¥æå说è¯äººæ¡£æ¡ä¸ç说è¯äººåµå
¥ã |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| | | ## å¿«éå¼å§ |
|---|
| | | #TODO: fill with the README.md of the baseline |
|---|
| | | |
|---|
| | | ## åºçº¿ç»æ |
|---|
| | | åºçº¿ç³»ç»çç»æå¦è¡¨3æ示ãå¨è®ç»æé´ï¼è¯´è¯äººæ¡£æ¡éç¨äºçå®è¯´è¯äººåµå
¥ãç¶èç±äºå¨è¯ä¼°è¿ç¨ä¸ç¼ºä¹çå®è¯´è¯äººæ ç¾ï¼å æ¤ä½¿ç¨äºç±é¢å¤çè°±èç±»æä¾ç说è¯äººç¹å¾ãåæ¶æ们è¿æä¾äºå¨è¯ä¼°åæµè¯éä¸ä½¿ç¨çå®è¯´è¯äººæ¡£æ¡çç»æï¼ä»¥æ¾ç¤ºè¯´è¯äººæ¡£æ¡åç¡®æ§çå½±åã |
|---|
| | |  |
|---|
| New file |
| | |
|---|
| | | # æ°æ®é |
|---|
| | | ## æ°æ®éæ¦è¿° |
|---|
| | | å¨éå®æ°æ®éæ¡ä»¶ä¸ï¼è®ç»æ°æ®éä»
éäºä¸ä¸ªå
¬å¼çè¯æåºï¼å³AliMeetingãAISHELL-4åCN-Celebã为äºè¯ä¼°åèµè
æ交ç模åçæ§è½ï¼æ们å°åå¸ä¸ä¸ªæ°çæµè¯éï¼Test-2023ï¼ç¨äºæååæåãä¸é¢æ们å°è¯¦ç»æè¿°AliMeetingæ°æ®éåTest-2023æµè¯éã |
|---|
| | | |
|---|
| | | ## Alimeetingæ°æ®éä»ç» |
|---|
| | | AliMeetingæ»å
±å
å«118.75å°æ¶çè¯é³æ°æ®ï¼å
æ¬104.75å°æ¶çè®ç»éï¼Trainï¼ã4å°æ¶çéªè¯éï¼Evalï¼å10å°æ¶çæµè¯éï¼Testï¼ãè®ç»éåéªè¯éåå«å
å«212åºå8åºä¼è®®ï¼å
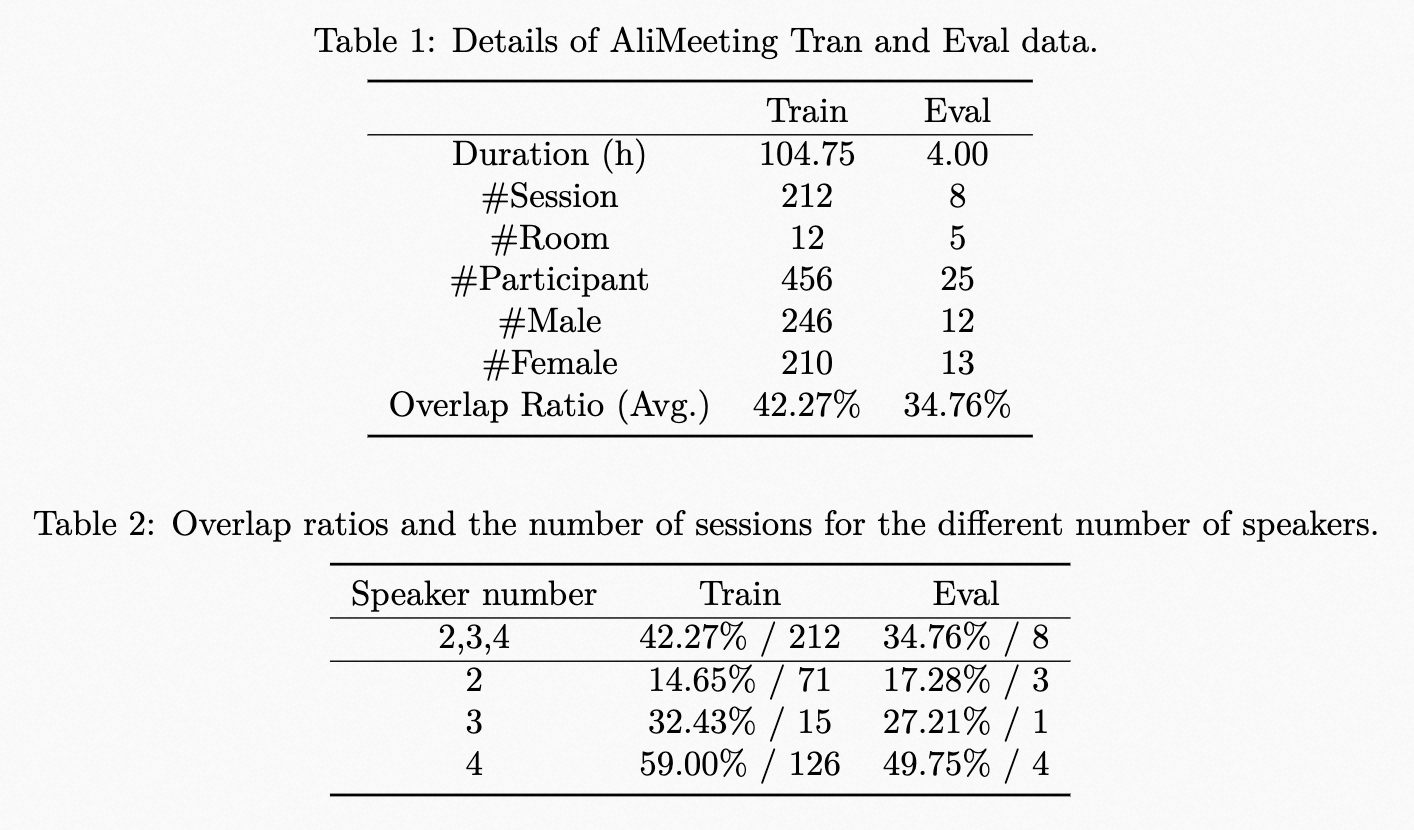
¶ä¸æ¯åºä¼è®®ç±å¤ä¸ªè¯´è¯äººè¿è¡15å°30åéç讨论ãè®ç»åéªè¯éä¸åä¸ä¼è®®çæ»äººæ°åå«ä¸º456人å25人ï¼å¹¶ä¸åä¼çç·å¥³æ¯ä¾äººæ°åè¡¡ã |
|---|
| | | |
|---|
| | | 该æ°æ®éæ¶éäº13个ä¸åçä¼è®®å®¤ï¼æç
§å¤§å°è§æ ¼å为å°åãä¸åå大åä¸ç§ï¼æ¿é´é¢ç§¯ä»8å°55å¹³æ¹ç±³ä¸çãä¸åæ¿é´å
·æä¸åçå¸å±å声å¦ç¹æ§ï¼æ¯ä¸ªæ¿é´ç详ç»åæ°ä¹å°åéç»åä¸è
ãä¼è®®åºå°çå¢ä½ææç±»åå
æ¬æ°´æ³¥ãç»ççãä¼è®®åºå°ç家å
·å
æ¬æ²åãçµè§ãé»æ¿ãé£æã空è°ãæ¤ç©çãå¨å½å¶è¿ç¨ä¸ï¼éº¦å
é£éµåæ¾ç½®äºæ¡ä¸ï¼å¤ä¸ªè¯´è¯äººå´åå¨æ¡è¾¹è¿è¡èªç¶å¯¹è¯ã麦å
é£éµå离说è¯äººè·ç¦»çº¦0.3å°5.0ç±³ä¹é´ãææ说è¯äººçæ¯è¯åæ¯æ±è¯ï¼å¹¶ä¸è¯´çé½æ¯æ®éè¯ï¼æ²¡ææµéçå£é³ãå¨ä¼è®®å½å¶æé´å¯è½ä¼äº§çåç§å®¤å
çåªé³ï¼å
æ¬é®ç声ãå¼é¨/å
³é¨å£°ãé£æ声ãæ°æ³¡å£°çãææ说è¯äººå¨ä¼è®®çå½å¶æé´åä¿æç¸åä½ç½®ï¼ä¸åçèµ°å¨ãè®ç»éåéªè¯éç说è¯äººæ²¡æéå¤ãå¾1å±ç¤ºäºä¸ä¸ªä¼è®®å®¤çå¸å±ä»¥å麦å
é£çææç»æã |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| | | æ¯åºä¼è®®ç说è¯äººæ°éä»2å°4人ä¸çãåæ¶ä¸ºäºè¦çåç§å
容çä¼è®®åºæ¯ï¼æ们éæ©äºå¤ç§ä¼è®®ä¸»é¢ï¼å
æ¬å»çãæè²ãåä¸ãç»ç»ç®¡çãå·¥ä¸ç产çä¸åå
容çä¾ä¼ãè®ç»éåéªè¯éçå¹³åè¯é³éå çåå«ä¸º42.27\%å34.76\%ãAliMeetingè®ç»éåéªè¯éç详ç»ä¿¡æ¯è§è¡¨1ã表2æ¾ç¤ºäºè®ç»éåéªè¯éä¸ä¸ååè¨è
人æ°ä¼è®®çè¯é³éå çåä¼è®®æ°éã |
|---|
| | | |
|---|
| | |  |
|---|
| | | Test-2023æµè¯éç±20åºä¼è®®ç»æï¼è¿äºä¼è®®æ¯å¨ä¸AliMeetingæ°æ®éç¸åç声å¦ç¯å¢ä¸å½å¶çãTest-2023æµè¯éä¸çæ¯ä¸ªä¼è®®ç¯èç±2å°4个åä¸è
ç»æ并ä¸ä¸AliMeetingæµè¯éçé
ç½®ç¸ä¼¼ã |
|---|
| | | |
|---|
| | | æ们è¿ä½¿ç¨è³æºéº¦å
é£è®°å½äºæ¯ä¸ªè¯´è¯äººçè¿åºé³é¢ä¿¡å·ï¼å¹¶ç¡®ä¿åªè½¬å½å¯¹åºè¯´è¯äººèªå·±çè¯é³ãéè¦æ³¨æçæ¯ï¼éº¦å
é£éµåè®°å½çè¿åºé³é¢åè³æºéº¦å
é£è®°å½çè¿åºé³é¢å¨æ¶é´ä¸æ¯åæ¥çãæ¯åºä¼è®®çææææ¬å以TextGridæ ¼å¼åå¨ï¼å
容å
æ¬ä¼è®®çæ¶é¿ã说è¯äººä¿¡æ¯ï¼è¯´è¯äººæ°éã说è¯äººIDãæ§å«çï¼ãæ¯ä¸ªè¯´è¯äººçç段æ»æ°ãæ¯ä¸ªç段çæ¶é´æ³å转å½å
容ã |
|---|
| | | |
|---|
| | | |
|---|
| | | ## è·åæ°æ® |
|---|
| | | 以ä¸æå°çä¸ä¸ªè®ç»éåå¯ä»¥å¨[OpenSLR](https://openslr.org/resources.php)ä¸è½½. åèµè
å¯ä»¥ä½¿ç¨ä¸æ¹é¾æ¥ç´æ¥ä¸è½½. é对AliMeetingæ°æ®éï¼æ¯èµæä¾çbaselineä¸å
å«äºå®æ´çæ°æ®å¤çæµç¨ã |
|---|
| | | - [AliMeeting](https://openslr.org/119/) |
|---|
| | | - [AISHELL-4](https://openslr.org/111/) |
|---|
| | | - [CN-Celeb](https://openslr.org/82/) |
|---|
| New file |
| | |
|---|
| | | # ç®ä» |
|---|
| | | ## ç«èµä»ç» |
|---|
| | | è¯é³è¯å«ï¼Automatic Speech Recognitionï¼ã说è¯äººæ¥å¿ï¼Speaker Diarizationï¼çè¯é³å¤çææ¯çææ°åå±æ¿åäºä¼å¤æºè½è¯é³ç广æ³åºç¨ãä¼è®®åºæ¯æ¯è¯é³ææ¯åºç¨ä¸ææä»·å¼ãåæ¶ä¹æ¯æå
·æææ§çåºæ¯ä¹ä¸ãå 为è¿æ ·çåºæ¯å
å«äºä¸°å¯ç讲è¯é£æ ¼åå¤æç声å¦æ¡ä»¶ï¼éè¦èèå°éå è¯é³ãæ°éæªç¥ç说è¯äººã大åä¼è®®å®¤ä¸çè¿åºä¿¡å·ãåªé³åæ··åçææã |
|---|
| | | |
|---|
| | | 为äºæ¨å¨ä¼è®®åºæ¯è¯é³è¯å«çåå±ï¼å·²ç»æå¾å¤ç¸å
³çææèµï¼å¦ Rich Transcription evaluation å CHIMEï¼Computational Hearing in Multisource Environmentsï¼ ææèµãç¶èä¸åè¯è¨ä¹é´çå·®å¼éå¶äºéè±è¯ä¼è®®è½¬å½çè¿å±ãMISPï¼Multimodal Information Based Speech Processingï¼åM2MeTï¼Multi-Channel Multi-Party Meeting Transcriptionï¼ææèµä¸ºæ¨å¨æ®éè¯ä¼è®®åºæ¯è¯é³è¯å«ååºäºè´¡ç®ãMISPææèµä¾§éäºç¨è§å¬å¤æ¨¡æçæ¹æ³è§£å³æ¥å¸¸å®¶åºç¯å¢ä¸çè¿è·ç¦»å¤éº¦å
é£ä¿¡å·å¤çé®é¢ï¼èM2MeTææå侧éäºè§£å³ç¦»çº¿ä¼è®®å®¤ä¸ä¼è®®è½¬å½çè¯é³éå é®é¢ã |
|---|
| | | |
|---|
| | | å¨ä¸ä¸å±M2METæå举åçåºç¡ä¸ï¼æ们å°å¨ASRU2023ä¸ç»§ç»ä¸¾åM2MET2.0ææèµãå¨ä¸ä¸å±M2METææèµä¸ï¼è¯ä¼°ææ æ¯è¯´è¯äººæ å
³çï¼æ们åªè½å¾å°è¯å«ææ¬ï¼èä¸è½ç¡®å®ç¸åºç说è¯äººã |
|---|
| | | 为äºå°ç°å¨çå¤è¯´è¯äººè¯é³è¯å«ç³»ç»æ¨åå®ç¨åï¼M2MET2.0ææèµå°å¨è¯´è¯äººç¸å
³ç人ç©ä¸è¯ä¼°ï¼å¹¶ä¸åæ¶è®¾ç«éå®æ°æ®ä¸ä¸éå®æ°æ®ä¸¤ä¸ªåèµéã |
|---|
| | | æ们对æ°æ®éãè§åãåºçº¿ç³»ç»åè¯ä¼°æ¹æ³è¿è¡äºè¯¦ç»ä»ç»ï¼ä»¥è¿ä¸æ¥ä¿è¿å¤è¯´è¯äººè¯é³è¯å«é¢åç 究çåå±ã主åæ¹å°éæ©åä¸å论æ并å°å
¶çº³å
¥ASRU2023论æéã |
|---|
| | | |
|---|
| | | |
|---|
| | | ## æ¶é´å®æ(AOEæ¶é´) |
|---|
| | | |
|---|
| | | - $ 2023.5.5: $ åèµè
注åæªæ¢ |
|---|
| | | - $ 2023.6.9: $ æµè¯éæ°æ®åå¸ |
|---|
| | | - $ 2023.6.13: $ æç»ç»ææ交æªæ¢ |
|---|
| | | - $ 2023.6.19: $ è¯ä¼°ç»æåæååå¸ |
|---|
| | | - $ 2023.7.3: $ 论ææ交æªæ¢ |
|---|
| | | - $ 2023.7.10: $ æç»ç论ææ交æªæ¢ |
|---|
| | | |
|---|
| | | ## ç«èµæ¥å |
|---|
| | | |
|---|
| | | æ¥èªå¦æ¯çåå·¥ä¸ççææååèµè
ååºå¨2023å¹´5æ5æ¥åå **m2met.alimeeting@gmail.com** åéé®ä»¶ï¼æç
§ä»¥ä¸è¦æ±æ³¨ååå ææèµï¼ |
|---|
| | | - 主é¢: [ICASSP2022 M2MeT2.0 Challenge Registration] â å¢éåï¼è±ææè
æ¼é³ï¼- åä¸çåèµéï¼ |
|---|
| | | - æä¾å¢éå称ãé¶å±å
³ç³»ãåä¸çèµéãå¢ééé¿ä»¥åè系人信æ¯ï¼å¢é人æ°ä¸éå®ï¼ï¼ |
|---|
| | | |
|---|
| | | 主åæ¹å°å¨3个工ä½æ¥å
éè¿çµåé®ä»¶éç¥ç¬¦åæ¡ä»¶çåèµå¢éï¼å¢éå¿
é¡»éµå®å°å¨ææç½ç«ä¸åå¸çææè§åã |
|---|
| New file |
| | |
|---|
| | | # ç«èµè§å |
|---|
| | | ææåèµè
é½åºéµå®ä»¥ä¸è§å: |
|---|
| | | |
|---|
| | | - å
许å¨åå§è®ç»æ°æ®éä¸è¿è¡æ°æ®å¢å¼ºï¼å
æ¬ä½ä¸éäºæ·»å åªå£°ææ··åãé度æ°å¨åé³è°ååã |
|---|
| | | |
|---|
| | | - ä¸¥æ ¼ç¦æ¢ä»¥ä»»ä½å½¢å¼ä½¿ç¨æµè¯æ°æ®éï¼å
æ¬ä½ä¸éäºä½¿ç¨æµè¯æ°æ®éå¾®è°æè®ç»æ¨¡åã |
|---|
| | | |
|---|
| | | - å
许å¤ç³»ç»èåï¼ä½ä¸é¼å±ä½¿ç¨å
·æç¸åç»æä»
åæ°ä¸åçåç³»ç»èåã |
|---|
| | | |
|---|
| | | - å¦æ两个系ç»çæµè¯cpCERç¸åï¼å计ç®å¤æ度è¾ä½çç³»ç»å°è¢«è®¤å®ä¸ºæ´ä¼ã |
|---|
| | | |
|---|
| | | - å¦æ使ç¨å¼ºå¶å¯¹é½æ¨¡åè·å¾äºé帧åç±»æ ç¾ï¼åå¿
须使ç¨ç¸åºåèµéå
许çæ°æ®å¯¹å¼ºå¶å¯¹é½æ¨¡åè¿è¡è®ç»ã |
|---|
| | | |
|---|
| | | - 端å°ç«¯æ¹æ³ä¸å
许使ç¨æµ
å±èåè¯è¨æ¨¡åï¼æ¨¡åå¯ä»¥éæ©LASãRNNTåTransformerçï¼ä½æµ
å±èåè¯è¨æ¨¡åçè®ç»æ°æ®åªè½æ¥èªäºå
许çè®ç»æ°æ®éç转å½ææ¬ã |
|---|
| | | |
|---|
| | | - æç»è§£éæå±äºä¸»åæ¹ãå¦éç¹æ®æ
åµï¼ä¸»åæ¹å°åè°è§£éã |
|---|
| New file |
| | |
|---|
| | | # èµé设置ä¸è¯ä¼° |
|---|
| | | ## 说è¯äººç¸å
³çè¯é³è¯å« (主èµé) |
|---|
| | | 说è¯äººç¸å
³çASRä»»å¡éè¦ä»éå çè¯é³ä¸è¯å«æ¯ä¸ªè¯´è¯äººçè¯é³ï¼å¹¶ä¸ºè¯å«å
容åé
ä¸ä¸ªè¯´è¯äººæ ç¾ãå¨æ¬æ¬¡ç«èµä¸AliMeetingãAishell4åCn-Celebæ°æ®éå¯ä½ä¸ºåéæ°æ®æºãå¨M2MeTææèµä¸ä½¿ç¨çAliMeetingæ°æ®éå
å«è®ç»ãè¯ä¼°åæµè¯éï¼å¨M2MET2.0å¯ä»¥å¨è®ç»åè¯ä¼°ä¸ä½¿ç¨ãæ¤å¤ï¼ä¸ä¸ªå
å«çº¦10å°æ¶ä¼è®®æ°æ®çæ°çTest-2023éå°æ ¹æ®èµç¨å®æåå¸å¹¶ç¨äºææèµçè¯ååæåãå¼å¾æ³¨æçæ¯ï¼ç»ç»è
å°ä¸æä¾è³æºçè¿åºé³é¢ã转å½ä»¥åçå®æ¶é´æ³ã主åæ¹å°ä¸åæä¾æ¯ä¸ªè¯´è¯äººççå®æ¶é´æ³ï¼èæ¯å¨Test-2023éä¸æä¾å
å«å¤ä¸ªè¯´è¯äººçç段ãè¿äºç段å¯ä»¥éè¿ä¸ä¸ªç®åçvad模åè·å¾ã |
|---|
| | | |
|---|
| | | ## è¯ä¼°æ¹æ³ |
|---|
| | | 使ç¨ä¸²èæä¼æåºå符é误çï¼cpCERï¼ææ æ¥è¯ä¼°è¯´è¯äººç¸å
³çASRç³»ç»çåç¡®æ§ãcpCERç计ç®å
æ¬ä¸ä¸ªæ¥éª¤ãé¦å
ï¼å°ä¸åºä¼è®®ä¸æ¯ä¸ªè¯´è¯äººçåèåå设转å½ææ¶é´é¡ºåºä¸²èèµ·æ¥ãå
¶æ¬¡ï¼è®¡ç®çå®æ ç¾åé¢æµè¾åºä¹é´çå符é误çï¼CERï¼ï¼å¹¶å¯¹ææå¯è½ç说è¯äººæåç»åéå¤è¿ä¸è¿ç¨ãæåï¼éæ©CERæä½çæåç»åä½ä¸ºè¯¥æ¶æ®µçcpCERãCERæ¯éè¿å°ASRè¾åºè½¬å为åèææ¬æéçæå
¥ï¼Insï¼ãæ¿æ¢ï¼Subï¼åå é¤ï¼Delï¼çå符æ»æ°é¤ä»¥åèææ¬çå符æ»æ°å¾å°çãå
·ä½æ¥è¯´ï¼CERç计ç®æ¹æ³æ¯ï¼ |
|---|
| | | |
|---|
| | | $$ \text{CER} = \frac {\mathcal N_{\text{Ins}} + \mathcal N_{\text{Sub}} + \mathcal N_{\text{Del}} }{\mathcal N_{\text{Total}}} \times 100\%, $$ |
|---|
| | | |
|---|
| | | å
¶ä¸ $\mathcal N_{\text{Ins}}$ , $\mathcal N_{\text{Sub}}$ , $\mathcal N_{\text{Del}}$ æ¯ä¸ç§é误çå符æ°, $\mathcal N_{\text{Total}}$ æ¯å符æ»æ°. |
|---|
| | | ## åèµé设置 |
|---|
| | | ### åèµéä¸ (éå®è®ç»æ°æ®): |
|---|
| | | åä¸è
åªè½ä½¿ç¨éå®æ°æ®æ建两个系ç»ï¼ä¸¥ç¦ä½¿ç¨é¢å¤æ°æ®ãåèµè
å¨ç³»ç»æ建è¿ç¨ä¸ä»
è½ä½¿ç¨AliMeetingãAISHELL-4åCN Celebãåèµè
å¯ä»¥ä½¿ç¨[Hugging Face](https://huggingface.co/models)以å[ModelScope](https://www.modelscope.cn/models)ä¸æä¾çå¼æºé¢è®ç»æ¨¡åï¼å¹¶ä¸éè¦å¨æç»çç³»ç»æè¿°ææ¡£ä¸è¯¦ç»ååºä½¿ç¨çé¢è®ç»æ¨¡åå称以åé¾æ¥ã |
|---|
| | | ### åèµéäº (å¼æ¾è®ç»æ°æ®): |
|---|
| | | é¤äºéå®æ°æ®å¤ï¼åä¸è
å¯ä»¥ä½¿ç¨ä»»ä½å
¬å¼å¯ç¨ãç§äººå½å¶å模æ仿ççæ°æ®éãä½æ¯ï¼åä¸è
å¿
é¡»æ¸
æ¥å°ååºä½¿ç¨çæ°æ®ãå¦æ使ç¨æ¨¡æ仿çæ°æ®ï¼è¯·è¯¦ç»æè¿°æ°æ®æ¨¡æçæ¹æ¡ã |
|---|





{kind=link}
{kind=link}
{kind=link}
{kind=link}